
Par Wydie Nessesy Kela, Christ Dadie, Thibault Martinez, Baka-Junior Cedric Blé, Louis Laudereau
Les transports en commun sont aujourd’hui parmi les principaux moyens de transports quotidiens en France. Aujourd’hui, 22% de la population française utilise les transports en commun dans leurs trajets quotidiens [1].

Comment pouvons nous rendre plus agréable ces trajets quotidiens et améliorer la vie de plus d’1/5 des français ?
Un besoin de visibilité sur le réseau
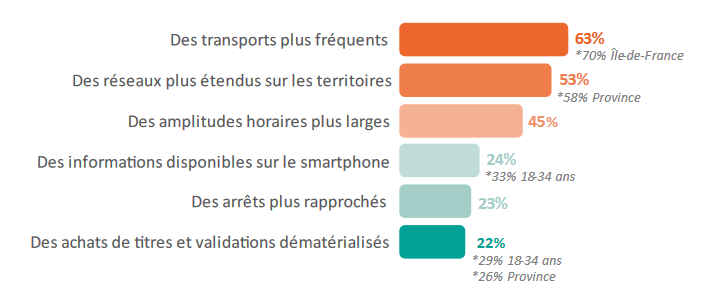
En interrogeant les utilisateurs des réseaux de transports en communs en France [2], il apparaît que ceux-ci aimerait en priorité des transports plus fréquents (Fig.1).
Cependant, il est préférable pour les gestionnaires de réseaux d’allouer plus de transports lorsqu’ils en ont vraiment besoin, comme lors de fortes variations de fréquentation. Au-delà des variations dues à l’heure ou au jour, la météo pourrait être un facteur influençant la fréquentation des transports en commun. On s’imagine facilement que lors d’un jour pluvieux par exemple, des personnes se rendant normalement au travail à pied préfèrent le bus ou le métro. Rennes étant une ville assez pluvieuse et dont les données du réseau régi par l’entreprise STAR sont accessibles librement, ce sera sur cette ville que nous explorerons cette idée.
Nous cherchons donc à fournir à l’entreprise STAR à Rennes des prédictions de variation de fréquentation en prenant en compte les données météos pour que celle-ci adapte le nombre de transport en conséquence.
Des variations de fréquentation saisonnières
Pour répondre à notre problème, il nous faut donc tout d’abord des données sur la fréquentation des lignes du réseau STAR. Nous nous procurons sur le site de STAR une base de données de fréquentation relevée toutes les 15 min [3]. Il nous faut en effet des relevés assez fréquents pour prédire la fréquentation à des heures précises et pouvoir adapter le nombre de transports en conséquence plus précisément.
En analysant ces données, on voit apparaître des tendances saisonnières sur la fréquentation du réseau. On remarque notamment des différences en fonction de la saison (Fig.2) ou de l’heure (Fig.3). On observe aussi évidemment une baisse de fréquentation le week-end et les jours de vacances scolaires.
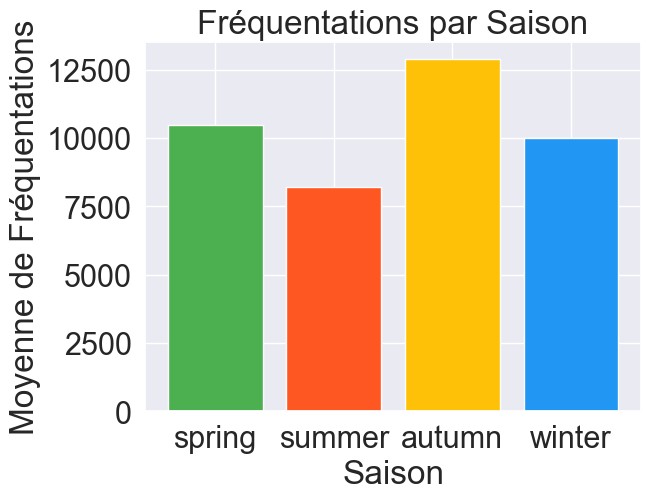
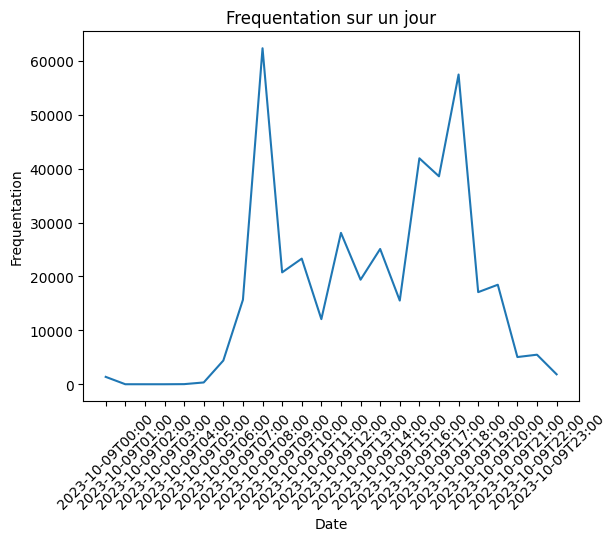
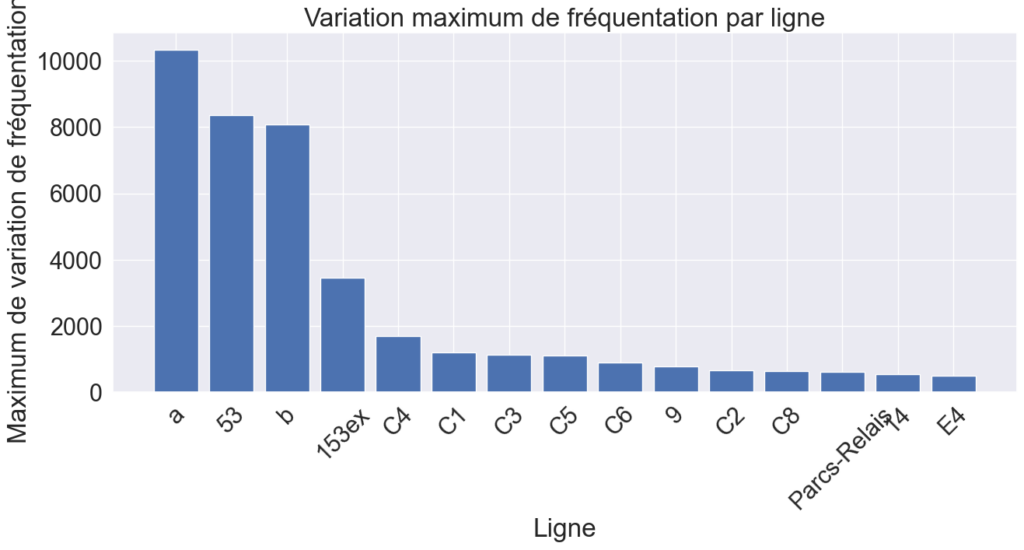
Pour savoir sur quelle ligne de transport il serait le plus nécessaire de moduler le nombre de transports en fonction de la fréquentation, on affiche les variations de fréquentation maximales par ligne (Fig.4) calculées par rapport à des fréquentations moyennes sur les différentes périodes. On voit bien que les variations les plus importantes du nombre de passagers se situent sur le métro a. Ajoutez à ça que cette ligne est automatique, celle-ci apparaît comme la candidate parfaite pour notre étude. On ne s’intéresse donc maintenant qu’à cette ligne dans la prédiction de la variation de fréquentation en fonction de la météo. Mais pour cela, il nous faut des relevés de météo.
Une multitude de données météo
Nous trouvons un dataset Météo France [4] qui nous fournit des relevés horaires d’une station proche de Rennes. Ces mesures vont de la température à l’humidité en passant par la puissance du vent.
On s’assure rapidement que nos données sont cohérentes et que l’on utilise pas un jeu de données complètement faux avant de relier ces données météo à nos données de fréquentations.
Qu’en est-il du lien entre fréquentation et météo ?
Pour analyser le lien entre la météo et la fréquentation, on regroupe nos deux jeux de données en un plus grand dans lequel on associe pour chaque heure de chaque jour les relevés météo et la fréquentation associés.
On calcule alors des coefficients de corrélation entre la fréquentation et les données météos. Nous ne trouvons aucune variable météo qui expliquerait seule les variations de fréquentation, mais certaines valeurs de corrélations non négligeables nous laissent présager que l’association de toutes les données météos pourrait nous permettre de prédire efficacement ces variations.
Cependant, aucun lien n’apparaît entre nos données météo et la variation de fréquentation. Ainsi, nous décidons de prédire premièrement la fréquentation grâce aux données météos, puis nous calculons la variation de fréquentation en comparant la valeur de fréquentation et la valeur moyenne de fréquentation associée.
Comment prédire ces fréquentations ?
Nous essayons de prédire une variable cible : la fréquentation. Pour cela nous utiliserons donc un algorithme d’apprentissage supervisé qui prendra la forme d’un modèle de régression.
Un algorithme d’apprentissage supervisé s’entraîne, sur des données collectées, à prédire la variable cible à partir d’autres variables, dans notre cas les relevés météos. Il ajuste son fonctionnement au cours de l’apprentissage pour améliorer ses prédictions. Il peut lui-même savoir s’il se trompe ou non car il peut comparer sa prédiction avec la réponse attendue qui est comprise dans le jeu de données.
Un modèle de régression est simplement un algorithme qui prédit une valeur numérique (qui peut prendre n’importe quelle valeur). C’est l’opposé d’un modèle de classification qui prédit une valeur parmi un ensemble de plusieurs valeurs définies (chaque valeur étant associée à une classe)
Il existe une multitude d’algorithmes d’apprentissage supervisé utilisables pour faire de la régression. Nous devons donc tous les tester pour choisir le meilleur qui sera choisi comme algorithme final.
Est-ce que ces modèles sont performants ?
On compare premièrement la performance des différents modèles de prédiction sur une petite partie des nos données, appelée échantillon de validation. Le modèle le plus performant est le Gradient Boosting. Nous le choisissons donc comme notre algorithme final. Cet algorithme a un fonctionnement assez simple : il corrige petit à petit son erreur de prédiction par rapport à la valeur qu’il aurait dû trouver. Il estime à chaque itération cette erreur et la retire au résultat final, d’où son utilité dans notre cas d’une valeur continue.
Nous entraînons notre modèle final avec le reste de nos données, tout en gardant une petite partie de nos données restantes comme échantillon de test. Ce dernier nous permet alors d’obtenir la performance de notre modèle final sur des données qu’il n’a jamais rencontrées et à savoir si celui-ci pourra être utile à l’entreprise STAR.
Un des scores nous permettant d’évaluer la performance de notre modèle est la MAE ou Mean Absolute Error. Cette valeur est simplement l’erreur moyenne de notre modèle. Nous trouvons une valeur de 668. Ainsi, notre modèle se trompe en moyenne de 668 personnes quand il prédit la fréquentation sur la ligne a. Cette valeur peut paraître énorme, mais elle est un peu plus acceptable quand on la compare avec la fréquentation moyenne qui est autour de 10 000. Mais, notre modèle n’a au final pas l’air d’être assez performant pour imaginer qu’il serait utile à l’entreprise STAR.
Un modèle non déployable en l’état
En creusant un peu plus, on se rend compte que ces erreurs ne sont pas du tout négligeables à côté des valeurs de variations de fréquentation. Dans ces conditions, il n’est pas envisageable que ces prédictions soient utilisées pour modifier le nombre de rames lorsque ces mêmes prédictions se trompent en moyenne d’autant que la variation de fréquentation pour la période donnée. L’entreprise STAR serait alors amenée à ajouter des rames en prévision d’une variation qui n’existe pas, ou au contraire de ne pas rajouter de rames là où le modèle n’a pas réussi à anticiper une variation de fréquentation.
Nous pouvons envisager d’améliorer notre modèle pour prédire plus précisément les variations de fréquentations en cherchant des facteurs supplémentaires pouvant influencer la fréquentation du métro a, ou encore améliorer l’approximation des moyennes de fréquentation par période (et donc des variations de fréquentation) par une analyse des tendances saisonnières plus poussée.
Sources
[2] Union des Transports Publics et Ferroviaires (UTP). (2022). Observatoire de la mobilité 2022 (p. 12). UTP. https://www.utpf-mobilites.fr/system/files/2022-11/20220927_dp_observatoire_de_la_mobilite_v2.0.pdf
[3] https://data.explore.star.fr/explore/dataset/tco-billettique-frequentation-detaillee-td/table/
[4] https://www.data.gouv.fr/fr/organizations/meteo-france/#/datasets