Par Haitam BENKADDOUR, Tommy-Lee BERNARD, Quentin BLANCHET, Loan VILLEMIN, Myriam YEROU, élèves ingénieurs du parcours Data Science à IMT Atlantique.
Une problématique cruciale dans le football moderne
Aujourd’hui le football fait face à une crise liée à un calendrier de matchs de plus en plus dense et aux blessures qui en découlent. La FIFPRO, le syndicat mondial des joueurs, tire la sonnette d’alarme : lors de la saison 2020-2021, 72% des footballeurs professionnels dans le monde ont dépassé le seuil critique de 55 rencontres par saison, un niveau qui met en danger leur intégrité physique.
Cette problématique est d’autant plus critique que les calendriers continuent de se densifier, augmentant les risques de blessures et impactant directement la performance des équipes.
Quelques chiffres-clés illustrant l’ampleur du problème

Plus de 7 joueurs sur 10 ont dépassé le seuil critique de matchs par saison.

Le coût moyen des blessures pour un club de Premier League est de 45 millions de livres par saison./images/image7.png)

Augmentation de 20% des blessures musculaires entre 2016 et 2023 dans les 5 grands championnats européens.

82% des joueurs pensent que le calendrier actuel a un impact négatif sur leur santé physique et mentale.
Sources : FIFPRO Player Workload Report, UEFA Elite Club Injury Study, Premier Injuries Annual Report.
La solution : l’analyse de données au service de la récupération physique
Notre approche se fonde sur l’analyse de données pour aider les préparateurs physiques à aménager les entraînements et les temps de récupération des joueurs, afin de prévenir les blessures. Nous avons exploité trois jeux de données complémentaires:
- Performances en match : nombre de minutes jouées, nombre de matchs disputés, statistiques individuelles (sprints, dribbles, buts, etc.).
- Blessures : dates de début et de fin des blessures, leur nature et nombre de matchs manqués.
- Caractéristiques des joueurs : taille, poids, date de naissance, poste.
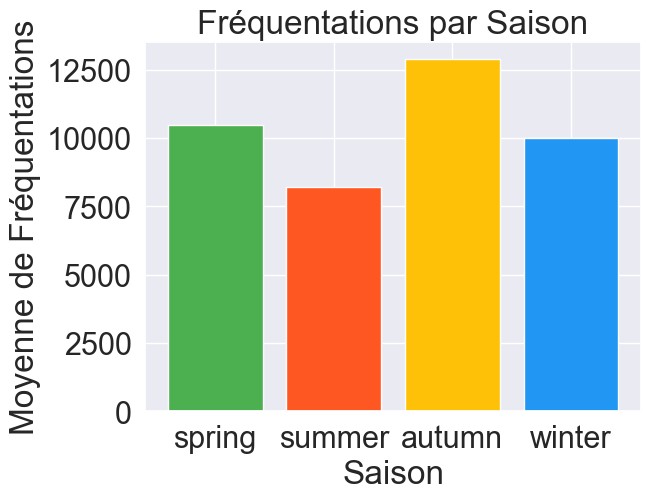
Ces données, regroupant 5097 joueurs sur 4 saisons des 5 grands championnats européens, nous ont permis d’identifier les facteurs de risques et de développer des modèles prédictifs. Nous avons constaté un volume élevé de blessures mensuelles, avec environ 4000 blessures recensées sur notre échantillon (cf. Fig. 1).
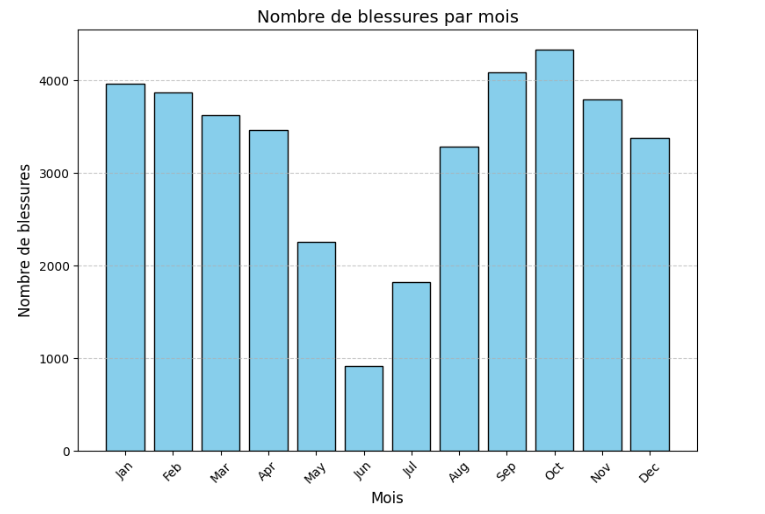
Grâce à notre analyse exploratoire des données, nous avons constaté un déséquilibre entre nos classes.
Transformer les données brutes pour prévenir les blessures
L’objectif de notre projet est d’identifier les facteurs clés liés aux blessures et de développer un modèle prédictif capable d’anticiper les risques de blessure dans les 30 prochains jours. Pour cela, nous avons créé de nouvelles variables:
- Temps écoulé depuis la dernière blessure
- Nombre de matchs joués sur différentes périodes (7, 30, 90, 365 jours)
- Nombre de matchs consécutifs
- Nombre de blessures par type
- Intensité des matchs
- Âge et IMC du joueur
Traitement des données : les valeurs extrêmes et les valeurs manquantes ont été gérées pour optimiser l’identification des patterns.
Suppression de données : les jeunes joueurs avec peu de minutes jouées, sans historique de blessures, ont été retirés des datasets.
Gestion des joueurs sans blessures : pour les joueurs sans blessures mais avec suffisamment d’informations, la variable « Temps écoulé depuis la dernière blessure » a été attribuée avec un temps maximum.
L’approche : des modèles de classification pour anticiper les risques
Dans le monde du sport professionnel, chaque blessure peut avoir des conséquences majeures : absence prolongée des joueurs, impact sur les performances de l’équipe, et coûts élevés pour les clubs. Mais imaginez si l’on pouvait prédire ces risques avant qu’ils ne se produisent ?
C’est précisément l’objectif de notre démarche : utiliser des modèles d’intelligence artificielle pour analyser les données des joueurs et anticiper leurs risques de blessures.
Nous avons testé plusieurs algorithmes de classification supervisée:
- Régression logistique
- Classificateur Naive Bayes
- Random Forests
- XGBoost
- SVM
Résultats et choix du modèle : XGBoost, le champion de la prédiction des blessures.
Après une évaluation rigoureuse, le modèle XGBoost optimisé avec Grid Search s’est avéré le plus performant, avec une accuracy de 70% et une surface sous la courbe AUC-ROC de 0.78 (cf. Fig. 2). Il est de plus bien adapté aux classes déséquilibrées.
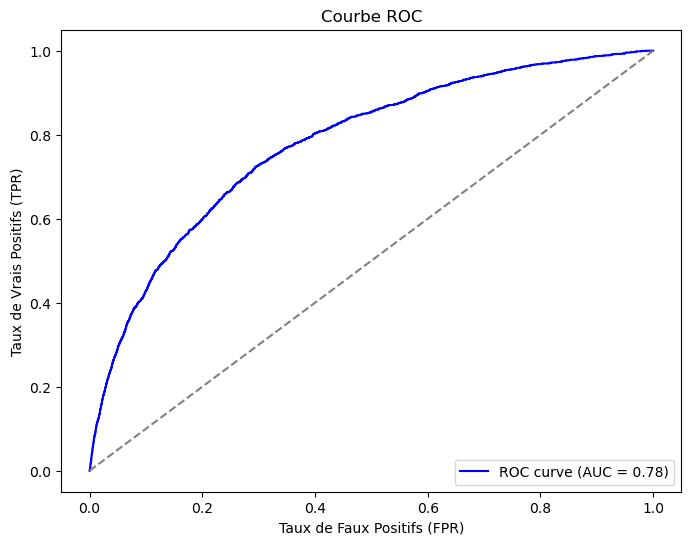
Ce modèle offre la meilleure capacité de détection des joueurs à risque de blessure. De plus, les joueurs en bonne santé ne sont pas faussement classés comme blessés.
Impacts et recommandations : protéger les joueurs, améliorer la performance
Notre modèle permet d’anticiper les risques de blessure, offrant ainsi aux préparateurs physiques un outil précieux pour optimiser la gestion des joueurs. Voici quelques recommandations clés fondées sur nos analyses:
- Limiter la charge cumulée de jeu (par exemple, 200 minutes sur 7 jours)
- Garantir un repos minimum de 48 heures entre 2 matchs intenses
- Planifier les rotations en fonction des charges cumulées et des prévisions de risques
Ainsi, l’utilisation de notre modèle XGBoost permet un gain de 5% dans la détection des blessures, sans pour autant augmenter le nombre de faux positifs, ce qui préserve l’effectif disponible pour l’entraîneur.
Perspectives d’amélioration : vers une prédiction encore plus fine
Bien que notre modèle soit performant, des améliorations sont possibles. Il serait intéressant d’intégrer davantage de données, comme :
- Les conditions météorologiques, le type de terrain
- Le niveau de stress des joueurs, leur nutrition, les antécédents de blessures
- Les données d’entraînement et de récupération
- Le style de jeu des équipes adverses
Nous envisageons également d’implémenter des modèles plus adaptés au déséquilibre des classes, comme les réseaux de neurones. Le développement d’une interface visuelle pour faciliter l’interprétation des risques est aussi une priorité.
Conclusion : un avenir plus sûr et plus performant pour le football
Notre projet démontre comment la data science peut révolutionner le football professionnel en permettant une meilleure anticipation des blessures et une optimisation de la gestion des joueurs. L’algorithme XGBoost développé s’est avéré être un outil précieux pour prédire les risques de blessures avec une amélioration de 5% par rapport aux méthodes existantes.
En intégrant davantage de données et en collaborant étroitement avec les acteurs du football, nous pouvons bâtir un avenir où les joueurs seront mieux protégés et les équipes plus performantes.
Références
- FIFPRO Player Workload Report
- UEFA Elite Club Injury Study
- Premier Injuries Annual Report
- La prédiction des blessures en sport : fiction ou réalité ? Sport injury prediction: Fiction or reality?
- La prévention des blessures sportives : modèles théoriques et éléments-clés d’une stratégie efficace – ScienceDirect