Une problématique cruciale dans le football moderne
Aujourd’hui le football fait face à une crise liée à un calendrier de matchs de plus en plus dense et aux blessures qui en découlent. La FIFPRO, le syndicat mondial des joueurs, tire la sonnette d’alarme : lors de la saison 2020-2021, 72% des footballeurs professionnels dans le monde ont dépassé le seuil critique de 55 rencontres par saison, un niveau qui met en danger leur intégrité physique.
Cette problématique est d’autant plus critique que les calendriers continuent de se densifier, augmentant les risques de blessures et impactant directement la performance des équipes.
Quelques chiffres-clés illustrant l’ampleur du problème
Plus de 7 joueurs sur 10 ont dépassé le seuil critique de matchs par saison.
Le coût moyen des blessures pour un club de Premier League est de 45 millions de livres par saison.
Augmentation de 20% des blessures musculaires entre 2016 et 2023 dans les 5 grands championnats européens.
82% des joueurs pensent que le calendrier actuel a un impact négatif sur leur santé physique et mentale.
Sources : FIFPRO Player Workload Report, UEFA Elite Club Injury Study, Premier Injuries Annual Report.
La solution : l’analyse de données au service de la récupération physique
Notre approche se fonde sur l’analyse de données pour aider les préparateurs physiques à aménager les entraînements et les temps de récupération des joueurs, afin de prévenir les blessures. Nous avons exploité trois jeux de données complémentaires:
Performances en match : nombre de minutes jouées, nombre de matchs disputés, statistiques individuelles (sprints, dribbles, buts, etc.).
Blessures : dates de début et de fin des blessures, leur nature et nombre de matchs manqués.
Caractéristiques des joueurs : taille, poids, date de naissance, poste.
Ces données, regroupant 5097 joueurs sur 4 saisons des 5 grands championnats européens, nous ont permis d’identifier les facteurs de risques et de développer des modèles prédictifs. Nous avons constaté un volume élevé de blessures mensuelles, avec environ 4000 blessures recensées sur notre échantillon (cf. Fig. 1).
Fig. 1 : Graphique du nombre de blessures par mois
Grâce à notre analyse exploratoire des données, nous avons constaté un déséquilibre entre nos classes.
Transformer les données brutes pour prévenir les blessures
L’objectif de notre projet est d’identifier les facteurs clés liés aux blessures et de développer un modèle prédictif capable d’anticiper les risques de blessure dans les 30 prochains jours. Pour cela, nous avons créé de nouvelles variables:
Temps écoulé depuis la dernière blessure
Nombre de matchs joués sur différentes périodes (7, 30, 90, 365 jours)
Nombre de matchs consécutifs
Nombre de blessures par type
Intensité des matchs
Âge et IMC du joueur
Traitement des données : les valeurs extrêmes et les valeurs manquantes ont été gérées pour optimiser l’identification des patterns.
Suppression de données : les jeunes joueurs avec peu de minutes jouées, sans historique de blessures, ont été retirés des datasets.
Gestion des joueurs sans blessures : pour les joueurs sans blessures mais avec suffisamment d’informations, la variable « Temps écoulé depuis la dernière blessure » a été attribuée avec un temps maximum.
L’approche : des modèles de classification pour anticiper les risques
Dans le monde du sport professionnel, chaque blessure peut avoir des conséquences majeures : absence prolongée des joueurs, impact sur les performances de l’équipe, et coûts élevés pour les clubs. Mais imaginez si l’on pouvait prédire ces risques avant qu’ils ne se produisent ?
C’est précisément l’objectif de notre démarche : utiliser des modèles d’intelligence artificielle pour analyser les données des joueurs et anticiper leurs risques de blessures.
Nous avons testé plusieurs algorithmes de classification supervisée:
Régression logistique
Classificateur Naive Bayes
Random Forests
XGBoost
SVM
Résultats et choix du modèle : XGBoost, le champion de la prédiction des blessures.
Après une évaluation rigoureuse, le modèle XGBoost optimisé avec Grid Search s’est avéré le plus performant, avec une accuracy de 70% et une surface sous la courbe AUC-ROC de 0.78 (cf. Fig. 2). Il est de plus bien adapté aux classes déséquilibrées.
Fig. 2 : Courbe ROC pour XGBoost avec GridSearch
Ce modèle offre la meilleure capacité de détection des joueurs à risque de blessure. De plus, les joueurs en bonne santé ne sont pas faussement classés comme blessés.
Impacts et recommandations : protéger les joueurs, améliorer la performance
Notre modèle permet d’anticiper les risques de blessure, offrant ainsi aux préparateurs physiques un outil précieux pour optimiser la gestion des joueurs. Voici quelques recommandations clés fondées sur nos analyses:
Limiter la charge cumulée de jeu (par exemple, 200 minutes sur 7 jours)
Garantir un repos minimum de 48 heures entre 2 matchs intenses
Planifier les rotations en fonction des charges cumulées et des prévisions de risques
Ainsi, l’utilisation de notre modèle XGBoost permet un gain de 5% dans la détection des blessures, sans pour autant augmenter le nombre de faux positifs, ce qui préserve l’effectif disponible pour l’entraîneur.
Perspectives d’amélioration : vers une prédiction encore plus fine
Bien que notre modèle soit performant, des améliorations sont possibles. Il serait intéressant d’intégrer davantage de données, comme :
Les conditions météorologiques, le type de terrain
Le niveau de stress des joueurs, leur nutrition, les antécédents de blessures
Les données d’entraînement et de récupération
Le style de jeu des équipes adverses
Nous envisageons également d’implémenter des modèles plus adaptés au déséquilibre des classes, comme les réseaux de neurones. Le développement d’une interface visuelle pour faciliter l’interprétation des risques est aussi une priorité.
Conclusion : un avenir plus sûr et plus performant pour le football
Notre projet démontre comment la data science peut révolutionner le football professionnel en permettant une meilleure anticipation des blessures et une optimisation de la gestion des joueurs. L’algorithme XGBoost développé s’est avéré être un outil précieux pour prédire les risques de blessures avec une amélioration de 5% par rapport aux méthodes existantes.
En intégrant davantage de données et en collaborant étroitement avec les acteurs du football, nous pouvons bâtir un avenir où les joueurs seront mieux protégés et les équipes plus performantes.
Les transports en commun sont aujourd’hui parmi les principaux moyens de transports quotidiens en France. Aujourd’hui, 22% de la population française utilise les transports en commun dans leurs trajets quotidiens [1].
Comment pouvons nous rendre plus agréable ces trajets quotidiens et améliorer la vie de plus d’1/5 des français ?
Un besoin de visibilité sur le réseau
En interrogeant les utilisateurs des réseaux de transports en communs en France [2], il apparaît que ceux-ci aimerait en priorité des transports plus fréquents (Fig.1).
Fig. 1 Les avantages des transports publics selon les Français en 2022 [2].
Cependant, il est préférable pour les gestionnaires de réseaux d’allouer plus de transports lorsqu’ils en ont vraiment besoin, comme lors de fortes variations de fréquentation. Au-delà des variations dues à l’heure ou au jour, la météo pourrait être un facteur influençant la fréquentation des transports en commun. On s’imagine facilement que lors d’un jour pluvieux par exemple, des personnes se rendant normalement au travail à pied préfèrent le bus ou le métro. Rennes étant une ville assez pluvieuse et dont les données du réseau régi par l’entreprise STAR sont accessibles librement, ce sera sur cette ville que nous explorerons cette idée.
Nous cherchons donc à fournir à l’entreprise STAR à Rennes des prédictions de variation de fréquentation en prenant en compte les données météos pour que celle-ci adapte le nombre de transport en conséquence.
Des variations de fréquentation saisonnières
Pour répondre à notre problème, il nous faut donc tout d’abord des données sur la fréquentation des lignes du réseau STAR. Nous nous procurons sur le site de STAR une base de données de fréquentation relevée toutes les 15 min [3]. Il nous faut en effet des relevés assez fréquents pour prédire la fréquentation à des heures précises et pouvoir adapter le nombre de transports en conséquence plus précisément.
En analysant ces données, on voit apparaître des tendances saisonnières sur la fréquentation du réseau. On remarque notamment des différences en fonction de la saison (Fig.2) ou de l’heure (Fig.3). On observe aussi évidemment une baisse de fréquentation le week-end et les jours de vacances scolaires.
Fig. 2 : Moyenne de fréquentation par saison
Fig. 3 Fréquentation moyenne sur une journée
Pour savoir sur quelle ligne de transport il serait le plus nécessaire de moduler le nombre de transports en fonction de la fréquentation, on affiche les variations de fréquentation maximales par ligne (Fig.4) calculées par rapport à des fréquentations moyennes sur les différentes périodes. On voit bien que les variations les plus importantes du nombre de passagers se situent sur le métro a. Ajoutez à ça que cette ligne est automatique, celle-ci apparaît comme la candidate parfaite pour notre étude. On ne s’intéresse donc maintenant qu’à cette ligne dans la prédiction de la variation de fréquentation en fonction de la météo. Mais pour cela, il nous faut des relevés de météo.
Fig. 4 : Variation maximale de fréquentation par ligne
Une multitude de données météo
Nous trouvons un dataset Météo France [4] qui nous fournit des relevés horaires d’une station proche de Rennes. Ces mesures vont de la température à l’humidité en passant par la puissance du vent.
On s’assure rapidement que nos données sont cohérentes et que l’on utilise pas un jeu de données complètement faux avant de relier ces données météo à nos données de fréquentations.
Qu’en est-il du lien entre fréquentation et météo ?
Pour analyser le lien entre la météo et la fréquentation, on regroupe nos deux jeux de données en un plus grand dans lequel on associe pour chaque heure de chaque jour les relevés météo et la fréquentation associés.
On calcule alors des coefficients de corrélation entre la fréquentation et les données météos. Nous ne trouvons aucune variable météo qui expliquerait seule les variations de fréquentation, mais certaines valeurs de corrélations non négligeables nous laissent présager que l’association de toutes les données météos pourrait nous permettre de prédire efficacement ces variations.
Cependant, aucun lien n’apparaît entre nos données météo et la variation de fréquentation. Ainsi, nous décidons de prédire premièrement la fréquentation grâce aux données météos, puis nous calculons la variation de fréquentation en comparant la valeur de fréquentation et la valeur moyenne de fréquentation associée.
Comment prédire ces fréquentations ?
Nous essayons de prédire une variable cible : la fréquentation. Pour cela nous utiliserons donc un algorithme d’apprentissage supervisé qui prendra la forme d’un modèle de régression.
Un algorithme d’apprentissage supervisé s’entraîne, sur des données collectées, à prédire la variable cible à partir d’autres variables, dans notre cas les relevés météos. Il ajuste son fonctionnement au cours de l’apprentissage pour améliorer ses prédictions. Il peut lui-même savoir s’il se trompe ou non car il peut comparer sa prédiction avec la réponse attendue qui est comprise dans le jeu de données.
Un modèle de régression est simplement un algorithme qui prédit une valeur numérique (qui peut prendre n’importe quelle valeur). C’est l’opposé d’un modèle de classification qui prédit une valeur parmi un ensemble de plusieurs valeurs définies (chaque valeur étant associée à une classe)
Il existe une multitude d’algorithmes d’apprentissage supervisé utilisables pour faire de la régression. Nous devons donc tous les tester pour choisir le meilleur qui sera choisi comme algorithme final.
Est-ce que ces modèles sont performants ?
On compare premièrement la performance des différents modèles de prédiction sur une petite partie des nos données, appelée échantillon de validation. Le modèle le plus performant est le Gradient Boosting. Nous le choisissons donc comme notre algorithme final. Cet algorithme a un fonctionnement assez simple : il corrige petit à petit son erreur de prédiction par rapport à la valeur qu’il aurait dû trouver. Il estime à chaque itération cette erreur et la retire au résultat final, d’où son utilité dans notre cas d’une valeur continue.
Nous entraînons notre modèle final avec le reste de nos données, tout en gardant une petite partie de nos données restantes comme échantillon de test. Ce dernier nous permet alors d’obtenir la performance de notre modèle final sur des données qu’il n’a jamais rencontrées et à savoir si celui-ci pourra être utile à l’entreprise STAR.
Un des scores nous permettant d’évaluer la performance de notre modèle est la MAE ou Mean Absolute Error. Cette valeur est simplement l’erreur moyenne de notre modèle. Nous trouvons une valeur de 668. Ainsi, notre modèle se trompe en moyenne de 668 personnes quand il prédit la fréquentation sur la ligne a. Cette valeur peut paraître énorme, mais elle est un peu plus acceptable quand on la compare avec la fréquentation moyenne qui est autour de 10 000. Mais, notre modèle n’a au final pas l’air d’être assez performant pour imaginer qu’il serait utile à l’entreprise STAR.
Un modèle non déployable en l’état
En creusant un peu plus, on se rend compte que ces erreurs ne sont pas du tout négligeables à côté des valeurs de variations de fréquentation. Dans ces conditions, il n’est pas envisageable que ces prédictions soient utilisées pour modifier le nombre de rames lorsque ces mêmes prédictions se trompent en moyenne d’autant que la variation de fréquentation pour la période donnée. L’entreprise STAR serait alors amenée à ajouter des rames en prévision d’une variation qui n’existe pas, ou au contraire de ne pas rajouter de rames là où le modèle n’a pas réussi à anticiper une variation de fréquentation.
Nous pouvons envisager d’améliorer notre modèle pour prédire plus précisément les variations de fréquentations en cherchant des facteurs supplémentaires pouvant influencer la fréquentation du métro a, ou encore améliorer l’approximation des moyennes de fréquentation par période (et donc des variations de fréquentation) par une analyse des tendances saisonnières plus poussée.
Avec un taux de criminalité de 33 pour mille habitants et plus de 8 millions de crimes enregistrés depuis 2001, Chicago figure parmi les villes les plus touchées par la criminalité en Amérique.
Quels facteurs influencent la criminalité dans cette métropole ?
Inspiré par des recherches analysant la relation entre l’éducation et la criminalité notre projet explore l’influence des écoles sur la sécurité urbaine.
Répartition géographique des écoles et des incidents criminels à Chicago – Source des données : Chicago Data Portal
Des études au préalables ont montré que les caractéristiques des écoles, telles que les activités parascolaires, la nature de l’école et les heures de cours, peuvent avoir un impact significatif sur la délinquance et la criminalité indépendamment du contexte social et démographique.
Notre objectif est de développer un modèle de Machine Learning prédictif qui évalue l’impact potentiel de la construction des nouvelles écoles sur le taux de criminalité sur une période de sept ans, offrant ainsi des perspectives innovantes afin d’explorer comment l’éducation peut influencer la sécurité urbaine à Chicago.
Données utilisées
Répartition géographique des écoles et le rayon d’impact des incidents criminels à Chicago – Source des données : Chicago Data Portal
Notre étude s’appuie sur des données publiques issues du Chicago Data Portal, qui est géré par la municipalité de la ville. Nous avons analysé sept jeux de données relatifs aux établissements scolaires de 2016 à aujourd’hui, ainsi qu’un jeu de données sur les crimes enregistrés de 2001.
L’objectif est d’évaluer l’impact des écoles sur le taux de criminalité dans un rayon de 1 km autour de celles-ci, sur une période allant jusqu’à sept ans.
Pour cela, nous avons créé des jeux de données croisés permettant d’analyser l’évolution annuelle de la criminalité par rapport à l’année de référence 2016 :
Dataset 1 : écoles 2016 ↔ crimes 2017
Dataset 2 : écoles 2016 ↔ crimes 2018
Dataset 3 : écoles 2016 ↔ crimes 2019
Dataset 4 : écoles 2016 ↔ crimes 2020
Dataset 5 : écoles 2016 ↔ crimes 2021
Dataset 6 : écoles 2016 ↔ crimes 2022
Dataset 7 : écoles 2016 ↔ crimes 2023
Regardons les données de plus près : Analyse des corrélations
Matrice de corrélation des variables du jeu de données fusionné
Pour résumer les corrélations des données analysées, nous pouvons dire que les corrélations entre les variables étudiées et le taux de criminalité sont relativement faibles.
Cela confirme l’hypothèse selon laquelle le taux de criminalité est influencé par une multitude de facteurs autres que les seules politiques internes des écoles.
Toutefois, il semble exister une association plus marquée entre la présence d’écoles dans un quartier, le nombre d’étudiants, et le taux de criminalité plutôt qu’avec les caractéristiques propres à chaque établissement scolaire.
Construction du modèle
Algorithmes utilisés
Nous avons utilisé plusieurs modèles, y compris le Random Forest, SVM et des variantes de Boosting, pour identifier ceux qui prévoient le mieux les taux de criminalité future.
Les modèles les plus performants, jugés sur la base de leur erreur moyenne absolue (MAE) et de l’erreur quadratique moyenne (RMSE), ont été combinés pour créer un modèle composite robuste.
Ce modèle est adapté pour prédire l’évolution de la criminalité sur une période allant jusqu’à sept ans.
Validation
Pour garantir la fiabilité de nos modèles prédictifs, nous avons mis en place une validation croisée sur les modèles, chacun comprenant environ 655 lignes.
Cette technique permet de s’assurer que nos algorithmes généralisent bien au-delà des données d’entraînement et ne mémorisent pas simplement les données (overfitting).
Les résultats de cette validation croisée ont confirmé l’efficacité de nos modèles, avec une diminution des erreurs.
L’analyse de l’importance des variables, issue de nos modèles et tenant compte des corrélations limitées, révèle que la :
le taux de criminalité est davantage lié à la proximité des établissements scolaires qu’à leurs politiques internes comme les codes vestimentaires ou les programmes parascolaires.
Cette divergence par rapport aux articles identifiés souligne l’importance de prendre en compte le contexte local de chaque zone, avec les différents indicateurs démographiques.
Résultats ? Notre modèle offre une double fonctionnalité
Prédit l’évolution du taux de criminalité sur sept ans en se basant sur les données actuelles des écoles. Ainsi, il est capable de projeter l’incidence criminelle de 2024 à 2030 en utilisant les informations de 2023.
2. Simule l’effet de l’ajout d’une nouvelle école dans une zone spécifique (Latitude et longitude) et évalue l’impact sur la criminalité dans un rayon de 1 KM de l’école et les écoles à côté (en se concentrant sur les intersections des cercles).
Le modèle nous permet aussi de faire une comparaison de la situation des crimes avec et sans l’introduction d’une école avec des critères spécifique dans une zone donnée .
Nos simulations révèlent que l’extension des programmes parascolaires peut diminuer l’impact sur le taux de criminalité environnant.
Conclusion
Les résultats obtenus à travers notre modèle fournissent une base solide pour les décideurs locaux de Chicago afin de prendre des décisions en ce qui concerne la construction d’écoles dans des zones spécifiques.
Notre analyse a révélé aussi que l’impact des écoles sur la criminalité locale est complexe et ne repose pas uniquement sur les programmes éducatifs, soulignant l’importance d’intégrer d’autres facteurs lors de la planification de nouvelles infrastructures éducatives (postes de polices, état du quartier …) et de prendre en considération les indicateurs démographiques, la situation financière des étudiants recrutés par chaque école pour plus d’alignement avec les articles sur lesquels nous avons basés nos hypothèses..
Les insights fournis par notre étude offrent des pistes prometteuses pour des stratégies urbaines plus éclairées. Pour aller de l’avant, il serait judicieux d’envisager une approche collaborative impliquant éducateurs, autorités locales, et communautés pour bâtir un environnement plus sûr. Finalement, cette recherche ouvre la voie à des études supplémentaires qui pourraient explorer des interventions ciblées et personnalisées, contribuant ainsi à la transformation positive de Chicago.
Références
Crews, G. (2009). Education and crime. In J. M. Miller 21st Century criminology: A reference handbook (pp. 59-66). SAGE Publications, Inc., https://www.doi.org/10.4135/9781412971997.n8
Gottfredson et al., (2004). « Do After School Programs Reduce Delinquency? »
Willits, Broidy, et Denman, « Schools, Neighborhood Risk Factors, and Crime ».
As we travel through the Earth, we can notice the symphony we hear all around, from the smallest grain of sand, to the faraway planets, to a flower putting roots in the ground, every bird in the sky, every rock, and every raindrop as it falls from the clouds, every ant, every plant, every breeze, and all the seas contribute to this beautiful composition. However, within this natural orchestra, there’s a dangerous problem that demands our attention — ‘Global Warming’.
With the variation of the temperature over recent decades, the agriculture is considered as one of the most affected sectors by global warming. These environmental changes have disrupted the agricultural landscape, affecting both its ecology and economy.
Describing the impact of global warming on agriculture is a bit like exploring a big, diverse world map. Each country in this map has its own distinct climate, crops, and economic structures. This diversity is what makes our world interesting but also makes problem-solving a bit challenging.
This is where the idea of assessing vulnerability for countries takes center stage. Consider Vulnerability as a measure of how susceptible a country is to the challenges posed by global warming in the sector of agriculture.
Some countries may be more resilient, while others may face high risks due to their specific circumstances which make them vulnerable countries. Our challenge: predict the vulnerability of the countries by 2030.
Given the crucial role of non-governmental organizations (NGOs) to address the effects of global warming on agriculture, our primary focus goes beyond identifying the most vulnerable countries, we aim to predict this vulnerability by the year 2030 and foresee the difficulties before they happen. In that way, we can empower NGOs with pivotal information that may serves as initiatives for them to take action and tailor solutions and strategies before the things get too hard for vulnerable countries.
A data-driven definition of Vulnerability
To achieve this ambitious goal, we delved into the world of data. This exploration involves carefully choosing our data from a reliable, open- data source: ‘Food and Agriculture Organization of the United Nations’. We focus on Geography and Economics data, Environment Temperature Changes Data and Agriculture (Crop Yield) Data.
Geography and Economics data1: it underscores information related to percentage of the country area cultivated, Gross Domestic product (GDP), agriculture’s GDP contribution, total renewable water resources, and the national rainfall Index.
Environment Temperature Change Data2: it focuses on temperature change factor for different countries.
Agriculture (Crop Yields) Data3: it involves the production values for specific crop yields. All our datasets are meticulously organized, categorized by country and year.
Inspired by cutting-edge research45, we’ve strategically organized our variables into three main components. Each component serves as a building block for our mission to assess vulnerability in the face of global warming’s impact on agriculture. Let’s delve into these components:
Exposure: How much the country is exposed to different climatic factors.
Sensitivity: How sensitive the agriculture in the area is to certain risks.
Adaptive Capacity: How well the area can adapt to and cope with the challenges posed by global warming.
We then attribute each variable to one of those three components as well as adding new variables to enhance our understanding.
Data Preparation
We started by preparing our datasets and transform them into refined insights in order to make them ready for future work.
Rename the countries and matching them: We begin by renaming and identifying matching countries across all datasets. This is a foundational step when merging all the datasets together.
Handling Missing Data: We address missing data using advanced techniques. The power of KNN imputation or zero imputation comes into play, ensuring our datasets are robust and comprehensive.
Creating New Variables: we succeeded to create new variables as outlined in the data organizing phase. This step play an important role in shaping our analysis.
Data Integration: Merging datasets together seamlessly, we ensure a unified view that enhances the effectiveness of our analysis.
Data Normalization: Recognizing the diverse nature of our variables, we implement normalization techniques for both positive and negative variables. Positive variable indicates a positive relation with vulnerability, while negative variable signify a negative relation. This step ensures fair treatment of climate and agriculture variables for accurate vulnerability assessment.
Assessing Global Vulnerability: How does it Work?
Since our goal is to identify the vulnerable countries in the face of global warming’s impact on the agriculture by 2030, we embark in another journey that requires a deep comprehensive of methodologies for calculating vulnerability, making predictions and providing insightful vulnerability classifications.
Our proposal: a Vulnerability index
The key concept of assessing vulnerability of the countries was to create a new variable called ‘Vulnerability index’(VI). This calculation of this variable is based on two main approach that are taken from two innovative research.
As we organized our variables into three main components— Exposure(S), Sensitivity(S) and Adaptive Capacity (AC), we were seeking to calculate the vulnerability index by identifying the vulnerability of each component separately and than summing them up as illustrated in the figure. To achieve this, we assign weights to each variable attributed to one of these components. The weights represent the relative importance of each variable in the vulnerability index calculation.
We used two methods for assigning the weights: Equal weights method, where each variable is considered equally important and the Principle component Analysis (PCA) method, which involves mathematical techniques to capture the most critical information presenting in our data in a smaller set of components, then assigning weights based on the variables’ contribution to the first principal component. This dual-weighting strategy results in two different vulnerability indices: Equal -weights Vulnerability and Principle Component Analysis (PCA)- weights Vulnerability.
In contrast of the component-based approach, entropy-based approach simplifies the calculation of the Vulnerability Index by considering all the variables together. Measuring uncertainty and information content. The idea is to measure the uncertainty or information associated with each variable. This unique perspective on vulnerability, has a pivotal role in emphasizing variables that offer more certain and informative signals. We ended up after this approach, having Entropy-weights Vulnerability Index.
Making predictions
Having The three main Vulnrability indexes: Equal -weights Vulnerability and Principle Component Analysis (PCA)- weights Vulnerability and Entropy-weights Vulenrability, and recognizing the unique trajectories each country has followed, we decided to delve into the next phase: Prediction. In this step, we aim to predict our three vulnerability indices until the year 2030 by looking into the patterns and trends for each country. To achieve this, we used the ARIMA model, known as its suitability in short term-forecasting and capability in capturing temporal patterns8.
ARIMA model performance: negligible error values for all 3 indices
In order to evaluate the performance of the ARIMA model in making predictions for each of our vulnerability indices, we used the MEAN SQUARED ERROR (MSE) and MEAN ABSOLUTE ERROR (MAE) for evaluating our results. Thus, after exploring the results from the MSE measure from the figure below, we notice that the Entropy and PCA methods for calculating the vulnerability have a better performance than Equal Weights method. However, we can see that for all of those methods, we can consider that the error values are practically negligible.
Providing Vulnerability Classification
In this step, we looked forward to classify the countries based on the predictions’ values of each of their vulnerability indices. This involves categorizing countries based on their index values using the Percentile method. Countries below the 25th percentile of their vulnerability index is considered as Relatively non-vulnerable, those above the 75th percentile are considered as Relatively vulnerable , and the rest fall into Neutral Category. This classification provide us with a list of vulnerable countries for both 2020 and 2030 across all indices.
The figures above represent the vulnerable countries we got after extracting the common vulnerable countries from the classifications results of the three vulnerability indices. The countries in brown are the countries that remain vulnerable from 2020 to 2030, the red countries are the new countries that turn into vulnerable in 2030 and the green one is the country that improves its status from vulnerable to neutral by the year of 2030.
To see how the vulnerability index and the countries’ ranking have changed over years, we made an animated bar chart race to illustrate it. You can click here.
Turning Data into Action
As we navigate the impacts of global warming on agriculture, our journey has revealed insights into vulnerability across nations. We got a list of 24 vulnerable countries in 2020 and a list of 27 vulnerable countries in 2030 in which there are some countries that are going to be vulnerable in 2030 such as India, Nigeria, Tanzania and one country that will improve its status by the year of 2030: Brunei. With this information, we propose some strategies to the NGOs to take specific actions to support those countries indeed.
For those countries that remain vulnerable until 2030, NGOs can take some actions to improve their status by developing and implementing sustainable agriculture practices. This includes promoting efficient water management, soil conservation, and the adoption of climate-resilient crop varieties.
Countries that are going to be vulnerable by the year of 2030 need preemptive strategies. NGOs can collaborate to establish early-warning systems, support climate-smart agricultural practices, and facilitate knowledge exchange between nations that have successfully mitigated vulnerabilities. Moreover, NGOs can work on some factors in the Adaptive Capacity Components to avoid vulnerability like expanding cultivated areas, supporting population control measures, and boosting total production through research and innovation.
While our findings provide a valuable insights, acknowledging limitations is key. Expanding datasets, incorporating subjective insights, and focusing on specific crop vulnerabilities are our directions for future exploration. So let’s turn these improvements into actionable steps for a resilient and sustainable agricultural future.
Avec une population dépassant les 8 millions d’habitants, New York City se positionne parmi les villes les plus influentes en Amérique du Nord. Ville dynamique et en perpétuelle mutation, des réglementations ont été instaurées, restreignant le port d’armes à feu dans certaines zones. Néanmoins, ces mesures suscitent des débats au sein de la sphère politique de New York.
Cependant, malgré les restrictions, le nombre élevé de fusillades persiste au sein de la ville, avec plusieurs centaines d’incidents recensés au cours des dernières années. De plus, la constante évolution de la ville rend la planification urbaine de plus en plus complexe au fil du temps. Face à cette réalité, la problématique qui se pose est la suivante :
Peut-on améliorer la sécurité urbaine de New York City grâce à des initiatives d’urbanisation ?
Notre exploration de la littérature scientifique a rapidement corroboré l’existence de liens significatifs entre les crimes et les localisations, l’agencement et les types de bâtiments publics dans une zone donnée 1.
Guidés par cette idée, nous avons choisi d’apporter une solution à la problématique antérieure en exploitant nos compétences en science des données et en apprentissage automatique. L’objectif serait donc de pouvoir estimer l’impact de la construction de nouveaux bâtiments publics sur la criminalité environnante.
À la recherche d’indices
Pour répondre à notre problématique, nous sommes partis de deux jeux de données de la ville de New York. Le premier recense les fusillades dans la ville avec leurs localisations depuis 2006 et comporte un peu plus de 27 000 lignes 2. Le second nous donne accès aux plus de 30 000 bâtiments publics de la ville3 .
Nombre de tirs
Nombre de bâtiments publics
Les bâtiments sont regroupés selon 25 catégories différentes en fonction du domaine d’activité qui leur est lié : les plus nombreux sont ceux liés à l’enfance, aux transports et à la santé et les moins nombreux ceux liés aux télécommunications et à la justice. On peut observer ci-dessous quelle typologie de bâtiment est utilisée ainsi que le nombre de bâtiments de chaque type.
Répartition des types de bâtiments à New York
La tâche la plus dure à présent consiste à générer notre propre jeu de données pour établir les liens entre les bâtiments et les incidents de fusillade.
Comment lier nos indices entre eux ?
Pour cela, nous avons utilisé une approché basée sur les secteurs. Un secteur est une zone géographique dans laquelle nous recensons le nombre de chaque type de bâtiment ainsi qu’une mesure de la criminalité basée sur le nombre de fusillades.
Théoriquement, les secteurs peuvent adopter n’importe quelle forme, telle que celle des rectangles d’une grille par exemple, et possèdent une intersection qui peut être non-nulle : un chevauchement est donc possible.
Exemple de sectorisation (1304 secteurs de 1km x 1km)
Dans notre cas, nous avons utilisé des secteurs circulaires d’un rayon de 500 mètres, dont le centre est un bâtiment public de notre jeu de données Ainsi, pour chaque bâtiment nous obtenons un secteur : nous en avons donc au total plus de 30 000 ce qui sera très utile lors de l’entraînement des modèles.
La manière dont nous avons créé notre jeu de données est schématisée ci-dessous.
Méthode sectorisation circulaire
Dans le secteur centré autour de l’hôpital rouge, 5 tirs ont été tirés, dont 3 près d’une école, 1 près d l’hôpital, et 1 près du poste de police.
Sur cet exemple, nous avons additionné le nombre de tirs dans chaque secteur. En réalité, un traitement a été appliqué à ce nombre. En effet, plutôt que de parler en termes de nombre de tirs, ce qui est peu parlant – que signifierait “Placer un bâtiment ici a diminué le nombre de tirs de 2 sur 15 ans” ? – nous avons décidé de créer un indice évaluant la criminalité, basé sur le nombre de tirs.
Plus particulièrement, nous nous intéresserons à l’évolution de cet indice pour voir s’il est judicieux ou non d’implémenter un type de bâtiment public à un endroit donné : la différence entre avant et après la construction sera-t-elle positive ou négative ?
Pour cela, nous avons redimensionné la variable que nous cherchons à prédire (la mesure de criminalité) pour que ses valeurs soient comprises entre 0 et 1 de la manière suivante :
Appliquons cela à l’exemple vu précédemment. Il nous faut d’abord trouver les secteurs comportant le moins et le plus de tirs, correspondant donc respectivement à xmin et xmax de l’équation. Connaissant cela, nous pouvons maintenant appliquer la formule à toutes les valeurs.
Attribution de notre indice de criminalité à chaque secteur
Il nous semble important de mentionner pour les plus curieux d’entre vous que nous avons également choisi d’utiliser un index personnalisé de criminalité car il offre une adaptabilité et une possibilité d’affinement.
On pourrait donc pousser davantage notre réflexion et notre démarche en utilisant toutes ces données en pondérant notre index par le degré de gravité du crime. A titre d’exemple, un vol pourrait compter pour un facteur de 1 et un meurtre pour un facteur de 100.
Cependant, comment pouvons-nous être sûr de l’efficacité de notre outil ?
Élémentaire mon cher Watson
Pour valider la crédibilité de notre approche, nous allons avoir recours à un critère de réussite : si nous vérifions le critère alors notre approche sera considérée comme valide.
Comme critère de réussite, nous allons procéder à une comparaison avec une méthode dite élémentaire (ou naïve) de détermination de l’indice de criminalité. Cette dernière se contente de prédire pour chaque secteur la moyenne de l’indice de criminalité. Mathématiquement, cela donne :
Si l’on reprend l’exemple précédent, l’approche élémentaire devrait prédire :
Prédiction du modèle élémentaire sur notre exemple
Comme vous pouvez le constater, cette approche, plutôt médiocre, prédit des valeurs de l’indice de criminalité assez éloignées de la réalité.
Ainsi, si nous sommes plus performants que cette méthode simpliste, nous pouvons considérer que notre approche est fonctionnelle et peut donner lieu à une application concrète.
Pour y parvenir, nous avons sélectionné plusieurs métriques caractérisant l’erreur à minimiser, à savoir la MSE (Mean Square Error), la MAE (Mean Absolute Error) et la RMSE (Root Mean Square Error) ainsi qu’une métrique expliquant la qualité de notre modèle vis-à-vis de la variance, le R2 (R-Squared).
Par conséquent, en comparant ces métriques, nous serons en mesure de démontrer la supériorité de notre outil par rapport à la méthode naïve.
Le raisonnement
Nous avons implémenté différents modèles d’apprentissage automatique de régression pour pouvoir prédire l’indice de criminalité lors de la construction d’un nouveau bâtiment afin d’estimer l’impact sur la criminalité des nouvelles constructions.
Le but est donc, avec notre modèle, d’aider à la prise de décision les responsables de la planification urbaine de la ville de New York.
Nous nous sommes notamment penchés sur des Réseaux de Neurones et des Random Forest. Finalement notre choix s’est porté sur le Random Forest pour plusieurs raisons :
Premièrement, les résultats obtenus se sont révélés très prometteurs.
Ensuite, le temps d’exécution de notre algorithme restait raisonnable.
Enfin, cet algorithme nous permet d’avoir une vision plus précise de ce qui se passe avec notamment la possibilité de voir quelles données influencent le plus les prédictions, contrairement aux Neural Networks.
Le tableau ci-dessous nous montre bien les résultats obtenus à travers nos différents modèles. Nous remarquons aussi par ailleurs que nous validons largement notre critère de réussite.
Métriques
Random Forest
Neural Network
Modèle Naïf
MSE
0.00092
0.00340
0.02581
MAE
0.01519
0.04014
0.12742
R2
0.96446
0.86806
– 0.00005
RMSE
0.03029
0.05835
0.16067
Comparaison des modèles: toutes les métriques d’évaluation classent le Random Forest au premier rang
Graphique montrant l’importance de chaque feature pour notre modèle Random Forest
Comment résoudre l’enquête ?
Imaginons que vous êtes un planificateur urbain et que votre mission serait de construire une maison de jeu pour enfants.
Vous hésitez fortement entre 3 localisations que vous avez identifiées comme favorables selon des critères divers et variés.
Vous souhaitez prendre en compte l’impact de cette nouvelle construction sur la criminalité environnante ?
C’est ici que notre solution intervient.
Application du modèle sur 3 localisations réelles
Nos données nous fournissent l’indice de criminalité avant la construction, puis notre modèle prédit l’indice de criminalité après la construction de la maison de jeu pour enfants. Enfin, nous observons dans la dernière colonne ci-dessus l’évolution de cet indice de criminalité. Dans le cas présent la localisation C semble être le meilleur choix d’implantation si nous regardons le problème à travers le prisme de la criminalité.
Le verdict
Comme résultat, cet outil d’apprentissage automatique se positionne comme un allié de choix dans la prise de décision pour la planification urbaine à New York City, avec des performances élevées et aussi des opportunités d’amélioration.
Les résultats de l’évaluation de notre modèle, le RandomForest, ont surpassé nos attentes initiales. Sa précision remarquable dans la mesure de la criminalité, évaluée à travers les critères des erreurs à minimiser, ainsi que les indications détaillées sur l’importance de chaque caractéristique, confèrent à notre modèle une valeur exceptionnelle.
Cependant, il est essentiel de maintenir une approche prudente dans ce contexte. La planification urbaine est influencée par de multiples facteurs et ne peut se limiter à la seule considération de la criminalité. Par conséquent, bien que notre outil soit efficace, il doit être considéré comme une assistance à la prise de décision plutôt que comme une solution autonome pour les responsables de l’urbanisation.
Prise de recul
Malgré le succès évident de notre solution, nous sommes conscients de l’existence de tendances potentiellement risquées qui pourraient émerger en cas d’utilisation inappropriée de notre solution.
La première de ces tendances est la standardisation du type de construction à travers tous les secteurs, en se concentrant sur le type de construction ayant le plus grand impact sur l’indice de criminalité. Un certain point de saturation serait alors atteint, rendant notre modèle obsolète.
La seconde tendance impliquerait un déplacement à plus ou moins long terme de la criminalité. En effet, déplacer un problème vers une autre localisation ne le résout pas réellement. Cette réalité est malheureusement largement reconnue par ceux qui s’efforcent de réduire les taux de criminalité.
Et après ?
Plusieurs pistes d’amélioration ont été identifiées.
Diminution globale de la criminalité : Nous pourrions aller jusqu’à suggérer des emplacements d’implémentations de bâtiments publics plutôt que de simplement comparer des emplacements suggérés par les planificateurs urbains pour tenter de diminuer globalement la criminalité à New York.
Généralisation du modèle : l’intégration de jeux de données provenant d’autres villes nord-américaines pourrait enrichir notre modèle, entraînant ainsi une amélioration de ses performances et rendant la généralisation à la plupart des grandes villes américaines possible.
Amélioration des performances : la littérature suggère des liens significatifs entre la criminalité et le mouvement de population dans un secteur donné, rendant l’accès à des données de flux particulièrement valorisant.
Amélioration des performances et déplacement de la criminalité : l’inclusion d’informations sur l’année de construction des bâtiments permettrait d’apporter une dimension temporelle à notre modèle, gagnant ainsi en efficacité. Ceci permettrait également de quantifier le déplacement de la criminalité en voyant l’impact historique de l’implémentation des bâtiments sur la criminalité dans la ville.
Références
Urban Planning and Environmental Criminology: Towards a New Perspective for Safer Cities, Cozens, P. M. (2011) ↩︎
Inscrite au patrimoine mondial immatériel de l’UNESCO, la gastronomie française tient une place spéciale dans le cœur des français. L’art du “bien boire” et du “bien manger” est ancré profondément dans nos coutumes, tant et si bien que pour de nombreux français le vin et les repas cuisinés sont indissociables : 90% des repas avec invités ont une bouteille de vin à table, 92% des français associent l’image du vin à un plat, 88% associent le vin à la convivialité et au partage,…ces chiffres de l’IFOP Vins&Société ont de quoi vous donner le tournis !
Quelques chiffres sur les relations entre vin et repas
Mais si, vu de l’étranger, tout français maîtrise cet art de vivre dès la naissance, la réalité est toute autre : plus qu’un art, être capable de proposer à ses convives un repas dont les saveurs sont sublimées par une gorgée de la judicieuse bouteille de vin que vous aurez choisi pour l’accompagner est une science. Qui ne s’est jamais retrouvé dans cette situation : vous invitez vos amis à dîner chez vous, passez de nombreuses heures à étudier les recettes Marmiton à la recherche de l’inspiration, sélectionnez LA recette parfaite, partez en courses, dénichez les ingrédients nécessaires, arrivez enfin au rayon vins de votre supermarché favori et là… c’est le drame. Vous vous retrouvez devant ce mur de bouteilles et vous n’avez aucune idée de laquelle choisir. Blanc pour le poisson, rouge pour la viande : c’est bien beau tout ça, mais ça laisse quand même beaucoup d’options. Finalement, par dépit, vous partez avec une bouteille assez chère (c’est gage de qualité) et dont le design vous aura attiré l’œil. Si vous vous reconnaissez ici, vous connaissez la suite : l’accord entre votre repas et votre bouteille a de forte chance d’être hasardeux.
Sommes nous condamnés à cette incertitude, à ce pic de stress additionnel à chaque grande occasion dont nous sommes les hôtes, nous cuisiniers amateurs n’ayant pas eu la chance de naître avec un oncle sommelier ? Peut-être pas.
Et si notre meilleur ami Marmiton venait à notre rescousse et nous suggérait la bonne bouteille pour la recette que vous venez de précieusement enregistrer dans vos favoris ?
Marmiton à la rescousse…c’est possible ?
Pourquoi diable Marmiton irait vous proposer une telle fonctionnalité ?
Tout d’abord parce que c’est une fonctionnalité qui s’inscrit parfaitement dans les valeurs de l’entreprise, à savoir plaisir, générosité, accessibilité et convivialité.
Ensuite parce que c’est une fonctionnalité innovante non présente chez ses concurrents qui potentiellement améliorerait l’expérience utilisateurs de ses clients (on est quand même pas les seuls à vouloir une telle fonctionnalité, si ?).
Enfin et surtout, parce que cela permettrait de générer de nouveaux revenus de partenariat avec des vendeurs de vins en ligne en échange de nouveaux canaux d’acquisition de clients pour eux.
Alors, pourquoi pas ?
Et techniquement, c’est réalisable ?
Comment s’y prendrait-on si l’on voulait mettre en place ce type de service ? C’est l’excellente question à laquelle nous avons essayé de répondre. Tout d’abord il faudrait mieux comprendre comment se réalisent les accords mets – vins : sur quels critères gustatifs se réalisent ils ? Quels ingrédients prennent le dessus sur d’autres ? Quel est l’impact de la cuisson des plats ? Comment caractérise-t-on les vins ? Qu’est ce qui différencie une appellation d’une autre ? …autant de questions qui restent sans réponse.
Quelques lectures plus tard, on commence à y voir (un peu) plus clair : les poissons et les viandes sont souvent l’élément décisionnaire de l’accord de vin pour un plat, ces derniers peuvent être caractérisés gustativement par leurs types de cuissons, les vins ont des caractéristiques tanniques, de fraîcheur ou encore de rondeur du fait de leurs cépages, de leur sol…
Si on peut caractériser des recettes et des vins par autant d’attributs, ne pourrait-on pas faire ressortir des corrélations qui permettent de proposer un accord pertinent pour une recette donnée ? Ne pourrait-on pas appliquer des méthodes de Data Science pour recommander ces accords mets-vins ?
Des données, des données et encore des données
Afin de vérifier ces hypothèses, il nous faut des données sur des accords mets et vins. Malgré le bien fondé de l’existence d’une telle base de données (surtout lorsque la période des fêtes approche à grands pas), il s’avère qu’il n’en existe pas. Afin de pallier ce problème, nous avons retroussé nos manches et commencé à constituer une base de données en utilisant une méthode à la limite de la légalité afin de collecter des données sur internet : le scrapping. Ces techniques, tolérées à des fins éducatives ou de recherche, permettent d’utiliser des robots qui parcourent le code des pages web afin de collecter les données qui y figurent.
Après des dizaines d’heures et quelques centaines de lignes de codes, le dataset est constitué :
les attributs des recettes (leur intitulé, la catégorie de plat associé et les ingrédients utilisés) sont collectés sur Marmiton,
ceux des vins (scores sur les goûts notamment le caractère tannique ou frais, les taux de sucre, les cépages, les appellations et leur description “sommelière” notamment) sur Nicolas et V&B,
et les bons accords mets vins sont tirées de l’ouvrage de Olivier Bompass, Les Vins et les Mets en 2500 Accords (on y trouve un nom de recette auquel est associé sa catégorie de plat, la typologie de vins suggérés – e.g. rouge, blanc..-, une description gustative des vins et des appellations correspondantes).
Au travail maintenant !
Data Science : du buzzword aux méthodes concrètes
Dire que l’on va appliquer des méthodes de Data Science n’apporte pas beaucoup d’informations sur la manière de modéliser et traiter le problème. Afin de recommander une bouteille de vin à partir d’une recette, nous avons envisagé différentes traductions en problèmes de Data Science : nous en détaillerons ici deux.
La première consiste à développer un système de recommandations basé sur une analogie au principe de Content-Based Filtering : une recette de notre base d’accords se marie bien à certains vins, la recette fournie par l’utilisateur est similaire à cette recette, donc potentiellement les mêmes vins pourraient lui convenir.
Première approche de système de recommandation
La seconde consiste à effectuer un apprentissage supervisé qui prend en entrée les attributs de la recette et la classifie selon le type de vin qui lui correspond le mieux (à un niveau basique sur la typologie, et pour aller plus loin sur la description gustative).
Seconde approche d’apprentissage supervisé
Ces deux approches nécessitent d’exploiter des données textuelles, notamment celles contenues dans les intitulés des recettes et dans les listes d’ingrédients. Afin de permettre aux algorithmes d’utiliser ces données, il nous a fallu utiliser des méthodes de NLP (Natural Language Processing, un champ du Machine Learning qui permet de traiter les langages) afin de les encoder sous formes de vecteurs pour pouvoir par la suite effectuer des calculs dessus. Concrètement, après un pré-processing des données afin d’isoler les termes les plus porteurs de sens des textes, il s’agit de choisir la méthode de vectorization la plus adaptée à leur contexte pour les représenter : c’est l’étape de « Word Embedding ».
Champagne…?
Les résultats obtenus avec ces deux approches sont plutôt encourageants.
Pour le système de recommandation, la mise en place d’un test d’évaluation de la pertinence des recommandations de recettes similaires pour 20 recettes nous a permis d’évaluer sur 100 points différentes méthodes de NLP appliquées aux intitulés des recettes et aux listes d’ingrédients (pour les plus curieux, la similarité entre les vecteurs est évaluée par la mesure cosinus, pour s’affranchir des problèmes de dimension variable des textes).
Les algorithmes permettant d’obtenir les meilleurs scores tout en affichant une meilleure robustesse – compte tenu des biais de notre système d’évaluation – sont ceux combinant les mesures de similarité sur les ingrédients (avec TF-IDF) et celles sur les intitulés de repas (avec des Bag of Words).
Performances systèmes de recommandation (NLP)
Pour la deuxième approche, appliqué au cas plus simple de la classification sur le type de vin (rouge, blanc, rosé ou effervescent), les algorithmes supervisés ayant montré les meilleures performances sont le Support Vector Classifier et la Régression Logistique, qui parviennent à 75% de bonnes classifications sur notre base de test.
La mise en bouteille, c’est pour quand ?
Si les preuves de concept sont encourageantes, nous sommes encore loin de voir cette fonctionnalité apparaître sur Marmiton (désolé, pour ce réveillon il faudra se creuser la tête pour ne pas fâcher Mamie). Au-delà des problématiques dues au développement de la fonctionnalité sur l’application et à l’hébergement des modèles, différentes étapes peuvent et doivent être mises en place avant de pouvoir lancer un produit.
D’un point de vue algorithmique, le système de recommandation a été évalué partiellement sur la pertinence des recettes similaires proposées mais pas sur l’accord de bouteille obtenu : l’analyse de retours d’utilisateurs permettrait de mieux apprécier la qualité de nos recommandations – et par la même occasion, l’appétence des clients pour ce type de service ! -, tout comme l’évaluation de la qualité des recommandations par un sommelier professionnel. D’autres techniques de NLP peuvent être mises en place pour améliorer la précision ou exploiter d’autres attributs de notre base de données (analyse de sentiments et d’intentions dans la description des vins notamment). Enfin, la base de données pourrait être étendue pour de meilleures performances algorithmiques : la data augmentation, en modifiant certains ingrédients mineurs des recettes, est une piste envisageable.
D’un point de vue business et juridique, selon l’appétence des utilisateurs le modèle de génération de revenus doit être pensé et des accords passés afin de se procurer les droits sur l’usage des données (le scrapping n’est pas légal à des fins commerciales). La suggestion de bouteilles de vin doit également être légalement encadrée pour éviter des accusations de “parasitisme” (une atteinte à l’image d’un produit en voulant utiliser son image de marque, par exemple ici si une bouteille de prestige est associée à un repas “banal”).
D’un point de vue éthique, enfin, la recommandation de bouteilles d’alcool peut inciter à la consommation d’alcool : il faut se conformer aux lois en vigueur sur ces questions de santé publique pour proposer les recommandations dans un format en adéquation avec celles-ci.
Les opinions des utilisateurs quant aux services/biens proposés, par une plateforme prennent aujourd’hui une place de plus en plus importante lors de la phase de réservation ou d’achat. Selon une étude,94% des utilisateurs n’ont pas acheté un produit en ligne suite à la lecture d’avis négatifs. En parallèle, on constate une augmentation du nombre d’avis propres à un produit ou un service, ainsi qu’une grande diversité dans leur contenu.
Nombre de nouvelles reviews Google par trimestre [https://searchengineland.com/googles-growth-in-online-local-reviews-continues-to-dominate-but-292571]Pour un même produit, on peut observer divers axes de notations relatifs : pour des logements, on pensera notamment à la propreté, la conformité à l’annonce, etc. Les “reviews” apportent donc bien plus de détails et d’informations précises quant à l’avis vis-à-vis d’un produit/service que ne fournissent pas les notations (généralement une note de 1 à 5). Effectivement, plusieurs notes faibles peuvent correspondre à divers aspects très différents qui ont paru critiques aux utilisateurs. Par exemple, dans notre cas des logements, une personne peut être marquée par la très mauvaise localisation d’un logement alors qu’une autre peut porter une plus grande importance à la propreté. Dans les deux cas, il s’agira d’avis négatifs, dont les notes pourront être semblables, mais qui se perdront dans la masse de commentaires tous aussi disparates.
Il est d’autant plus décisif d’extraire de la valeur de ces “avis utilisateurs”. L’idée à retenir de ce projet est de générer de la valeur pour les utilisateurs à partir de données issues de ces utilisateurs, dans l’idée de construire une boucle vertueuse.
Exploiter les avis utilisateurs, oui … Mais comment ?
La difficulté première de ce projet est d’être en mesure de comparer la pertinence de deux commentaires entre eux au regard de l’intérêt d’un utilisateur. Sur quel aspect va-t-on mesurer la valeur d’un commentaire pour un potentiel acheteur ? Cette réflexion nous a naturellement amenés à la formulation de la problématique suivante :
“Comment définir une relation d’ordre au sein d’un ensemble d’avis utilisateurs relatifs à un produit donné, pour un utilisateur donné ?”
Notons l’importance de la mention « […] produit donné, pour un utilisateur donné ». L’ensemble de nos analyses et constructions de modèles porteront, comme nous le verrons par la suite, sur une simulation respectant le cadre : un produit donné pour une catégorie de produits donnée, pour un utilisateur spécifique.
Cas d’usage
« Archibald souhaite acheter un nouveau produit d’entretien ménager et réalise une recherche sur le site. À ce stade, nous recueillerons l’ensemble des produits disponibles sur la marketplace, répondant à la recherche d’Archibald. La marketplace lui proposera alors, selon son système de recommandation, un certain nombre de produits. À cet instant, après avoir analysé l’ensemble des commentaires disponibles, nous demanderons à Archibald d’indiquer par une phrase les caractéristiques, propres au type de produit qu’il recherche, auxquelles il est sensible. Suite à cela, nous calculerons via notre algorithme de machine learning, un score de similarité entre l’entrée d’Archibald et l’ensemble des commentaires disponibles pour chaque produit. Cette similarité, comme nous le verrons, prendra en compte des notions thématiques (par exemple, Archibald évoque l’odeur du produit d’entretien), mais aussi grammaticale et sémantique. À l’issue de cette brève phase, lorsque Archibald sélectionnera l’un des produits de la liste proposée, nous aurons sélectionné pour lui les 3 commentaires de ce produit les plus à même de satisfaire les critères qu’il a aura entré plus tôt. »
Avant d’être en mesure de réaliser cette « aide à la décision », via une sélection automatique de commentaires pertinents, nous devons satisfaire les besoins suivants : recueillir l’ensemble des commentaires relatifs à un produit, traiter ce texte de manière à appliquer des algorithmes de machine learning, définir une mesure sur laquelle nous comparerons deux commentaires (relation d’ordre).
Notre proposition de valeur
Une fois que nous serons en mesure de comparer divers commentaires au regard de l’intérêt d’un utilisateur, nous pourrons nous présenter comme un tiers de confiance, transparent, apportant une aide à la décision aux clients souhaitant acheter un produit. Notre apport de valeur du côté du site intégrant notre solution est l’augmentation de la satisfaction client via une navigation facilité par la lecture de commentaires sélectionnés spécifiquement. Les utilisateurs trouveront plus rapidement les informations qu’ils cherchent dans les reviews, et gagnerons du temps sur un site équipé de notre solution. Les clients seront plus fidèles au site et plus propices à consulter plus de pages. De cette satisfaction pourra suivre une hausse potentielle du taux de vente.
Plongée au cœur des reviews, l’incroyable récit de notre périple !
Choix du dataset…
Nous avons choisi notre dataset de manière à garantir l’universalité de notre produit, ie ayant pour objectif de pouvoir s’intégrer de manière rapide et simple sur tout type de site de e-commerce. Nous avons donc cherché un dataset contenant au moins les champs suivants : identifiant d’un avis utilisateur, identifiant du produit relatif à l’avis, contenu textuel de l’avis utilisateur. D’autres champs pourront être utilisés pour améliorer le produit, mais dans sa première version nous nous en tenons à cela.
Le prototype que nous avons construit est basé sur une base de données fournie par datafiniti.co.
La base de données utilisée pour mener à bien le prototype est constituée de 70260 commentaires utilisateurs relatifs à un ensemble de 600 produits différents vendus sur 14 sites.
… du site…
Étudions rapidement la distribution des commentaires en fonction du site.
On observe la nette prédominance des sites Walmart (~ 45% du total) et Bestbuy (~ 36% du total).
Étudions alors notre variable d’intérêt : le contenu textuel des commentaires : Walmart apparaît comme le site le plus intéressant pour la suite de notre projet. En effet, les commentaires sont deux fois plus longs, avec une médiane à 14 mots contre 7 pour Bestbuy. Ainsi que des catégories plus intéressantes, car plus propices à trouver des commentaires plus objectifs. Bestbuy contenant majoritairement des commentaires de produits liés à l’audiovisuel (films, musique, …) .
Pour la suite du prototype, nous avons donc uniquement sélectionné les commentaires utilisateurs relatifs aux produits vendus sur Walmart.
… de la catégorie…
Plus spécifiquement dans la catégorie des produits d’entretien ménager (« Household Essentials ») contenant environ 8 552 avis (en ayant retiré les avis en doublons).
… et enfin, du Produit !
En outre, pour l’évaluation du modèle, décrite par la suite, nous utiliserons le produit sélectionné ci-dessous. Pour rappel, comme mentionné dans la problématique, notre produit réalise une sélection de commentaires pour un utilisateur et un produit donnés.
Rentrons dans le cœur du projet : de la donnée brute à la sélection de commentaires !
Traitement des textes
La première étape, sur laquelle repose en grande partie l’efficacité des algorithmes évoqués plus tard, consiste au traitement des données textuelles des commentaires utilisateurs de sorte à les rendre « compréhensibles » par des modèles de machine learning. Pour cette phase, nous utiliserons la librairie de référence « Spacy » sous Python, connue pour ses modèles de traitements de textes certes complexes, mais bien plus performants que des modèles issus de l’autre librairie de référence « NLTK ».
Le pre-processing peut être résumé par le schéma suivant :
« Nous adorons tous la Data Science, mais encore plus les produits d’entretien ménagers » → « nous, adorons, tous, data, science, mais, plus, les, produits, d’entretien, ménagers ».
Passons ensuite à nos modèles. Dans le but énoncé plus haut – la similarité entre l’entrée utilisateur et notre base de commentaires
Comment quantifier la similarité entre deux textes ?
Une similarité entre deux textes peut-être de plusieurs types : sémantique, grammaticale, thématique ou autre. Dans notre cas, nous procédons en deux temps.
D’abord en étudiant la similarité thématique. Nous extrayons les thèmes principaux de tous les commentaires du produit donné, pour ainsi pouvoir sélectionner les commentaires dont les thèmes principaux sont très proches des thèmes extraits de l’entrée utilisateur. Pour cette première étape, nous utilisons un LDA.
Ensuite, en étudiant la similarité sémantique nous cherchons parmi les commentaires en sortie de notre LDA, les 3 étant le plus sémantiquement proches de l’entrée utilisateur. Pour cela, nous utilisons un doc2vec avec pour mesure de similarité, la similarité cosinus.
Etape 1. Extraction des thèmes principaux
Rapide explication du LDA (Latent Dirichlet Allocation). Le LDA fait parti des modèles d’extraction de topics ou « Topic modeling » . Ces algorithmes partent du postulat qu’il existe, au sein d’un corpus de textes, des thèmes latents. Ainsi, ces modèles attribuent à chaque texte un pourcentage d’appartenance à chacun des thèmes détectés au sein d’un corpus.
Nous appliquons donc notre meilleur modèle de LDA, entraîné sur un corpus de commentaires relatifs à la catégorie « Household Essentials », pour attribuer à chaque commentaire des coefficients d’appartenance aux 6 topics identifiés. Nous faisons de même pour l’entrée utilisateur. Les commentaires les plus similaires thématiquement (quantile 75%) sont envoyés en entrée du modèle suivant le doc2vec.
Cette étape, effectuée en amont de notre Doc2vec est primordiale dans notre calcul de similarité. Plutôt que de longues explications, voici un exemple pour mieux comprendre : (a) Si l’on utilise un Doc2vec (de même pour Word2vec) pour prédire les documents similaires à un texte contenant le mot « French », on obtiendra probablement des documents contenant « German » ou « English » , car ces mots sont utilisés dans des contextes grammaticaux similaires. (b) Si l’on utilise un LDA en amont et que l’on cherche à prédire les mots similaires à un texte contenant le mot « French » et évoquant le thème de la « nourriture », on obtiendra cette fois non plus des documents contenant « German » ou « English » mais plutôt « baguette », « vin », « boulangerie ».
Etape 2. Calcul de similarité sémantique entre textes
En sortie de l’étape précédente, nous avions donc plusieurs commentaires qui ont été sélectionnés. Ensuite parmi ces commentaires on sélectionne les 3 commentaires ayant les plus hauts scores de similarité sémantique.
Une fois que deux textes sont représentés sous forme de vecteur grâce au doc2vec, il est possible de calculer leur similarité cosinus.
Nous sommes donc à présent en possession d’une relation d’ordre !
Notre sélection actuelle n’est basée que sur ce score de similarité. Des améliorations ont bien entendu été envisagées, notamment l’ajout de features telle que la longueur du message, le nombre de verbes/adjectifs, etc. Nous avons également songé à entraîner un algorithme supervisé dont la variable à prédire est l’utilité d’un message (ie champ « ce commentaire vous a été utile ? »).
Comment évaluer notre sélection ?
Du non supervisé au supervisé
Notre modèle étant non supervisé, nous n’avons pas accès à une méthode directe permettant de l’évaluer. En effet, nous donnons un top 3 des commentaires les plus pertinents, mais il est impossible de garantir que ce sont bien ceux qu’il fallait choisir dans l’ensemble disponible. Pour pallier cela, une approche classique consiste à rendre le problème supervisé afin de pouvoir l’évaluer. Nous avons alors aléatoirement extrait 100 commentaires d’un produit donné, puis nous avons écrit 100 entrées utilisateurs. Nous avons ensuite associé à chacune des entrées les 3 commentaires que nous jugions les plus pertinents parmi ceux extraits. Grâce à cet « étiquetage » manuel, nous avons donc les entrées et les sorties du modèle qui devient alors supervisé. Finalement, nous comparons le résultat renvoyé par le modèle à celui que nous avons indiqué.
Qu’en est-il des résultats ?
21 % des commentaires sélectionnés par notre modèle sont jugés pertinents par les utilisateurs.
Comme on peut l’imaginer assez naturellement, les scores fournis plus haut peuvent être améliorés en ne considérant pas un top 3, mais un top 5 ou plus. On constate effectivement qu’en augmentant le nombre de commentaires à prédire, on a potentiellement plus de chances de choisir les bons.
Ces scores sont relativement faibles, mais il est difficile d’en conclure quoi que ce soit. En effet, la sélection de commentaires pertinents est un sujet très subjectif. Ainsi, notre test est biaisé par la personne qui a écrit et labellisé les entrées utilisateurs. De plus, notre procédure de test est appliquée sur un faible volume de données qui ne suffit pas à conclure.
Déploiement, commercialisation
Notre produit peut s’intégrer sous forme d’API au sein du site d’un partenaire. Pour faire ses preuves en utilisation, nous pouvons fournir un accès gratuit à nos services durant un période de 2 mois, période durant laquelle notre solution sera soumise à un A/B test dont l’objectif sera de quantifier l’augmentation d’indicateurs de performance utilisés par l’entreprise (le taux de conversion/vente semble pertinent). Après une période de tests, notre outil sera vendu sous forme d’abonnement mensuel, dont le tarif sera calculé sous forme d’un pourcentage du nombre de ventes réalisées.
Simulation de déploiement
Les gains potentiels grâce à notre solution sont aujourd’hui difficilement évaluables. Cependant, l’essor des plateformes d’achat en ligne nous garantit que de plus en plus de gens consommeront en ligne, et seront donc sensibles aux commentaires des autres utilisateurs. En considérant que notre modèle aura une influence sur le volume des ventes d’un produit donné, nous pouvons estimer le gain pour des plateformes à différentes échelles. Ci-dessous, un exemple avec le produit “Clorox wipes” vendu 5.99$ sur walmart.com.
Depuis quelques années, le taux de criminalité global à New York a décliné, contrairement à d’autres grandes villes des USA. Pour autant, le taux de “hate crimes” (meurtres, viols, assauts graves) a beaucoup augmenté ces dernières années : 3,3 millions de victimes en 2018 contre 2,7 en 2015.
A la suite de ces constatations, le maire de New York, Monsieur Bill de Blasio, a lancé “the office for the prevention of Hate Crimes”, ou aussi appelé le MOCJ (Mayor’s office of Criminal Justice), en été 2019 afin d’empêcher ce type de crimes.
Pour aider le maire de New York, nous voulons créer un outil d’aide à la décision. Ce dernier permettrait de prédire l’impact de la modification de certains éléments, ou couples d’éléments, sur la criminalité pour chaque quartier de New York.
Quelles données utiliser ?
Nous avons cherché des données Open Data qui pourraient être liées à la criminalité, suite à la lecture de documents scientifiques traitant du sujet. Nous nous sommes ainsi concentrés, en premier lieu, sur des données socio-démographiques. Nous avons trouvé 7 variables d’intérêt comprenant le nombre d’habitants, le taux de personnes nées à l’étranger, le taux de pauvreté, le taux de chômage, le taux de diversité ethnique et le taux de jeunes déconnectés, par quartier de New York et par année entre 2000 et 2018.
Cependant, il est difficile pour le maire de mener des actions qui auront un impact direct sur ces variables. Comment avoir un impact direct sur la pauvreté ou le taux de chômage ?
Nous avons donc cherché d’autres sources de données qui permettaient d’avoir des renseignements notamment sur le nombre de commissariats, sur les infrastructures présentes dans différents quartiers et sur les évènements sociaux. Ce sont sur ces critères que le maire de New-York pourra influer.
Que faire de toutes ces données ?
Dans un premier temps, il s’agissait d’effectuer une préparation des données, qui a pris beaucoup de temps. En effet, le défi était de fusionner 11 bases de donnés puis de les regrouper en un seul dataset qui nous permette de répondre à notre problématique.
Le dataset final regroupe les données par quartiers et par années entre 2006 et 2018.
Pour fusionner les différents datasets, nous disposions des coordonnées GPS des événements et infrastructures. Il fallait donc faire correspondre ces coordonnées GPS aux Community District auxquels elles appartenaient. Cela a été effectué à l’aide d’une librairie Python de traitement des données géospatiales : geopandas. La ville de New-York met également à disposition des fichiers contenant les formes de chaque Community District, ce qui a permis d’effectuer l’opération.
Suite à ce travail nous nous sommes retrouvés avec le dataset suivant:
Mais la préparation des données ne s’est pas arrêtée là. En effet, notre problématique étant d’observer l’impact de certaines actions sur la variation de crime dans un quartier, nous avons décidé de faire d’autres modifications au dataset afin que notre étude soit plus adaptée à nos besoins.
Dans un second temps, nous avons donc décidé d’ajouter des colonnes qui expriment les variations de données d’une année sur l’autre plutôt que seulement les chiffres de l’année en cours. Par exemple, à partir de la colonne “Commissariats” on ajoute la colonne “Différence de commissariats” qui correspond au nombre de commissariats sur l’année étudiée moins le nombre de commissariats de l’année précédente.
Une fois toute cette base de données regroupée et afin d’avoir une première idée des influences de certaines variables, nous avons fait une première étude de corrélation. Nous avons retrouvé des corrélations plutôt intuitives et cohérentes. En temps normal ces études de corrélations permettent de supprimer les variables redondantes. Mais dans le cadre de notre modèle nous n’avons pas jugé utile d’en retirer, permettant à notre client d’avoir plus de choix de modification de données lors de la simulation de l’évolution du nombre de crimes dans un quartier.
La base de donnée finale est donc de 767 lignes par 55 colonnes.
Un problème de classification …
Plutôt que de prédire le nombre de crimes d’un quartier d’une année sur l’autre nous avons décidé de prédire la variation de crimes et de la regrouper en 3 classes : Augmentation, Diminution ou Stagnation du nombre de crimes par rapport à l’année précédente. La stagnation correspond à une variation du nombre de crime inférieure, en valeur absolue à 200.
Deux algorithmes nous intéressent tout particulièrement : l’arbre de décision et la régression logistique. En effet, ces deux algorithmes ont la particularité d’être facilement lisibles, ils ne sont pas des boîtes noires. Il est donc possible d’extraire les règles permettant de mener à la décision de l’appartenance à une catégorie ou à une autre.
Evaluation de nos modèles
Algorithme
Temps d’exécution
Précision
Aire ROC
Arbre de décision
< 1 seconde
55%
0.61
Random Forest (50 arbres)
~ 1 seconde
75.9%
0.77
Régression
Logistique
< 1 seconde
78.1%
0.51
Ainsi, l’algorithme de Random Forest est le plus performant dans notre étude (Aire ROC bien supérieur à 0.5, qui correspond à une classification faite au hasard).
De plus, il est toujours intéressant d’étudier l’arbre de décision sachant que cela nous permet d’identifier des associations de variables influençant la variation de crime dans le même sens pour aider à jouer sur les facteurs pour trouver les bonnes combinaisons de facteurs réduisant le crime.
Des scénarios prometteurs
Ainsi, nos modèles nous ont permis d’identifier des facteurs influençant la criminalité positivement et négativement. Nous avons donc simulé différents types de scénarios pour visualiser l’impact sur la criminalité.
Nous avons réalisé un premier scénario augmentant le nombre d’évènements sociaux de 30% : la criminalité diminuerait dans 3 quartiers.
Avec un deuxième scénario, nous avons cette fois augmenté le nombre d’événements sociaux de 10% et les infrastructures sociales de 2% : nous remarquons alors que la criminalité baisse dans 10 quartiers. Nous conseillons donc au maire de se concentrer en premier temps sur ces quartiers et d’y mettre en place d’avantage d’évènements sociaux.
Des améliorations sont tout à fait envisageables. Nous pourrions déterminer des associations de variables plus précis à l’avenir pour permettre la réalisation de scénarios encore plus efficaces pour la diminution du crime à New York. De plus, il serait intéressant de réaliser les modèles sur des groupes (clusters) de quartiers afin d’avoir des résultats encore plus précis selon le type de quartier. En effet, les variables n’influencent pas les quartiers de la même manière.
La somnolence au volant représente un véritable danger pour les automobilistes. En effet, une étude de l’American Automobile Association démontre que le risque est conséquent car plus d’un accident mortel sur six est lié à l’assoupissement au volant.
De plus, les conséquences économiques sont lourdes avec un préjudice estimé à plus de 30 milliards de dollars. C’est d’autant plus le cas pour les sociétés de transport routier dont les conducteurs sont confrontés à un haut facteur de risque puisqu’ils travaillent pendant de longues durées et souvent de nuit. Effectivement, une étude indique que près de 20% des conducteurs professionnels interrogés affirment s’être déjà endormis au cours du mois courant.
Une start-up imaginaire désireuse de sauver des vies
Pour être fidèles aux considérations business présentes en Data Science, nous nous sommes projetés dans le futur en start-upers, souhaitant mettre en pratique nos compétences pour répondre à des problèmes du quotidien. Ainsi, notre jeune start-up Rouse envisage-t’elle de développer une application mobilisant le Machine Learning pour exploiter les données d’un bracelet connecté porté par le conducteur qui surveillera ses constantes biologiques et l’alertera si jamais elle détecte un assoupissement.
Le business plan de Rouse est divisé en deux phases de déploiement. En effet, il s’agira dans un premier temps de concevoir un modèle sur des données académiques obtenues au cours d’étude sur le sommeil qui permettra de valider la faisabilité d’un tel projet. Dans un second temps, nous déploierons cette solution au sein d’un environnement de test représentatif du cas d’utilisation réel.
Des données pertinentes … issues d’Apple watches !
Le jeu de données utilisé provient de la banque de données open data en ligne PhysioNet, spécialisée dans les données physiologiques. Il a été collecté au département de Neurologie de l’université du Michigan via une étude sur le sommeil et se présente la forme de signaux de mesures de rythme cardiaque (battements par minute) et d’accélération (mesurées en g) ainsi que le nombre de pas. Ces données ont été collectées en faisant porter des Apple Watch à des participants qui les surveillaient pendant leur sommeil.
Le volume des données est assez grand pour permettre à la fois d’entraîner un modèle et de l’évaluer. En effet, les durées d’enregistrements sont de 7 heures en moyenne par patient, avec 75% des patients ayant au moins 8 heures d’enregistrement! Voici ci-dessous une visualisation des données à notre disposition sur une fenêtre de trente secondes :
Visualisation pour un patient
Le patient s’endort, puis il y a un court épisode durant lequel il se réveille puis se rendort tout de suite après : on peut voir le changement dans le rythme cardiaque qui augmente puis revient à des valeurs précédentes. Cela indique que, dans une certaine mesure, les données sont pertinentes pour répondre à la problématique et sont suffisamment représentatives pour mettre en exergue une transition entre un état éveillé et un état de sommeil léger c’est-à-dire un assoupissement.
Passer le balai sur les mauvaises données
Allez hop ! Il est temps de nettoyer les données pour par la suite mettre en place notre modèle. Elles sont sous forme de fichiers .txt différents par patient et par attribut. Il a donc fallu assembler les données des différents attributs pour un même patient puis aussi rassembler les données de tous les patients confondus.
Ceci n’a pas été simple car les données ne sont pas toutes exactement de la même forme, ce qui est indispensable afin de faire une jointure et générer des attributs. L’idée est donc de mettre en forme les données du rythme cardiaque, leur attribuer le bon label, et de mettre les données d’accélérations sous la même forme pour permettre la jointure.
Place à nos algorithmes de Machine Learning
Des considérations liées à la nécessité de classifier en temps réel et ne pas avoir à traiter les flux entrants nous ont menés à implémenter un modèle de forêt aléatoire (RandomForest), et dans un deuxième temps des modèles de Naive Bayes et SVM.
Nous avons opté pour les deux critères d’évaluation suivants :
Précision : elle permet de qualifier les performances de la classification par le modèle
Rappel pour les labels 1 et 2 : il est crucial de maximiser la détection des vrais positifs qui correspondent à un état d’endormissement (passage de l’état 1 à 2).
Tableau comparatif des modèles
Parmi les modèles de classifieurs entraînés, nous pouvons conclure avec certitude que Random Forest est le plus adapté. Comme nos données sont des signaux physiologiques collectés par un dispositif électronique, nous devons tester notre modèle face au bruit éventuel qui peut s’infiltrer. Nous avons donc classifié des données auquel on a ajouté du bruit, pour différents SNR (rapport signal à bruit) et nous avons comparé les performances obtenues par le modèle que nous avons sélectionné : le Random Forest. Les résultats illustrés ci-dessous sont des résultats auxquels on pouvait s’attendre : plus le SNR est bas (plus l’intensité bruit dépasse celle du signal) plus les performances du modèle faiblissent.
Évolution du rappel en fonction du SNR
On se prépare pour la suite !
Ces résultats prometteurs nous permettent de suivre le déroulement prévu du projet et donc de planifier une phase de déploiement qui nous servira à suivre la performance du modèle dans des cas réels.
Il sera alors nécessaire de porter notre attention sur de nouvelles considérations, en particulier le fondement juridique. En effet, jusqu’alors nous avions utilisé une base de données sous la licence permissive OPEN DATA ODC-BY 1.0. Les personnes soumises à l’enregistrement de leurs données biologiques étaient Américaines ; conséquemment la conformité à la RGPD n’était pas requise.
Néanmoins, le cadre légal sera plus contraignant une fois le dispositif mis en place puisqu’il faudra respecter la RGPD. Plus spécifiquement, le signal physiologique qu’est la fréquence cardiaque possède un degré de protection supplémentaire en tant que donnée sensible par rapport aux données conventionnelles qui nécessite de mettre en place une solution de cryptographie adéquate.
Rouse se devra également de trouver un financement pour poursuivre un tel déploiement. Nous estimons que les résultats préliminaires encourageants permettront de convaincre des investisseurs de placer leur confiance en notre projet.
Le diabète, maladie souvent sous-estimée, touche aujourd’hui plus de 400 millions de personnes dans le monde et l’OMS prévoit plus de 600 millions de cas d’ici 2040. Cette progression est une réalité encore trop peu connue à l’heure actuelle, qu’il ne faut pas négliger. En effet, plus de 5 millions de personnes sont décédées du diabète en 2015 ce qui place cette maladie comme forte cause de mortalité dans le monde. De plus, il y a une réelle problématique concernant la connaissance de la maladie car 1 personne diabétique sur 2 ne sait pas qu’elle est atteinte. C’est pourquoi, il y a un véritable besoin de sensibilisation et de prévention de cette maladie, encore trop ignorée à ce jour.
Quelques chiffres clés
Source : International Diabetes Federation
Qu’est-ce-que le diabète ?
Le diabète est une maladie liée au mauvais traitement du sucre par l’organisme, qui conduit à une hyperglycémie et donc à un taux élevé de glucose dans le sang. Lorsqu’on mange des glucides, ils sont transformés en glucose. Les cellules du pancréas détectent alors une augmentation de glycémie et sécrète en conséquence des hormones (de l’insuline) qui permettent de réguler le taux de glycémie. Chez les diabétiques, ce système de régulation n’est pas présent. On considère qu’une personne a du diabète si son taux de glycémie dépasse 1.26 g/l à deux reprises dans la journée ou est égale ou supérieure à 2 g/l à n’importe quel moment. Il existe deux types de diabètes : un type I, maladie auto-immune qui apparaît dans la jeunesse et un type II qui apparaît plus tardivement, souvent après 40 ans et qui peut être lié à une mauvaise hygiène de vie. Le premier type, beaucoup plus rare, est souvent très rapidement diagnostiqué dès le plus jeune âge. A l’inverse, le second type de diabète représente plus de 90% des diabétiques et il est souvent inconnu des personnes atteintes. C’est donc le diabète de type II qui sera le sujet de notre étude.
Mais quelles sont les causes de cette maladie ?
De nombreux facteurs de risque sont souvent cités quand on parle de diabète. Le tabac, l’alcool, le cholestérol, l’alimentation, la pratique de sport, la sédentarité constituent un panel d’exemples de déclencheurs probables du diabète.
Notre projet, d’où proviennent nos données ?
Pour palier à ce manque de prévention et sensibilisation, nous avons voulu créer un outil permettant d’évaluer le risque d’une personne de développer le diabète.
A l’aide d’un questionnaire d’une dizaine de questions, nous pouvons prédire votre risque de devenir diabétique. Cette campagne de prévention permettra ainsi de sensibiliser les gens afin qu’ils changent si besoin leurs habitudes alimentaires, sportives, ou qu’ils prennent rendez-vous pour vérifier leur état de santé. En effet, comme pour de nombreuses maladies, un dépistage précoce permettra un meilleur traitement.
Afin de suivre et de détecter tout type de maladie, l’organisme américain Centers for Disease Control and Prevention met en place tous les ans un sondage auprès de ses citoyens qui renseigne de leur état de santé, de leur suivi médical ou encore de leur hygiène de vie. Le BRFSS (Behavioral Risk Factor Surveillance System), l’entité responsable de ces travaux, recueille des données dans les 50 États ainsi que dans le District de Columbia et dans trois territoires américains. BRFSS réalise plus de 400 000 entrevues avec des adultes chaque année, ce qui en fait le plus important système d’enquête sur la santé mené de façon continue au monde. C’est cette base de donnée que nous avons utilisée durant ce projet.
Nous tenons à préciser que les données utilisées dans le cadre de cette étude sont anonymisées afin de préserver la vie privée des gens. De plus, toutes les données produites par les agences fédérales sont dans le domaine public (cf section 105 of the Copyright Act), ce qui nous a permis d’utiliser librement et légalement ces informations.
Description de notre dataset
Les individus interrogés ont été sélectionnés au hasard. On obtient un échantillon assez représentatif de la population américaine notamment vis à vis du nombre de diabétiques. Ces graphes présentent la répartition des individus par genre et âge.
Nous avons donc développé plusieurs algorithmes basés sur ce dataset permettant d’évaluer le risque d’un individu de développer du diabète.
Pour mener à bien ce projet, nous avons suivi une démarche rigoureuse, commençant par la compréhension du besoin métier jusqu’à la mise en place de notre solution.
Ce schéma présente ainsi les différentes étapes de ce projet :
Préparation des données et analyse des données
La compréhension et la préparation des données a sûrement été le plus gros challenge de notre projet. En effet, les données brutes récupérées comportaient environ 330 variables encodées qui correspondent aux différentes réponses recueillies lors du questionnaire. Nous avons choisi de travailler sur les données de différentes années soit de 2011 à 2016. En agrégeant les données, nous obtenons un unique fichier de 2.821.503 lignes.
Nous avons en premier lieu étudier chaque colonne en utilisant une documentation d’explication des résultats du sondage, fourni par le BFRSS. La compréhension des variables nous a permis de sélectionner 100 colonnes. Les deux critères de sélection sont : Le nombre de valeurs manquantes pour la colonne concernée et la pertinence de la question. En effet, certaines variables avaient très peu de données ou n’apportaient rien à notre étude. Nous avons donc pu faire un premier tri.
Ensuite, nous avons étudié de plus près les relations existantes entre les différentes variables en utilisant une matrice de corrélation. Cela nous a permis d’affiner notre sélection. Nous avons utilisé 28 colonnes afin de construire des attributs pertinents.
Quels algorithmes ?
Nous nous sommes attaqués ici à un problème de classification, il s’agit de déterminer à l’aide de différents paramètres (taille, poids, fréquence de sport, etc…) si un individu risque d’être diabétique ou non.
Il existe de nombreux algorithmes de machine learning pour résoudre ce genre de problématique. Nous avons décidé de nous pencher sur 4 algorithmes qui sont en général particulièrement efficace pour ce type de classification binaire : la régression logistique, l’arbre de décision, le random forest et le support machine vector.
Comment évaluer nos modèles ?
Il existe plusieurs manières d’évaluer ce type de modèle.
Dans le cadre du machine learning et des algorithmes de type supervisé, on sépare souvent le dataset en deux parties (70%-30%), un qui servira à créer notre modèle (entraînement) et un deuxième à tester notre modèle.
Une première manière simple et efficace d’évaluer notre modèle est de regarder la matrice de confusion et ses métriques :
La courbe de ROC prenant en argument la sensibilité et la spécificité permet également d’évaluer un modèle à sortie binaire. On réalise la courbe de ROC de notre algorithme et on calcule ensuite l’aire sous la courbe (valeurs comprises entre 1 et 0.5). Plus l’aire est proche de 1 plus le modèle est pertinent, une aire proche de 0.5 sera équivalente à la probabilité de lancer une pièce et de deviner si le résultat sera pile ou face, autrement le hasard.
Voici un tableau récapitulatif des résultats des algorithmes réalisés avec le langage de programmation R (temps d’exécution obtenus sur une machine bureautique basique en 2018).
Algorithme
Temps d’exécution
Précision
Aire ROC
Régression logistique
7 minutes
91,69%
0,91
Arbre de décision
3 secondes
90,59%
0,5
Random Forest (250 arbres)
37 minutes
94,31%
0,92
Support Vector Machine
5 heures
90,58%
0,5
On constate donc que le Random Forest est l’algorithme le plus adapté à notre projet.
Une solution fiable et efficace
Afin de constituer le questionnaire de notre outil, nous avons cherché les variables qui influent le plus notre prédiction. Ces facteurs de risque sont présentés par ordre d’importance, ordre trouvé grâce à nos algorithmes.
Améliorer les résultats grâce à des technologies Big Data
L’exécution de certains algorithmes comme le Random Forest est assez coûteuse en temps, comme on peut le voir sur dans le tableau précédent. C’est pourquoi, nous nous sommes intéressés à l’utilisation d’une plateforme Big data pour réduire ce temps d’éxécution.
L’Institut Mines-Télécom et le GENES ont mis en place une plateforme de traitement de données massives : “Teralab”. Elle a une capacité de traitement importante avec une mémoire vive de plusieurs teraoctets et permet un traitement distribué des données: notre algorithme ne tourne plus sur une seul machine mais sur plusieurs à la fois d’où une réduction de son temps d’exécution.
Nous avons donc décidé d’utiliser cette plateforme pour notre projet. Pour cela, nous avons réécrit nos algorithmes en un autre langage : PySpark. Et le résultat est sans appel, nous obtenons un gain d’apprentissage de 9 !
Notre algorithme permet de prédire le risque d’avoir du diabète. Cette solution peut être utilisée afin de sensibiliser des individus au sein d’une population. Nous avons pensé développer une interface web permettant de recueillir les habitudes de vie d’une personne grâce à un questionnaire. Notre algorithme va ainsi pouvoir évaluer les probabilités que cette personne soit atteinte de cette maladie. Dans une version ultérieure, l’algorithme pourrait aussi faire des recommandations pour diminuer ce risque.
D’autres améliorations sont possibles. Il est probablement intéressant d’utiliser un dataset plus adéquat au problème pour l’apprentissage de l’algorithme. En effet, des informations sur l’hérédité pourraient améliorer la précision des résultats. Il pourrait aussi être judicieux de faire la distinction entre les différents types de diabètes.



/images/image7.png)


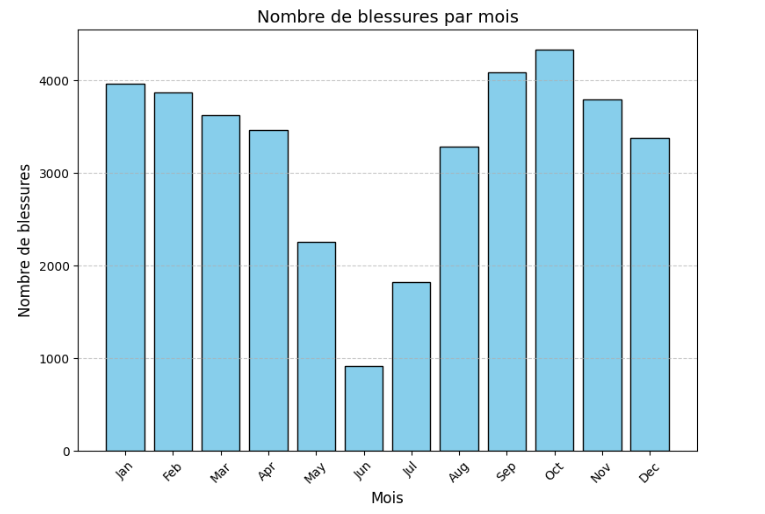
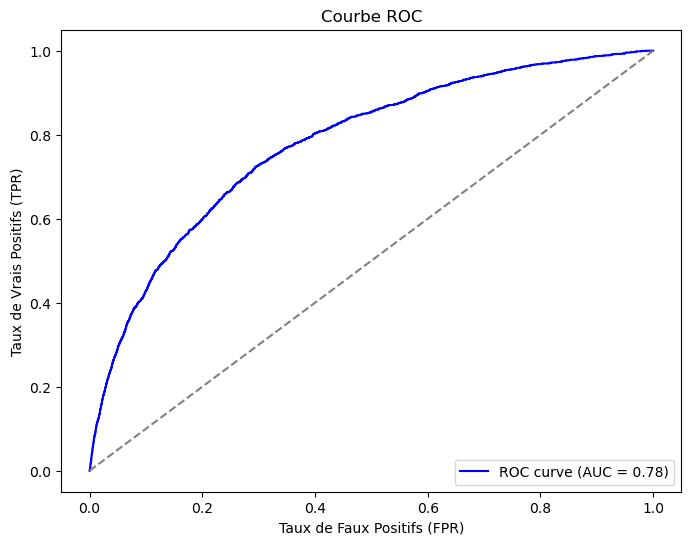

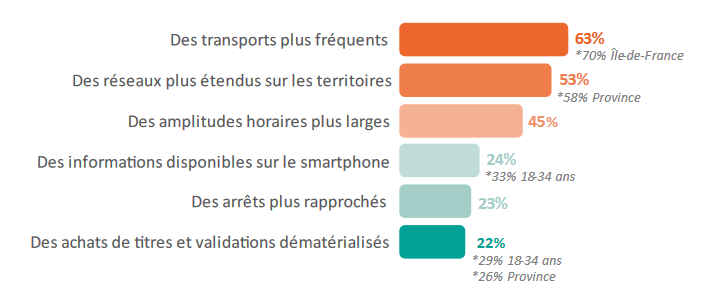
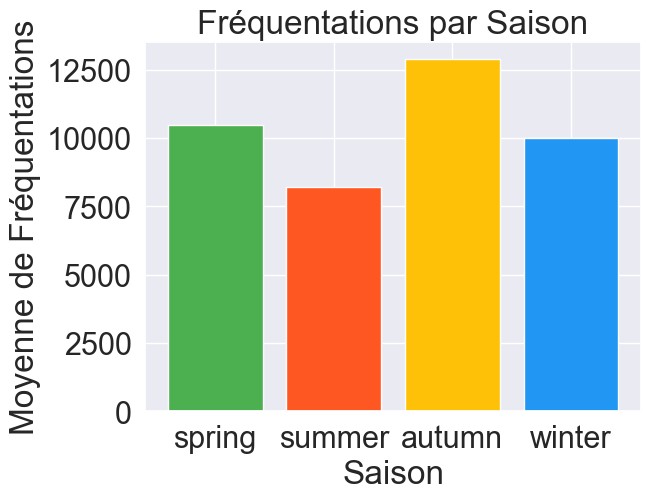
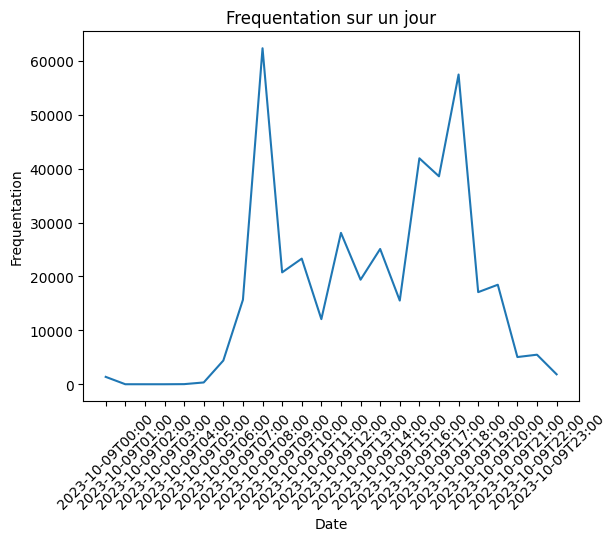
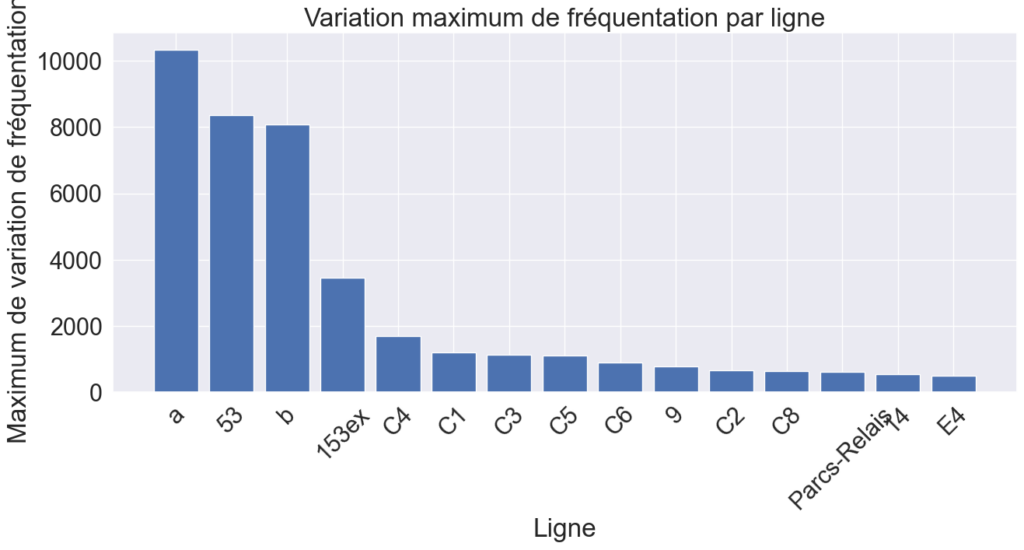











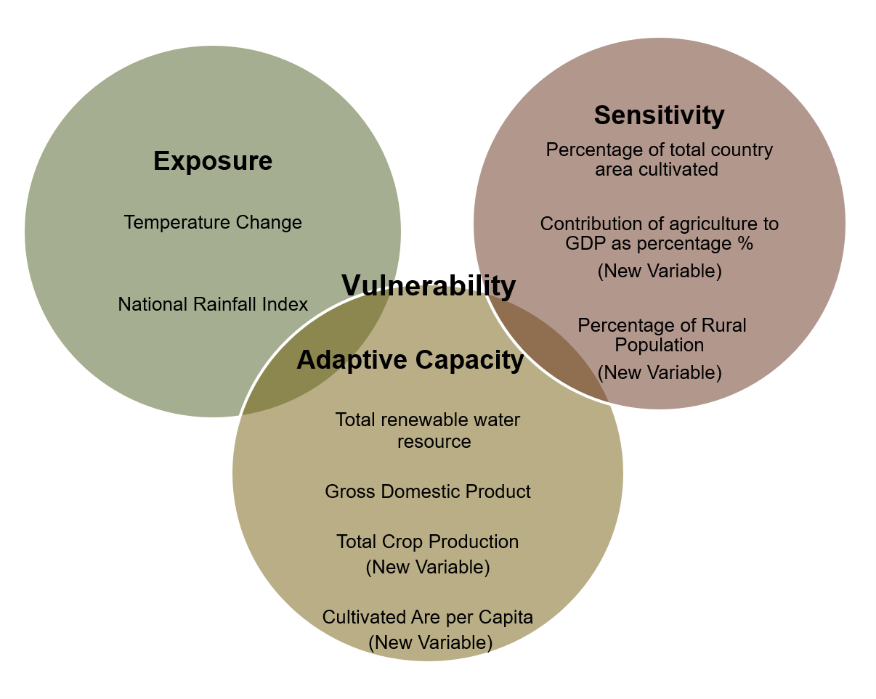
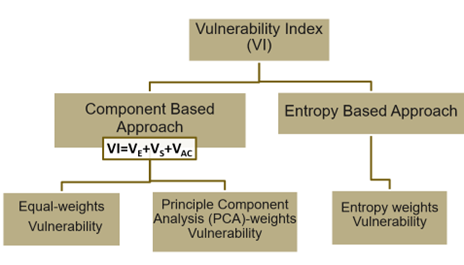
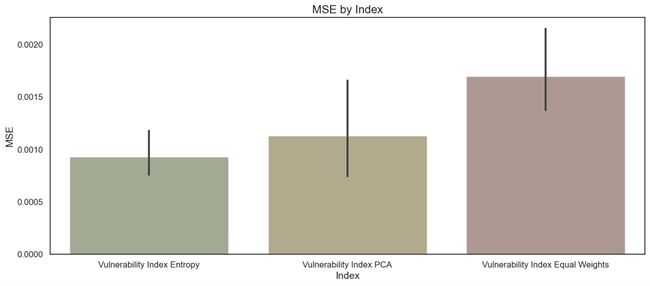
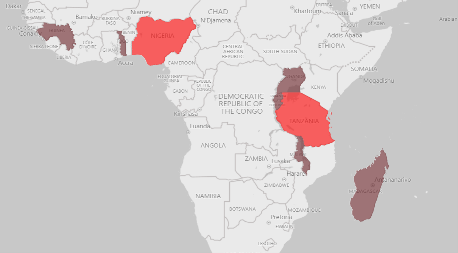
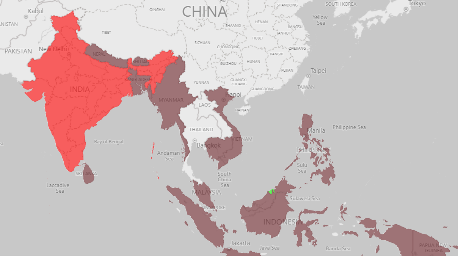
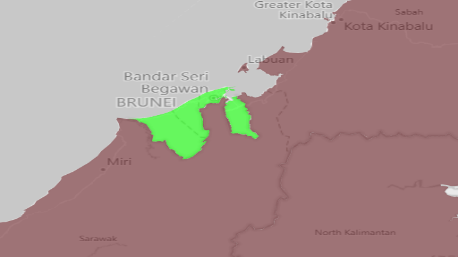





























 Depuis quelques années, le taux de criminalité global à New York a décliné, contrairement à d’autres grandes villes des USA. Pour autant, le taux de “hate crimes” (meurtres, viols, assauts graves) a beaucoup augmenté ces dernières années : 3,3 millions de victimes en 2018 contre 2,7 en 2015.
Depuis quelques années, le taux de criminalité global à New York a décliné, contrairement à d’autres grandes villes des USA. Pour autant, le taux de “hate crimes” (meurtres, viols, assauts graves) a beaucoup augmenté ces dernières années : 3,3 millions de victimes en 2018 contre 2,7 en 2015.










 : Le nombre de valeurs manquantes pour la colonne concernée et la pertinence de la question. En effet, certaines variables avaient très peu de données ou n’apportaient rien à notre étude. Nous avons donc pu faire un premier tri.
: Le nombre de valeurs manquantes pour la colonne concernée et la pertinence de la question. En effet, certaines variables avaient très peu de données ou n’apportaient rien à notre étude. Nous avons donc pu faire un premier tri.



