Une problématique cruciale dans le football moderne
Aujourd’hui le football fait face à une crise liée à un calendrier de matchs de plus en plus dense et aux blessures qui en découlent. La FIFPRO, le syndicat mondial des joueurs, tire la sonnette d’alarme : lors de la saison 2020-2021, 72% des footballeurs professionnels dans le monde ont dépassé le seuil critique de 55 rencontres par saison, un niveau qui met en danger leur intégrité physique.
Cette problématique est d’autant plus critique que les calendriers continuent de se densifier, augmentant les risques de blessures et impactant directement la performance des équipes.
Quelques chiffres-clés illustrant l’ampleur du problème
Plus de 7 joueurs sur 10 ont dépassé le seuil critique de matchs par saison.
Le coût moyen des blessures pour un club de Premier League est de 45 millions de livres par saison.
Augmentation de 20% des blessures musculaires entre 2016 et 2023 dans les 5 grands championnats européens.
82% des joueurs pensent que le calendrier actuel a un impact négatif sur leur santé physique et mentale.
Sources : FIFPRO Player Workload Report, UEFA Elite Club Injury Study, Premier Injuries Annual Report.
La solution : l’analyse de données au service de la récupération physique
Notre approche se fonde sur l’analyse de données pour aider les préparateurs physiques à aménager les entraînements et les temps de récupération des joueurs, afin de prévenir les blessures. Nous avons exploité trois jeux de données complémentaires:
Performances en match : nombre de minutes jouées, nombre de matchs disputés, statistiques individuelles (sprints, dribbles, buts, etc.).
Blessures : dates de début et de fin des blessures, leur nature et nombre de matchs manqués.
Caractéristiques des joueurs : taille, poids, date de naissance, poste.
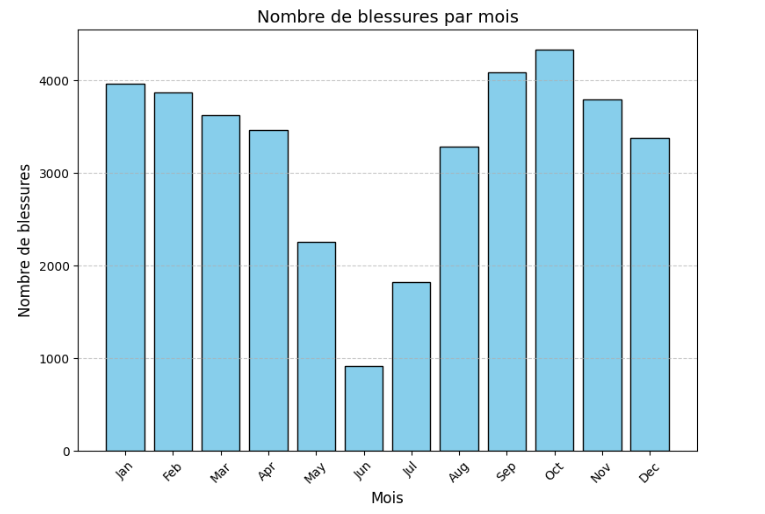
Ces données, regroupant 5097 joueurs sur 4 saisons des 5 grands championnats européens, nous ont permis d’identifier les facteurs de risques et de développer des modèles prédictifs. Nous avons constaté un volume élevé de blessures mensuelles, avec environ 4000 blessures recensées sur notre échantillon (cf. Fig. 1).
Fig. 1 : Graphique du nombre de blessures par mois
Grâce à notre analyse exploratoire des données, nous avons constaté un déséquilibre entre nos classes.
Transformer les données brutes pour prévenir les blessures
L’objectif de notre projet est d’identifier les facteurs clés liés aux blessures et de développer un modèle prédictif capable d’anticiper les risques de blessure dans les 30 prochains jours. Pour cela, nous avons créé de nouvelles variables:
Temps écoulé depuis la dernière blessure
Nombre de matchs joués sur différentes périodes (7, 30, 90, 365 jours)
Nombre de matchs consécutifs
Nombre de blessures par type
Intensité des matchs
Âge et IMC du joueur
Traitement des données : les valeurs extrêmes et les valeurs manquantes ont été gérées pour optimiser l’identification des patterns.
Suppression de données : les jeunes joueurs avec peu de minutes jouées, sans historique de blessures, ont été retirés des datasets.
Gestion des joueurs sans blessures : pour les joueurs sans blessures mais avec suffisamment d’informations, la variable « Temps écoulé depuis la dernière blessure » a été attribuée avec un temps maximum.
L’approche : des modèles de classification pour anticiper les risques
Dans le monde du sport professionnel, chaque blessure peut avoir des conséquences majeures : absence prolongée des joueurs, impact sur les performances de l’équipe, et coûts élevés pour les clubs. Mais imaginez si l’on pouvait prédire ces risques avant qu’ils ne se produisent ?
C’est précisément l’objectif de notre démarche : utiliser des modèles d’intelligence artificielle pour analyser les données des joueurs et anticiper leurs risques de blessures.
Nous avons testé plusieurs algorithmes de classification supervisée:
Régression logistique
Classificateur Naive Bayes
Random Forests
XGBoost
SVM
Résultats et choix du modèle : XGBoost, le champion de la prédiction des blessures.
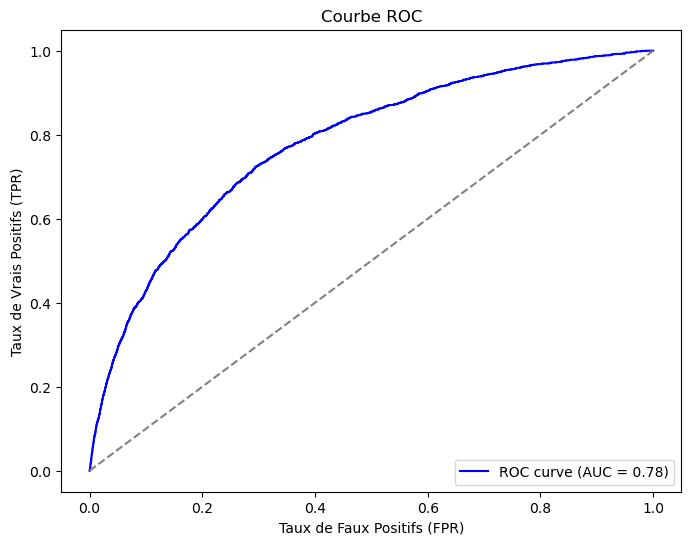
Après une évaluation rigoureuse, le modèle XGBoost optimisé avec Grid Search s’est avéré le plus performant, avec une accuracy de 70% et une surface sous la courbe AUC-ROC de 0.78 (cf. Fig. 2). Il est de plus bien adapté aux classes déséquilibrées.
Fig. 2 : Courbe ROC pour XGBoost avec GridSearch
Ce modèle offre la meilleure capacité de détection des joueurs à risque de blessure. De plus, les joueurs en bonne santé ne sont pas faussement classés comme blessés.
Impacts et recommandations : protéger les joueurs, améliorer la performance
Notre modèle permet d’anticiper les risques de blessure, offrant ainsi aux préparateurs physiques un outil précieux pour optimiser la gestion des joueurs. Voici quelques recommandations clés fondées sur nos analyses:
Limiter la charge cumulée de jeu (par exemple, 200 minutes sur 7 jours)
Garantir un repos minimum de 48 heures entre 2 matchs intenses
Planifier les rotations en fonction des charges cumulées et des prévisions de risques
Ainsi, l’utilisation de notre modèle XGBoost permet un gain de 5% dans la détection des blessures, sans pour autant augmenter le nombre de faux positifs, ce qui préserve l’effectif disponible pour l’entraîneur.
Perspectives d’amélioration : vers une prédiction encore plus fine
Bien que notre modèle soit performant, des améliorations sont possibles. Il serait intéressant d’intégrer davantage de données, comme :
Les conditions météorologiques, le type de terrain
Le niveau de stress des joueurs, leur nutrition, les antécédents de blessures
Les données d’entraînement et de récupération
Le style de jeu des équipes adverses
Nous envisageons également d’implémenter des modèles plus adaptés au déséquilibre des classes, comme les réseaux de neurones. Le développement d’une interface visuelle pour faciliter l’interprétation des risques est aussi une priorité.
Conclusion : un avenir plus sûr et plus performant pour le football
Notre projet démontre comment la data science peut révolutionner le football professionnel en permettant une meilleure anticipation des blessures et une optimisation de la gestion des joueurs. L’algorithme XGBoost développé s’est avéré être un outil précieux pour prédire les risques de blessures avec une amélioration de 5% par rapport aux méthodes existantes.
En intégrant davantage de données et en collaborant étroitement avec les acteurs du football, nous pouvons bâtir un avenir où les joueurs seront mieux protégés et les équipes plus performantes.
Les transports en commun sont aujourd’hui parmi les principaux moyens de transports quotidiens en France. Aujourd’hui, 22% de la population française utilise les transports en commun dans leurs trajets quotidiens [1].
Comment pouvons nous rendre plus agréable ces trajets quotidiens et améliorer la vie de plus d’1/5 des français ?
Un besoin de visibilité sur le réseau
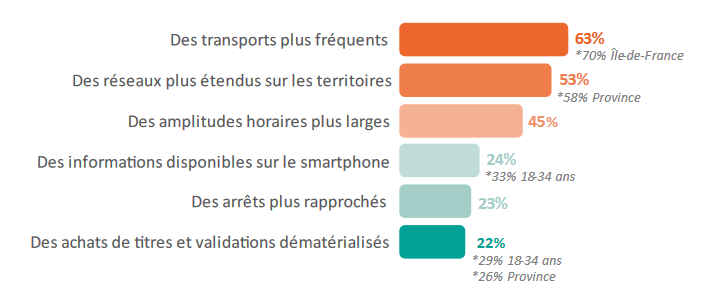
En interrogeant les utilisateurs des réseaux de transports en communs en France [2], il apparaît que ceux-ci aimerait en priorité des transports plus fréquents (Fig.1).
Fig. 1 Les avantages des transports publics selon les Français en 2022 [2].
Cependant, il est préférable pour les gestionnaires de réseaux d’allouer plus de transports lorsqu’ils en ont vraiment besoin, comme lors de fortes variations de fréquentation. Au-delà des variations dues à l’heure ou au jour, la météo pourrait être un facteur influençant la fréquentation des transports en commun. On s’imagine facilement que lors d’un jour pluvieux par exemple, des personnes se rendant normalement au travail à pied préfèrent le bus ou le métro. Rennes étant une ville assez pluvieuse et dont les données du réseau régi par l’entreprise STAR sont accessibles librement, ce sera sur cette ville que nous explorerons cette idée.
Nous cherchons donc à fournir à l’entreprise STAR à Rennes des prédictions de variation de fréquentation en prenant en compte les données météos pour que celle-ci adapte le nombre de transport en conséquence.
Des variations de fréquentation saisonnières
Pour répondre à notre problème, il nous faut donc tout d’abord des données sur la fréquentation des lignes du réseau STAR. Nous nous procurons sur le site de STAR une base de données de fréquentation relevée toutes les 15 min [3]. Il nous faut en effet des relevés assez fréquents pour prédire la fréquentation à des heures précises et pouvoir adapter le nombre de transports en conséquence plus précisément.
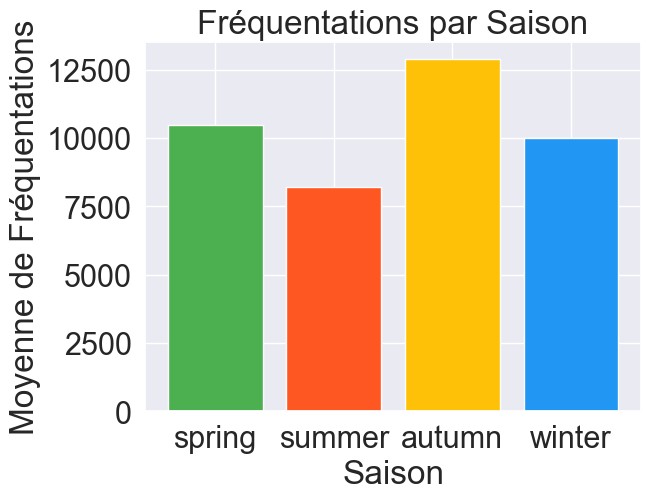
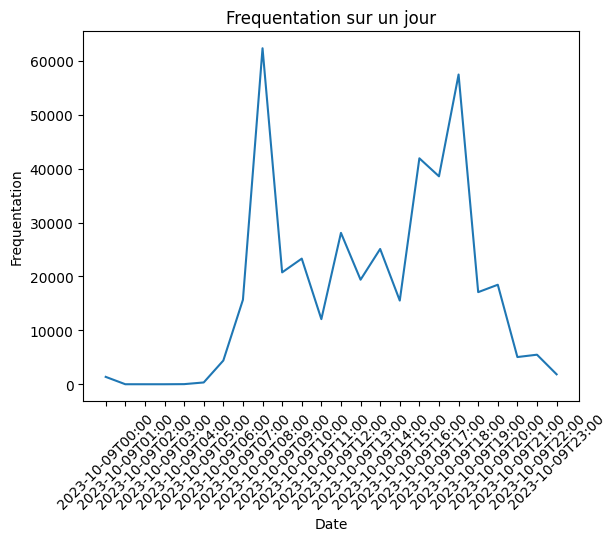
En analysant ces données, on voit apparaître des tendances saisonnières sur la fréquentation du réseau. On remarque notamment des différences en fonction de la saison (Fig.2) ou de l’heure (Fig.3). On observe aussi évidemment une baisse de fréquentation le week-end et les jours de vacances scolaires.
Fig. 2 : Moyenne de fréquentation par saison
Fig. 3 Fréquentation moyenne sur une journée
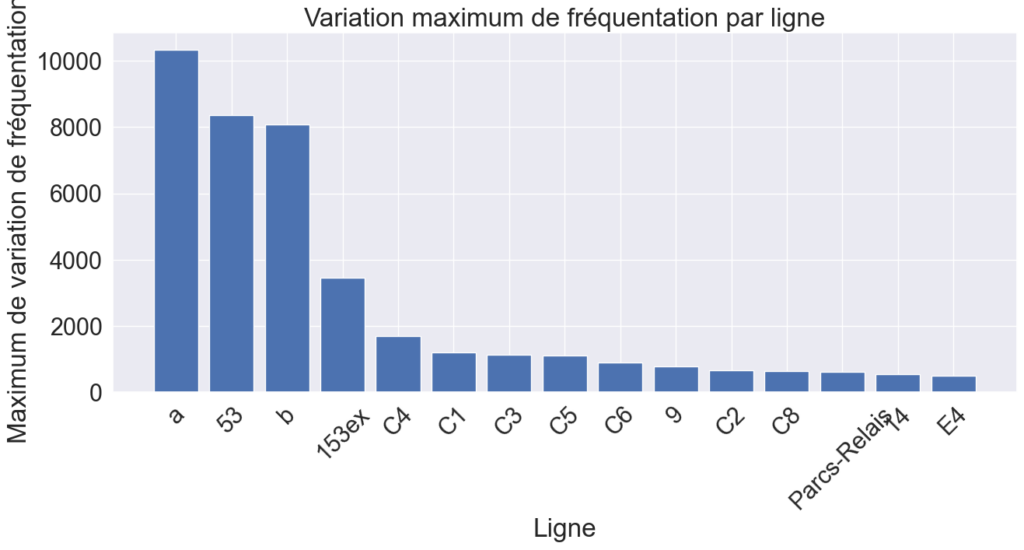
Pour savoir sur quelle ligne de transport il serait le plus nécessaire de moduler le nombre de transports en fonction de la fréquentation, on affiche les variations de fréquentation maximales par ligne (Fig.4) calculées par rapport à des fréquentations moyennes sur les différentes périodes. On voit bien que les variations les plus importantes du nombre de passagers se situent sur le métro a. Ajoutez à ça que cette ligne est automatique, celle-ci apparaît comme la candidate parfaite pour notre étude. On ne s’intéresse donc maintenant qu’à cette ligne dans la prédiction de la variation de fréquentation en fonction de la météo. Mais pour cela, il nous faut des relevés de météo.
Fig. 4 : Variation maximale de fréquentation par ligne
Une multitude de données météo
Nous trouvons un dataset Météo France [4] qui nous fournit des relevés horaires d’une station proche de Rennes. Ces mesures vont de la température à l’humidité en passant par la puissance du vent.
On s’assure rapidement que nos données sont cohérentes et que l’on utilise pas un jeu de données complètement faux avant de relier ces données météo à nos données de fréquentations.
Qu’en est-il du lien entre fréquentation et météo ?
Pour analyser le lien entre la météo et la fréquentation, on regroupe nos deux jeux de données en un plus grand dans lequel on associe pour chaque heure de chaque jour les relevés météo et la fréquentation associés.
On calcule alors des coefficients de corrélation entre la fréquentation et les données météos. Nous ne trouvons aucune variable météo qui expliquerait seule les variations de fréquentation, mais certaines valeurs de corrélations non négligeables nous laissent présager que l’association de toutes les données météos pourrait nous permettre de prédire efficacement ces variations.
Cependant, aucun lien n’apparaît entre nos données météo et la variation de fréquentation. Ainsi, nous décidons de prédire premièrement la fréquentation grâce aux données météos, puis nous calculons la variation de fréquentation en comparant la valeur de fréquentation et la valeur moyenne de fréquentation associée.
Comment prédire ces fréquentations ?
Nous essayons de prédire une variable cible : la fréquentation. Pour cela nous utiliserons donc un algorithme d’apprentissage supervisé qui prendra la forme d’un modèle de régression.
Un algorithme d’apprentissage supervisé s’entraîne, sur des données collectées, à prédire la variable cible à partir d’autres variables, dans notre cas les relevés météos. Il ajuste son fonctionnement au cours de l’apprentissage pour améliorer ses prédictions. Il peut lui-même savoir s’il se trompe ou non car il peut comparer sa prédiction avec la réponse attendue qui est comprise dans le jeu de données.
Un modèle de régression est simplement un algorithme qui prédit une valeur numérique (qui peut prendre n’importe quelle valeur). C’est l’opposé d’un modèle de classification qui prédit une valeur parmi un ensemble de plusieurs valeurs définies (chaque valeur étant associée à une classe)
Il existe une multitude d’algorithmes d’apprentissage supervisé utilisables pour faire de la régression. Nous devons donc tous les tester pour choisir le meilleur qui sera choisi comme algorithme final.
Est-ce que ces modèles sont performants ?
On compare premièrement la performance des différents modèles de prédiction sur une petite partie des nos données, appelée échantillon de validation. Le modèle le plus performant est le Gradient Boosting. Nous le choisissons donc comme notre algorithme final. Cet algorithme a un fonctionnement assez simple : il corrige petit à petit son erreur de prédiction par rapport à la valeur qu’il aurait dû trouver. Il estime à chaque itération cette erreur et la retire au résultat final, d’où son utilité dans notre cas d’une valeur continue.
Nous entraînons notre modèle final avec le reste de nos données, tout en gardant une petite partie de nos données restantes comme échantillon de test. Ce dernier nous permet alors d’obtenir la performance de notre modèle final sur des données qu’il n’a jamais rencontrées et à savoir si celui-ci pourra être utile à l’entreprise STAR.
Un des scores nous permettant d’évaluer la performance de notre modèle est la MAE ou Mean Absolute Error. Cette valeur est simplement l’erreur moyenne de notre modèle. Nous trouvons une valeur de 668. Ainsi, notre modèle se trompe en moyenne de 668 personnes quand il prédit la fréquentation sur la ligne a. Cette valeur peut paraître énorme, mais elle est un peu plus acceptable quand on la compare avec la fréquentation moyenne qui est autour de 10 000. Mais, notre modèle n’a au final pas l’air d’être assez performant pour imaginer qu’il serait utile à l’entreprise STAR.
Un modèle non déployable en l’état
En creusant un peu plus, on se rend compte que ces erreurs ne sont pas du tout négligeables à côté des valeurs de variations de fréquentation. Dans ces conditions, il n’est pas envisageable que ces prédictions soient utilisées pour modifier le nombre de rames lorsque ces mêmes prédictions se trompent en moyenne d’autant que la variation de fréquentation pour la période donnée. L’entreprise STAR serait alors amenée à ajouter des rames en prévision d’une variation qui n’existe pas, ou au contraire de ne pas rajouter de rames là où le modèle n’a pas réussi à anticiper une variation de fréquentation.
Nous pouvons envisager d’améliorer notre modèle pour prédire plus précisément les variations de fréquentations en cherchant des facteurs supplémentaires pouvant influencer la fréquentation du métro a, ou encore améliorer l’approximation des moyennes de fréquentation par période (et donc des variations de fréquentation) par une analyse des tendances saisonnières plus poussée.
Avec un taux de criminalité de 33 pour mille habitants et plus de 8 millions de crimes enregistrés depuis 2001, Chicago figure parmi les villes les plus touchées par la criminalité en Amérique.
Quels facteurs influencent la criminalité dans cette métropole ?
Inspiré par des recherches analysant la relation entre l’éducation et la criminalité notre projet explore l’influence des écoles sur la sécurité urbaine.
Répartition géographique des écoles et des incidents criminels à Chicago – Source des données : Chicago Data Portal
Des études au préalables ont montré que les caractéristiques des écoles, telles que les activités parascolaires, la nature de l’école et les heures de cours, peuvent avoir un impact significatif sur la délinquance et la criminalité indépendamment du contexte social et démographique.
Notre objectif est de développer un modèle de Machine Learning prédictif qui évalue l’impact potentiel de la construction des nouvelles écoles sur le taux de criminalité sur une période de sept ans, offrant ainsi des perspectives innovantes afin d’explorer comment l’éducation peut influencer la sécurité urbaine à Chicago.
Données utilisées
Répartition géographique des écoles et le rayon d’impact des incidents criminels à Chicago – Source des données : Chicago Data Portal
Notre étude s’appuie sur des données publiques issues du Chicago Data Portal, qui est géré par la municipalité de la ville. Nous avons analysé sept jeux de données relatifs aux établissements scolaires de 2016 à aujourd’hui, ainsi qu’un jeu de données sur les crimes enregistrés de 2001.
L’objectif est d’évaluer l’impact des écoles sur le taux de criminalité dans un rayon de 1 km autour de celles-ci, sur une période allant jusqu’à sept ans.
Pour cela, nous avons créé des jeux de données croisés permettant d’analyser l’évolution annuelle de la criminalité par rapport à l’année de référence 2016 :
Dataset 1 : écoles 2016 ↔ crimes 2017
Dataset 2 : écoles 2016 ↔ crimes 2018
Dataset 3 : écoles 2016 ↔ crimes 2019
Dataset 4 : écoles 2016 ↔ crimes 2020
Dataset 5 : écoles 2016 ↔ crimes 2021
Dataset 6 : écoles 2016 ↔ crimes 2022
Dataset 7 : écoles 2016 ↔ crimes 2023
Regardons les données de plus près : Analyse des corrélations
Matrice de corrélation des variables du jeu de données fusionné
Pour résumer les corrélations des données analysées, nous pouvons dire que les corrélations entre les variables étudiées et le taux de criminalité sont relativement faibles.
Cela confirme l’hypothèse selon laquelle le taux de criminalité est influencé par une multitude de facteurs autres que les seules politiques internes des écoles.
Toutefois, il semble exister une association plus marquée entre la présence d’écoles dans un quartier, le nombre d’étudiants, et le taux de criminalité plutôt qu’avec les caractéristiques propres à chaque établissement scolaire.
Construction du modèle
Algorithmes utilisés
Nous avons utilisé plusieurs modèles, y compris le Random Forest, SVM et des variantes de Boosting, pour identifier ceux qui prévoient le mieux les taux de criminalité future.
Les modèles les plus performants, jugés sur la base de leur erreur moyenne absolue (MAE) et de l’erreur quadratique moyenne (RMSE), ont été combinés pour créer un modèle composite robuste.
Ce modèle est adapté pour prédire l’évolution de la criminalité sur une période allant jusqu’à sept ans.
Validation
Pour garantir la fiabilité de nos modèles prédictifs, nous avons mis en place une validation croisée sur les modèles, chacun comprenant environ 655 lignes.
Cette technique permet de s’assurer que nos algorithmes généralisent bien au-delà des données d’entraînement et ne mémorisent pas simplement les données (overfitting).
Les résultats de cette validation croisée ont confirmé l’efficacité de nos modèles, avec une diminution des erreurs.
L’analyse de l’importance des variables, issue de nos modèles et tenant compte des corrélations limitées, révèle que la :
le taux de criminalité est davantage lié à la proximité des établissements scolaires qu’à leurs politiques internes comme les codes vestimentaires ou les programmes parascolaires.
Cette divergence par rapport aux articles identifiés souligne l’importance de prendre en compte le contexte local de chaque zone, avec les différents indicateurs démographiques.
Résultats ? Notre modèle offre une double fonctionnalité
Prédit l’évolution du taux de criminalité sur sept ans en se basant sur les données actuelles des écoles. Ainsi, il est capable de projeter l’incidence criminelle de 2024 à 2030 en utilisant les informations de 2023.
2. Simule l’effet de l’ajout d’une nouvelle école dans une zone spécifique (Latitude et longitude) et évalue l’impact sur la criminalité dans un rayon de 1 KM de l’école et les écoles à côté (en se concentrant sur les intersections des cercles).
Le modèle nous permet aussi de faire une comparaison de la situation des crimes avec et sans l’introduction d’une école avec des critères spécifique dans une zone donnée .
Nos simulations révèlent que l’extension des programmes parascolaires peut diminuer l’impact sur le taux de criminalité environnant.
Conclusion
Les résultats obtenus à travers notre modèle fournissent une base solide pour les décideurs locaux de Chicago afin de prendre des décisions en ce qui concerne la construction d’écoles dans des zones spécifiques.
Notre analyse a révélé aussi que l’impact des écoles sur la criminalité locale est complexe et ne repose pas uniquement sur les programmes éducatifs, soulignant l’importance d’intégrer d’autres facteurs lors de la planification de nouvelles infrastructures éducatives (postes de polices, état du quartier …) et de prendre en considération les indicateurs démographiques, la situation financière des étudiants recrutés par chaque école pour plus d’alignement avec les articles sur lesquels nous avons basés nos hypothèses..
Les insights fournis par notre étude offrent des pistes prometteuses pour des stratégies urbaines plus éclairées. Pour aller de l’avant, il serait judicieux d’envisager une approche collaborative impliquant éducateurs, autorités locales, et communautés pour bâtir un environnement plus sûr. Finalement, cette recherche ouvre la voie à des études supplémentaires qui pourraient explorer des interventions ciblées et personnalisées, contribuant ainsi à la transformation positive de Chicago.
Références
Crews, G. (2009). Education and crime. In J. M. Miller 21st Century criminology: A reference handbook (pp. 59-66). SAGE Publications, Inc., https://www.doi.org/10.4135/9781412971997.n8
Gottfredson et al., (2004). « Do After School Programs Reduce Delinquency? »
Willits, Broidy, et Denman, « Schools, Neighborhood Risk Factors, and Crime ».
As we travel through the Earth, we can notice the symphony we hear all around, from the smallest grain of sand, to the faraway planets, to a flower putting roots in the ground, every bird in the sky, every rock, and every raindrop as it falls from the clouds, every ant, every plant, every breeze, and all the seas contribute to this beautiful composition. However, within this natural orchestra, there’s a dangerous problem that demands our attention — ‘Global Warming’.
With the variation of the temperature over recent decades, the agriculture is considered as one of the most affected sectors by global warming. These environmental changes have disrupted the agricultural landscape, affecting both its ecology and economy.
Describing the impact of global warming on agriculture is a bit like exploring a big, diverse world map. Each country in this map has its own distinct climate, crops, and economic structures. This diversity is what makes our world interesting but also makes problem-solving a bit challenging.
This is where the idea of assessing vulnerability for countries takes center stage. Consider Vulnerability as a measure of how susceptible a country is to the challenges posed by global warming in the sector of agriculture.
Some countries may be more resilient, while others may face high risks due to their specific circumstances which make them vulnerable countries. Our challenge: predict the vulnerability of the countries by 2030.
Given the crucial role of non-governmental organizations (NGOs) to address the effects of global warming on agriculture, our primary focus goes beyond identifying the most vulnerable countries, we aim to predict this vulnerability by the year 2030 and foresee the difficulties before they happen. In that way, we can empower NGOs with pivotal information that may serves as initiatives for them to take action and tailor solutions and strategies before the things get too hard for vulnerable countries.
A data-driven definition of Vulnerability
To achieve this ambitious goal, we delved into the world of data. This exploration involves carefully choosing our data from a reliable, open- data source: ‘Food and Agriculture Organization of the United Nations’. We focus on Geography and Economics data, Environment Temperature Changes Data and Agriculture (Crop Yield) Data.
Geography and Economics data1: it underscores information related to percentage of the country area cultivated, Gross Domestic product (GDP), agriculture’s GDP contribution, total renewable water resources, and the national rainfall Index.
Environment Temperature Change Data2: it focuses on temperature change factor for different countries.
Agriculture (Crop Yields) Data3: it involves the production values for specific crop yields. All our datasets are meticulously organized, categorized by country and year.
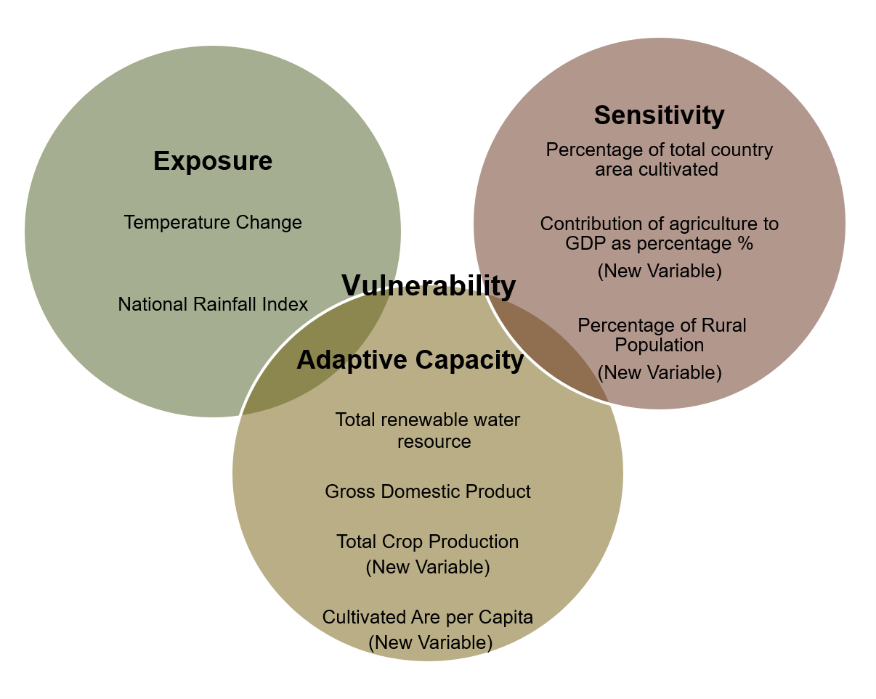
Inspired by cutting-edge research45, we’ve strategically organized our variables into three main components. Each component serves as a building block for our mission to assess vulnerability in the face of global warming’s impact on agriculture. Let’s delve into these components:
Exposure: How much the country is exposed to different climatic factors.
Sensitivity: How sensitive the agriculture in the area is to certain risks.
Adaptive Capacity: How well the area can adapt to and cope with the challenges posed by global warming.
We then attribute each variable to one of those three components as well as adding new variables to enhance our understanding.
Data Preparation
We started by preparing our datasets and transform them into refined insights in order to make them ready for future work.
Rename the countries and matching them: We begin by renaming and identifying matching countries across all datasets. This is a foundational step when merging all the datasets together.
Handling Missing Data: We address missing data using advanced techniques. The power of KNN imputation or zero imputation comes into play, ensuring our datasets are robust and comprehensive.
Creating New Variables: we succeeded to create new variables as outlined in the data organizing phase. This step play an important role in shaping our analysis.
Data Integration: Merging datasets together seamlessly, we ensure a unified view that enhances the effectiveness of our analysis.
Data Normalization: Recognizing the diverse nature of our variables, we implement normalization techniques for both positive and negative variables. Positive variable indicates a positive relation with vulnerability, while negative variable signify a negative relation. This step ensures fair treatment of climate and agriculture variables for accurate vulnerability assessment.
Assessing Global Vulnerability: How does it Work?
Since our goal is to identify the vulnerable countries in the face of global warming’s impact on the agriculture by 2030, we embark in another journey that requires a deep comprehensive of methodologies for calculating vulnerability, making predictions and providing insightful vulnerability classifications.
Our proposal: a Vulnerability index
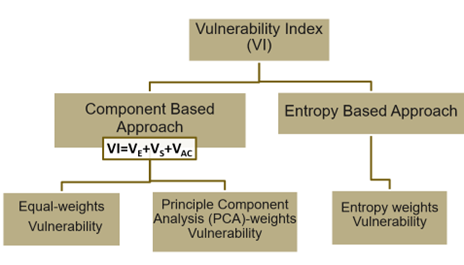
The key concept of assessing vulnerability of the countries was to create a new variable called ‘Vulnerability index’(VI). This calculation of this variable is based on two main approach that are taken from two innovative research.
As we organized our variables into three main components— Exposure(S), Sensitivity(S) and Adaptive Capacity (AC), we were seeking to calculate the vulnerability index by identifying the vulnerability of each component separately and than summing them up as illustrated in the figure. To achieve this, we assign weights to each variable attributed to one of these components. The weights represent the relative importance of each variable in the vulnerability index calculation.
We used two methods for assigning the weights: Equal weights method, where each variable is considered equally important and the Principle component Analysis (PCA) method, which involves mathematical techniques to capture the most critical information presenting in our data in a smaller set of components, then assigning weights based on the variables’ contribution to the first principal component. This dual-weighting strategy results in two different vulnerability indices: Equal -weights Vulnerability and Principle Component Analysis (PCA)- weights Vulnerability.
In contrast of the component-based approach, entropy-based approach simplifies the calculation of the Vulnerability Index by considering all the variables together. Measuring uncertainty and information content. The idea is to measure the uncertainty or information associated with each variable. This unique perspective on vulnerability, has a pivotal role in emphasizing variables that offer more certain and informative signals. We ended up after this approach, having Entropy-weights Vulnerability Index.
Making predictions
Having The three main Vulnrability indexes: Equal -weights Vulnerability and Principle Component Analysis (PCA)- weights Vulnerability and Entropy-weights Vulenrability, and recognizing the unique trajectories each country has followed, we decided to delve into the next phase: Prediction. In this step, we aim to predict our three vulnerability indices until the year 2030 by looking into the patterns and trends for each country. To achieve this, we used the ARIMA model, known as its suitability in short term-forecasting and capability in capturing temporal patterns8.
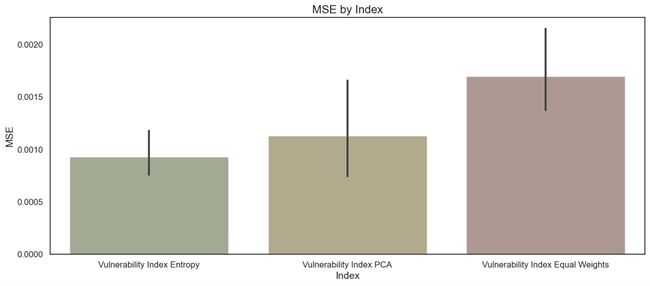
ARIMA model performance: negligible error values for all 3 indices
In order to evaluate the performance of the ARIMA model in making predictions for each of our vulnerability indices, we used the MEAN SQUARED ERROR (MSE) and MEAN ABSOLUTE ERROR (MAE) for evaluating our results. Thus, after exploring the results from the MSE measure from the figure below, we notice that the Entropy and PCA methods for calculating the vulnerability have a better performance than Equal Weights method. However, we can see that for all of those methods, we can consider that the error values are practically negligible.
Providing Vulnerability Classification
In this step, we looked forward to classify the countries based on the predictions’ values of each of their vulnerability indices. This involves categorizing countries based on their index values using the Percentile method. Countries below the 25th percentile of their vulnerability index is considered as Relatively non-vulnerable, those above the 75th percentile are considered as Relatively vulnerable , and the rest fall into Neutral Category. This classification provide us with a list of vulnerable countries for both 2020 and 2030 across all indices.
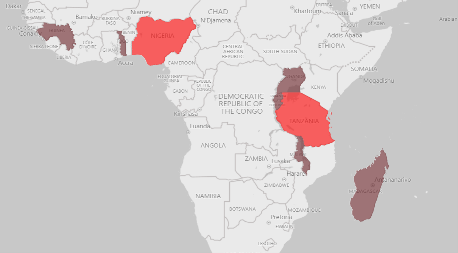
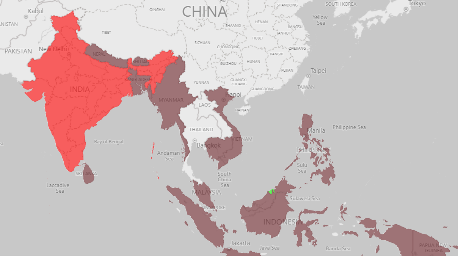
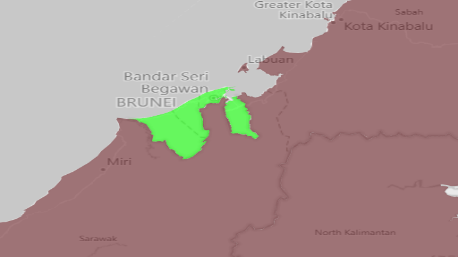
The figures above represent the vulnerable countries we got after extracting the common vulnerable countries from the classifications results of the three vulnerability indices. The countries in brown are the countries that remain vulnerable from 2020 to 2030, the red countries are the new countries that turn into vulnerable in 2030 and the green one is the country that improves its status from vulnerable to neutral by the year of 2030.
To see how the vulnerability index and the countries’ ranking have changed over years, we made an animated bar chart race to illustrate it. You can click here.
Turning Data into Action
As we navigate the impacts of global warming on agriculture, our journey has revealed insights into vulnerability across nations. We got a list of 24 vulnerable countries in 2020 and a list of 27 vulnerable countries in 2030 in which there are some countries that are going to be vulnerable in 2030 such as India, Nigeria, Tanzania and one country that will improve its status by the year of 2030: Brunei. With this information, we propose some strategies to the NGOs to take specific actions to support those countries indeed.
For those countries that remain vulnerable until 2030, NGOs can take some actions to improve their status by developing and implementing sustainable agriculture practices. This includes promoting efficient water management, soil conservation, and the adoption of climate-resilient crop varieties.
Countries that are going to be vulnerable by the year of 2030 need preemptive strategies. NGOs can collaborate to establish early-warning systems, support climate-smart agricultural practices, and facilitate knowledge exchange between nations that have successfully mitigated vulnerabilities. Moreover, NGOs can work on some factors in the Adaptive Capacity Components to avoid vulnerability like expanding cultivated areas, supporting population control measures, and boosting total production through research and innovation.
While our findings provide a valuable insights, acknowledging limitations is key. Expanding datasets, incorporating subjective insights, and focusing on specific crop vulnerabilities are our directions for future exploration. So let’s turn these improvements into actionable steps for a resilient and sustainable agricultural future.
Avec une population dépassant les 8 millions d’habitants, New York City se positionne parmi les villes les plus influentes en Amérique du Nord. Ville dynamique et en perpétuelle mutation, des réglementations ont été instaurées, restreignant le port d’armes à feu dans certaines zones. Néanmoins, ces mesures suscitent des débats au sein de la sphère politique de New York.
Cependant, malgré les restrictions, le nombre élevé de fusillades persiste au sein de la ville, avec plusieurs centaines d’incidents recensés au cours des dernières années. De plus, la constante évolution de la ville rend la planification urbaine de plus en plus complexe au fil du temps. Face à cette réalité, la problématique qui se pose est la suivante :
Peut-on améliorer la sécurité urbaine de New York City grâce à des initiatives d’urbanisation ?
Notre exploration de la littérature scientifique a rapidement corroboré l’existence de liens significatifs entre les crimes et les localisations, l’agencement et les types de bâtiments publics dans une zone donnée 1.
Guidés par cette idée, nous avons choisi d’apporter une solution à la problématique antérieure en exploitant nos compétences en science des données et en apprentissage automatique. L’objectif serait donc de pouvoir estimer l’impact de la construction de nouveaux bâtiments publics sur la criminalité environnante.
À la recherche d’indices
Pour répondre à notre problématique, nous sommes partis de deux jeux de données de la ville de New York. Le premier recense les fusillades dans la ville avec leurs localisations depuis 2006 et comporte un peu plus de 27 000 lignes 2. Le second nous donne accès aux plus de 30 000 bâtiments publics de la ville3 .
Nombre de tirs
Nombre de bâtiments publics
Les bâtiments sont regroupés selon 25 catégories différentes en fonction du domaine d’activité qui leur est lié : les plus nombreux sont ceux liés à l’enfance, aux transports et à la santé et les moins nombreux ceux liés aux télécommunications et à la justice. On peut observer ci-dessous quelle typologie de bâtiment est utilisée ainsi que le nombre de bâtiments de chaque type.
Répartition des types de bâtiments à New York
La tâche la plus dure à présent consiste à générer notre propre jeu de données pour établir les liens entre les bâtiments et les incidents de fusillade.
Comment lier nos indices entre eux ?
Pour cela, nous avons utilisé une approché basée sur les secteurs. Un secteur est une zone géographique dans laquelle nous recensons le nombre de chaque type de bâtiment ainsi qu’une mesure de la criminalité basée sur le nombre de fusillades.
Théoriquement, les secteurs peuvent adopter n’importe quelle forme, telle que celle des rectangles d’une grille par exemple, et possèdent une intersection qui peut être non-nulle : un chevauchement est donc possible.
Exemple de sectorisation (1304 secteurs de 1km x 1km)
Dans notre cas, nous avons utilisé des secteurs circulaires d’un rayon de 500 mètres, dont le centre est un bâtiment public de notre jeu de données Ainsi, pour chaque bâtiment nous obtenons un secteur : nous en avons donc au total plus de 30 000 ce qui sera très utile lors de l’entraînement des modèles.
La manière dont nous avons créé notre jeu de données est schématisée ci-dessous.
Méthode sectorisation circulaire
Dans le secteur centré autour de l’hôpital rouge, 5 tirs ont été tirés, dont 3 près d’une école, 1 près d l’hôpital, et 1 près du poste de police.
Sur cet exemple, nous avons additionné le nombre de tirs dans chaque secteur. En réalité, un traitement a été appliqué à ce nombre. En effet, plutôt que de parler en termes de nombre de tirs, ce qui est peu parlant – que signifierait “Placer un bâtiment ici a diminué le nombre de tirs de 2 sur 15 ans” ? – nous avons décidé de créer un indice évaluant la criminalité, basé sur le nombre de tirs.
Plus particulièrement, nous nous intéresserons à l’évolution de cet indice pour voir s’il est judicieux ou non d’implémenter un type de bâtiment public à un endroit donné : la différence entre avant et après la construction sera-t-elle positive ou négative ?
Pour cela, nous avons redimensionné la variable que nous cherchons à prédire (la mesure de criminalité) pour que ses valeurs soient comprises entre 0 et 1 de la manière suivante :
Appliquons cela à l’exemple vu précédemment. Il nous faut d’abord trouver les secteurs comportant le moins et le plus de tirs, correspondant donc respectivement à xmin et xmax de l’équation. Connaissant cela, nous pouvons maintenant appliquer la formule à toutes les valeurs.
Attribution de notre indice de criminalité à chaque secteur
Il nous semble important de mentionner pour les plus curieux d’entre vous que nous avons également choisi d’utiliser un index personnalisé de criminalité car il offre une adaptabilité et une possibilité d’affinement.
On pourrait donc pousser davantage notre réflexion et notre démarche en utilisant toutes ces données en pondérant notre index par le degré de gravité du crime. A titre d’exemple, un vol pourrait compter pour un facteur de 1 et un meurtre pour un facteur de 100.
Cependant, comment pouvons-nous être sûr de l’efficacité de notre outil ?
Élémentaire mon cher Watson
Pour valider la crédibilité de notre approche, nous allons avoir recours à un critère de réussite : si nous vérifions le critère alors notre approche sera considérée comme valide.
Comme critère de réussite, nous allons procéder à une comparaison avec une méthode dite élémentaire (ou naïve) de détermination de l’indice de criminalité. Cette dernière se contente de prédire pour chaque secteur la moyenne de l’indice de criminalité. Mathématiquement, cela donne :
Si l’on reprend l’exemple précédent, l’approche élémentaire devrait prédire :
Prédiction du modèle élémentaire sur notre exemple
Comme vous pouvez le constater, cette approche, plutôt médiocre, prédit des valeurs de l’indice de criminalité assez éloignées de la réalité.
Ainsi, si nous sommes plus performants que cette méthode simpliste, nous pouvons considérer que notre approche est fonctionnelle et peut donner lieu à une application concrète.
Pour y parvenir, nous avons sélectionné plusieurs métriques caractérisant l’erreur à minimiser, à savoir la MSE (Mean Square Error), la MAE (Mean Absolute Error) et la RMSE (Root Mean Square Error) ainsi qu’une métrique expliquant la qualité de notre modèle vis-à-vis de la variance, le R2 (R-Squared).
Par conséquent, en comparant ces métriques, nous serons en mesure de démontrer la supériorité de notre outil par rapport à la méthode naïve.
Le raisonnement
Nous avons implémenté différents modèles d’apprentissage automatique de régression pour pouvoir prédire l’indice de criminalité lors de la construction d’un nouveau bâtiment afin d’estimer l’impact sur la criminalité des nouvelles constructions.
Le but est donc, avec notre modèle, d’aider à la prise de décision les responsables de la planification urbaine de la ville de New York.
Nous nous sommes notamment penchés sur des Réseaux de Neurones et des Random Forest. Finalement notre choix s’est porté sur le Random Forest pour plusieurs raisons :
Premièrement, les résultats obtenus se sont révélés très prometteurs.
Ensuite, le temps d’exécution de notre algorithme restait raisonnable.
Enfin, cet algorithme nous permet d’avoir une vision plus précise de ce qui se passe avec notamment la possibilité de voir quelles données influencent le plus les prédictions, contrairement aux Neural Networks.
Le tableau ci-dessous nous montre bien les résultats obtenus à travers nos différents modèles. Nous remarquons aussi par ailleurs que nous validons largement notre critère de réussite.
Métriques
Random Forest
Neural Network
Modèle Naïf
MSE
0.00092
0.00340
0.02581
MAE
0.01519
0.04014
0.12742
R2
0.96446
0.86806
– 0.00005
RMSE
0.03029
0.05835
0.16067
Comparaison des modèles: toutes les métriques d’évaluation classent le Random Forest au premier rang
Graphique montrant l’importance de chaque feature pour notre modèle Random Forest
Comment résoudre l’enquête ?
Imaginons que vous êtes un planificateur urbain et que votre mission serait de construire une maison de jeu pour enfants.
Vous hésitez fortement entre 3 localisations que vous avez identifiées comme favorables selon des critères divers et variés.
Vous souhaitez prendre en compte l’impact de cette nouvelle construction sur la criminalité environnante ?
C’est ici que notre solution intervient.
Application du modèle sur 3 localisations réelles
Nos données nous fournissent l’indice de criminalité avant la construction, puis notre modèle prédit l’indice de criminalité après la construction de la maison de jeu pour enfants. Enfin, nous observons dans la dernière colonne ci-dessus l’évolution de cet indice de criminalité. Dans le cas présent la localisation C semble être le meilleur choix d’implantation si nous regardons le problème à travers le prisme de la criminalité.
Le verdict
Comme résultat, cet outil d’apprentissage automatique se positionne comme un allié de choix dans la prise de décision pour la planification urbaine à New York City, avec des performances élevées et aussi des opportunités d’amélioration.
Les résultats de l’évaluation de notre modèle, le RandomForest, ont surpassé nos attentes initiales. Sa précision remarquable dans la mesure de la criminalité, évaluée à travers les critères des erreurs à minimiser, ainsi que les indications détaillées sur l’importance de chaque caractéristique, confèrent à notre modèle une valeur exceptionnelle.
Cependant, il est essentiel de maintenir une approche prudente dans ce contexte. La planification urbaine est influencée par de multiples facteurs et ne peut se limiter à la seule considération de la criminalité. Par conséquent, bien que notre outil soit efficace, il doit être considéré comme une assistance à la prise de décision plutôt que comme une solution autonome pour les responsables de l’urbanisation.
Prise de recul
Malgré le succès évident de notre solution, nous sommes conscients de l’existence de tendances potentiellement risquées qui pourraient émerger en cas d’utilisation inappropriée de notre solution.
La première de ces tendances est la standardisation du type de construction à travers tous les secteurs, en se concentrant sur le type de construction ayant le plus grand impact sur l’indice de criminalité. Un certain point de saturation serait alors atteint, rendant notre modèle obsolète.
La seconde tendance impliquerait un déplacement à plus ou moins long terme de la criminalité. En effet, déplacer un problème vers une autre localisation ne le résout pas réellement. Cette réalité est malheureusement largement reconnue par ceux qui s’efforcent de réduire les taux de criminalité.
Et après ?
Plusieurs pistes d’amélioration ont été identifiées.
Diminution globale de la criminalité : Nous pourrions aller jusqu’à suggérer des emplacements d’implémentations de bâtiments publics plutôt que de simplement comparer des emplacements suggérés par les planificateurs urbains pour tenter de diminuer globalement la criminalité à New York.
Généralisation du modèle : l’intégration de jeux de données provenant d’autres villes nord-américaines pourrait enrichir notre modèle, entraînant ainsi une amélioration de ses performances et rendant la généralisation à la plupart des grandes villes américaines possible.
Amélioration des performances : la littérature suggère des liens significatifs entre la criminalité et le mouvement de population dans un secteur donné, rendant l’accès à des données de flux particulièrement valorisant.
Amélioration des performances et déplacement de la criminalité : l’inclusion d’informations sur l’année de construction des bâtiments permettrait d’apporter une dimension temporelle à notre modèle, gagnant ainsi en efficacité. Ceci permettrait également de quantifier le déplacement de la criminalité en voyant l’impact historique de l’implémentation des bâtiments sur la criminalité dans la ville.
Références
Urban Planning and Environmental Criminology: Towards a New Perspective for Safer Cities, Cozens, P. M. (2011) ↩︎
Inscrite au patrimoine mondial immatériel de l’UNESCO, la gastronomie française tient une place spéciale dans le cœur des français. L’art du “bien boire” et du “bien manger” est ancré profondément dans nos coutumes, tant et si bien que pour de nombreux français le vin et les repas cuisinés sont indissociables : 90% des repas avec invités ont une bouteille de vin à table, 92% des français associent l’image du vin à un plat, 88% associent le vin à la convivialité et au partage,…ces chiffres de l’IFOP Vins&Société ont de quoi vous donner le tournis !
Quelques chiffres sur les relations entre vin et repas
Mais si, vu de l’étranger, tout français maîtrise cet art de vivre dès la naissance, la réalité est toute autre : plus qu’un art, être capable de proposer à ses convives un repas dont les saveurs sont sublimées par une gorgée de la judicieuse bouteille de vin que vous aurez choisi pour l’accompagner est une science. Qui ne s’est jamais retrouvé dans cette situation : vous invitez vos amis à dîner chez vous, passez de nombreuses heures à étudier les recettes Marmiton à la recherche de l’inspiration, sélectionnez LA recette parfaite, partez en courses, dénichez les ingrédients nécessaires, arrivez enfin au rayon vins de votre supermarché favori et là… c’est le drame. Vous vous retrouvez devant ce mur de bouteilles et vous n’avez aucune idée de laquelle choisir. Blanc pour le poisson, rouge pour la viande : c’est bien beau tout ça, mais ça laisse quand même beaucoup d’options. Finalement, par dépit, vous partez avec une bouteille assez chère (c’est gage de qualité) et dont le design vous aura attiré l’œil. Si vous vous reconnaissez ici, vous connaissez la suite : l’accord entre votre repas et votre bouteille a de forte chance d’être hasardeux.
Sommes nous condamnés à cette incertitude, à ce pic de stress additionnel à chaque grande occasion dont nous sommes les hôtes, nous cuisiniers amateurs n’ayant pas eu la chance de naître avec un oncle sommelier ? Peut-être pas.
Et si notre meilleur ami Marmiton venait à notre rescousse et nous suggérait la bonne bouteille pour la recette que vous venez de précieusement enregistrer dans vos favoris ?
Marmiton à la rescousse…c’est possible ?
Pourquoi diable Marmiton irait vous proposer une telle fonctionnalité ?
Tout d’abord parce que c’est une fonctionnalité qui s’inscrit parfaitement dans les valeurs de l’entreprise, à savoir plaisir, générosité, accessibilité et convivialité.
Ensuite parce que c’est une fonctionnalité innovante non présente chez ses concurrents qui potentiellement améliorerait l’expérience utilisateurs de ses clients (on est quand même pas les seuls à vouloir une telle fonctionnalité, si ?).
Enfin et surtout, parce que cela permettrait de générer de nouveaux revenus de partenariat avec des vendeurs de vins en ligne en échange de nouveaux canaux d’acquisition de clients pour eux.
Alors, pourquoi pas ?
Et techniquement, c’est réalisable ?
Comment s’y prendrait-on si l’on voulait mettre en place ce type de service ? C’est l’excellente question à laquelle nous avons essayé de répondre. Tout d’abord il faudrait mieux comprendre comment se réalisent les accords mets – vins : sur quels critères gustatifs se réalisent ils ? Quels ingrédients prennent le dessus sur d’autres ? Quel est l’impact de la cuisson des plats ? Comment caractérise-t-on les vins ? Qu’est ce qui différencie une appellation d’une autre ? …autant de questions qui restent sans réponse.
Quelques lectures plus tard, on commence à y voir (un peu) plus clair : les poissons et les viandes sont souvent l’élément décisionnaire de l’accord de vin pour un plat, ces derniers peuvent être caractérisés gustativement par leurs types de cuissons, les vins ont des caractéristiques tanniques, de fraîcheur ou encore de rondeur du fait de leurs cépages, de leur sol…
Si on peut caractériser des recettes et des vins par autant d’attributs, ne pourrait-on pas faire ressortir des corrélations qui permettent de proposer un accord pertinent pour une recette donnée ? Ne pourrait-on pas appliquer des méthodes de Data Science pour recommander ces accords mets-vins ?
Des données, des données et encore des données
Afin de vérifier ces hypothèses, il nous faut des données sur des accords mets et vins. Malgré le bien fondé de l’existence d’une telle base de données (surtout lorsque la période des fêtes approche à grands pas), il s’avère qu’il n’en existe pas. Afin de pallier ce problème, nous avons retroussé nos manches et commencé à constituer une base de données en utilisant une méthode à la limite de la légalité afin de collecter des données sur internet : le scrapping. Ces techniques, tolérées à des fins éducatives ou de recherche, permettent d’utiliser des robots qui parcourent le code des pages web afin de collecter les données qui y figurent.
Après des dizaines d’heures et quelques centaines de lignes de codes, le dataset est constitué :
les attributs des recettes (leur intitulé, la catégorie de plat associé et les ingrédients utilisés) sont collectés sur Marmiton,
ceux des vins (scores sur les goûts notamment le caractère tannique ou frais, les taux de sucre, les cépages, les appellations et leur description “sommelière” notamment) sur Nicolas et V&B,
et les bons accords mets vins sont tirées de l’ouvrage de Olivier Bompass, Les Vins et les Mets en 2500 Accords (on y trouve un nom de recette auquel est associé sa catégorie de plat, la typologie de vins suggérés – e.g. rouge, blanc..-, une description gustative des vins et des appellations correspondantes).
Au travail maintenant !
Data Science : du buzzword aux méthodes concrètes
Dire que l’on va appliquer des méthodes de Data Science n’apporte pas beaucoup d’informations sur la manière de modéliser et traiter le problème. Afin de recommander une bouteille de vin à partir d’une recette, nous avons envisagé différentes traductions en problèmes de Data Science : nous en détaillerons ici deux.
La première consiste à développer un système de recommandations basé sur une analogie au principe de Content-Based Filtering : une recette de notre base d’accords se marie bien à certains vins, la recette fournie par l’utilisateur est similaire à cette recette, donc potentiellement les mêmes vins pourraient lui convenir.
Première approche de système de recommandation
La seconde consiste à effectuer un apprentissage supervisé qui prend en entrée les attributs de la recette et la classifie selon le type de vin qui lui correspond le mieux (à un niveau basique sur la typologie, et pour aller plus loin sur la description gustative).
Seconde approche d’apprentissage supervisé
Ces deux approches nécessitent d’exploiter des données textuelles, notamment celles contenues dans les intitulés des recettes et dans les listes d’ingrédients. Afin de permettre aux algorithmes d’utiliser ces données, il nous a fallu utiliser des méthodes de NLP (Natural Language Processing, un champ du Machine Learning qui permet de traiter les langages) afin de les encoder sous formes de vecteurs pour pouvoir par la suite effectuer des calculs dessus. Concrètement, après un pré-processing des données afin d’isoler les termes les plus porteurs de sens des textes, il s’agit de choisir la méthode de vectorization la plus adaptée à leur contexte pour les représenter : c’est l’étape de « Word Embedding ».
Champagne…?
Les résultats obtenus avec ces deux approches sont plutôt encourageants.
Pour le système de recommandation, la mise en place d’un test d’évaluation de la pertinence des recommandations de recettes similaires pour 20 recettes nous a permis d’évaluer sur 100 points différentes méthodes de NLP appliquées aux intitulés des recettes et aux listes d’ingrédients (pour les plus curieux, la similarité entre les vecteurs est évaluée par la mesure cosinus, pour s’affranchir des problèmes de dimension variable des textes).
Les algorithmes permettant d’obtenir les meilleurs scores tout en affichant une meilleure robustesse – compte tenu des biais de notre système d’évaluation – sont ceux combinant les mesures de similarité sur les ingrédients (avec TF-IDF) et celles sur les intitulés de repas (avec des Bag of Words).
Performances systèmes de recommandation (NLP)
Pour la deuxième approche, appliqué au cas plus simple de la classification sur le type de vin (rouge, blanc, rosé ou effervescent), les algorithmes supervisés ayant montré les meilleures performances sont le Support Vector Classifier et la Régression Logistique, qui parviennent à 75% de bonnes classifications sur notre base de test.
La mise en bouteille, c’est pour quand ?
Si les preuves de concept sont encourageantes, nous sommes encore loin de voir cette fonctionnalité apparaître sur Marmiton (désolé, pour ce réveillon il faudra se creuser la tête pour ne pas fâcher Mamie). Au-delà des problématiques dues au développement de la fonctionnalité sur l’application et à l’hébergement des modèles, différentes étapes peuvent et doivent être mises en place avant de pouvoir lancer un produit.
D’un point de vue algorithmique, le système de recommandation a été évalué partiellement sur la pertinence des recettes similaires proposées mais pas sur l’accord de bouteille obtenu : l’analyse de retours d’utilisateurs permettrait de mieux apprécier la qualité de nos recommandations – et par la même occasion, l’appétence des clients pour ce type de service ! -, tout comme l’évaluation de la qualité des recommandations par un sommelier professionnel. D’autres techniques de NLP peuvent être mises en place pour améliorer la précision ou exploiter d’autres attributs de notre base de données (analyse de sentiments et d’intentions dans la description des vins notamment). Enfin, la base de données pourrait être étendue pour de meilleures performances algorithmiques : la data augmentation, en modifiant certains ingrédients mineurs des recettes, est une piste envisageable.
D’un point de vue business et juridique, selon l’appétence des utilisateurs le modèle de génération de revenus doit être pensé et des accords passés afin de se procurer les droits sur l’usage des données (le scrapping n’est pas légal à des fins commerciales). La suggestion de bouteilles de vin doit également être légalement encadrée pour éviter des accusations de “parasitisme” (une atteinte à l’image d’un produit en voulant utiliser son image de marque, par exemple ici si une bouteille de prestige est associée à un repas “banal”).
D’un point de vue éthique, enfin, la recommandation de bouteilles d’alcool peut inciter à la consommation d’alcool : il faut se conformer aux lois en vigueur sur ces questions de santé publique pour proposer les recommandations dans un format en adéquation avec celles-ci.
Aujourd’hui, le digital painting (peinture numérique) est utilisé dans de nombreux studios d’animation ou par des créateurs qui souhaitent partager leurs œuvres rapidement et efficacement. La flexibilité et la portabilité qu’offre ce moyen de faire du dessin est un avantage maintenant incontournable et permet un gain de temps et d’argent aux créateurs qui souhaitent numériser leur production à moindre prix [1].
Krita, lancé en 1998 par la communauté KDE, est un projet open source proposant une solution gratuite de logiciel conçue pour le digital painting et la retouche d’image matricielle. Il s’inscrit dans le projet KDE visant à créer un bureau UNIX avec de nombreux logiciels utiles au quotidien [2]. Après un développement qui a tardé à commencer, une première version de Krita est lancée en 2003, et à partir de 2009, Krita se spécialise dans le dessin. En 2013, la fondation Krita est créée pour la gestion du projet [3].
Pour cette nouvelle année, Krita passe en version 5.0, de quoi offrir du nouveau contenu à ses utilisateurs et de satisfaire sa communauté grandissante.
Dans ce rapport, nous étudierons d’abord le marché dans lequel évolue le logiciel. Ensuite nous analyserons sa stratégie économique et enfin, nous verrons les ressources législatives dont dispose Krita pour assurer sa stabilité et sa durabilité.
Marché du logiciel
1.1) Besoins
Krita étant un logiciel de dessin numérique et de retouche photo, il se place dans un marché très spécifique et en constante évolution [4].
Ainsi, les logiciels de ce marché doivent proposer une grande variété de fonctionnalités sur la gestion de la couleur et de l’apparence, répondant à des attentes précises et techniques.
Mais proposer un très large choix de fonctionnalités pour des logiciels de retouche photo est inefficace si celles-ci ne sont pas disponibles facilement et intuitivement. Ainsi le premier critère de choix est l’interface [5] pour la majorité des utilisateurs, c’est-à-dire les particuliers peu à cheval sur la technique avancée des fonctionnalités [4].
Ainsi, il est primordial de proposer une bonne interface pour ce marché et cela consiste de permettre à l’utilisateur de faire usage des fonctionnalités de manière simple et intuitive afin que les nouveaux arrivants ne perdent pas trop de temps dans l’apprentissage des services proposés. Ensuite, il est très apprécié que l’interface soit personnalisable afin que chaque utilisateur se sente libre dans la manière d’utiliser le logiciel et cela permet aussi à des personnes qui utilisaient un autre logiciel, de se rapprocher d’une configuration qu’ils connaissent déjà qui est donc plus facile à prendre en main [6].
On peut donc voir que l’interface est une véritable barrière à l’entrée des nouveaux utilisateurs. Par ailleurs ces nouveaux utilisateurs sont très demandant d’une documentation et de tutoriels afin de commencer leur utilisation et c’est un point à ne pas négliger [5]. La diversité et la facilité d’accès à des tutoriels sur des plateformes telles que YouTube pour Krita [7] est notamment très utile si l’on souhaite toucher une clientèle plus jeune.
En effet, pour un logiciel libre et gratuit, les étudiants sont une cible principale car ceux-ci possèdent moins de moyens pour se procurer un logiciel payant dont le prix peut s’avérer élever, d’autant plus qu’ils sont, pour la plupart, sur une période d’apprentissage. Ainsi, il est plus naturel pour ceux-ci de se tourner vers une solution moins coûteuse.
Afin de se démarquer sur le marché des logiciels de modification de photo, il ne suffit pas d’avoir une bonne facilité d’accès et d’utilisation, il faut aussi une diversité de services importante afin de répondre aux attentes d’un maximum d’utilisateurs et des fonctionnalités performantes et techniques pour satisfaire une clientèle plus professionnelle [4].
Parmi les nombreuses fonctionnalités que peuvent proposer ces logiciels, on peut citer des fonctionnalités principales qui constituent l’attente qu’un client peut avoir pour un logiciel libre et dont la performance permet de faire un classement entre les différents logiciels [8].
Tout d’abord, il est nécessaire pour un logiciel permettant le montage photo de posséder des outils de sélection efficaces. En effet, ces outils permettent de ne modifier qu’une partie de l’image choisie par l’utilisateur, autrement dit, cette action est à la base de toute retouche locale. Ainsi, si ces outils sont automatisés et performants, l’utilisateur gagnera du temps sur ses montages et ceux-ci seront plus précis et fins [9].
Ensuite, une fois qu’une partie d’une image a été sélectionnée, afin de pouvoir faire des modifications dessus ou ajouter des éléments, il est nécessaire d’avoir une gestion de calques. De fait, cet outil permet de superposer des éléments et de les traiter indépendamment du reste de l’image. Ainsi, une gestion avancée de cet outil permettra à l’utilisateur de garder facilement son montage organisé [10].
Pour continuer, il parait logique pour un logiciel de montage photo de proposer des outils avancés de gestion et d’affichage de la couleur. En effet, la plupart des modifications font appel à un traitement et à une gestion de la couleur [11]. Il est alors avantageux pour un logiciel de montage photo de posséder des technologies avancées dans la gestion de la couleur.
Ensuite, un logiciel plutôt orienté vers le dessin tel que Krita aura besoin de fonctionnalités plus spécifiques en plus des outils de retouche photo.
En effet, le dessin informatique requiert l’utilisation d’une tablette graphique afin d’être plus précis en plus d’offrir une expérience plus similaire au dessin traditionnel [12]. Il est donc important pour un logiciel de dessin d’avoir une gestion avancée de celle-ci afin de permettre à l’utilisateur d’être plus précis et donc plus performant dans ces dessins.
Le matériel peut accélérer ou non l’efficacité du logiciel puisque certaines tablettes graphiques sont plus performantes que d’autres, que ce soit au niveau de la sensibilité (plus ou moins de niveau de sensibilité) ou de la technologie (tablette avec écran ou non) [57].
Enfin, de nombreux utilisateurs font de l’animation grâce aux logiciels de dessin, et par conséquent, la gestion de celle-ci devient un critère important lors du choix du logiciel [12].
Ainsi, Krita, comme ses concurrents, doivent répondre à un grand nombre d’attentes des utilisateurs qui ont des besoins variés, spécifiés et techniques tout en leur proposant une utilisation facilitée de fonctionnalités avancées.
1.2 Concurrents
Pour répondre aux besoins des utilisateurs, de nombreux logiciels de retouche photo et de dessin sont disponibles, mais parmi les plus influents, on peut en ressortir quatre :
Krita est un logiciel de retouche d’image matricielle. Il se définit comme un logiciel professionnel et gratuit afin de donner des outils artistiques performants à tous, professionnels ou amateurs [13].
Sa fonction première est la retouche d’image matricielle mais il s’oriente vers le dessin numérique et l’animation 2D.
Ce logiciel étant fait pour les artistes, il intègre très bien la tablette graphique avec une réponse au stylet très précise selon la pression appliquée [14].
Photoshop de son côté est une référence dans le monde de la retouche photo au point de donner un verbe « photoshoper » qui désigne dans un langage courant l’action d’éditer une image [15]. Ce logiciel, présent depuis 1990, a pour ambition de répondre à une clientèle professionnelle en proposant tous les outils nécessaires et avec succès comme le montre la figure 2, Photoshop vient plus naturellement quand on pense logiciel d’édition d’image. De plus, celui-ci est facilement piratable et est un des logiciels les plus piratés. On peut d’ailleurs penser que l’accès facile à une copie illégale du logiciel est un choix d’Adobe afin de permettre aux potentiels utilisateurs de se former avant d’acquérir une licence. Cela place donc Photoshop comme l’un des concurrents principaux de Krita.
Ensuite, Gimp, dans une démarche similaire à Krita, propose un service de retouche photo gratuitement pour pouvoir donner à tous des outils d’édition d’image performants en se rapprochant de la qualité de Photoshop et en proposant plus de personnalisation. La démarche étant similaire à celle de Krita, cela fait de Gimp un concurrent principal de Krita.
Enfin Paint Tool Sai se rapproche de Krita en tant que logiciel de dessin numérique avec une application légère et personnalisable, ce logiciel propriétaire propose de nombreuses fonctionnalités de dessin avancées tout en permettant une grande personnalisation des outils comme le propose Krita [16].
On peut donc comparer ces quatre concurrents à l’aide du tableau suivant :
Fonctionnalités spécifiques permettant aux logiciels de se démarquer
– Générateur de brosses – Editeur de calques- Intégration d’OpenGL (fonctions de calcul d’image 2D et 3D [17]) pour un rendu très rapide- Support HDR (technologie d’ajustement des intensités lumineuse [18])- Outils de transformation- Assistants dessin – Outils de miroir- Couverture CMYK (format de couleur pour les imprimantes [19])- Personnalisation de l’interface
– Outils de lissage – Lightroom (outil de gestion de flux de production photographique [20])- Gestion des polices- Outils de courbure- Outils d’édition d’image 360- Couverture CYMK [19]
– Personnalisation de brosses- Précision inférieure au pixel pour les outils de peinture- Compatibilité de scripts (python, scheme, perl)- Format MNG (format d’animation [21])- Personnalisation de l’interface
– Gestion avancée de la couleur- Gestion avancée des calques- Technologie anti-aliasing- Support de la technologie Intel pour un rendu plus rapide- Légèreté de l’application
Tableau 1 : Comparaison des fonctionnalités entre Krita, Photoshop, Gimp et Paint Tool Sai [14] [22] [23] [24] [25]
Contrairement à Photoshop, Krita propose un large choix de personnalisation que ce soit au niveau des outils comme les brosses ou les filtres mais aussi dans la personnalisation de l’interface avec notamment une API python pour plus de personnalisation [26].
Concernant les outils, Krita décrit sur son site les nombreuses brosses personnalisables créés par des membres de la communauté. En effet, le logiciel propose 18 générateurs de brosse [27], et cela permet aux artistes de créer des ensembles de brosses répondant à leurs besoins propres.
Les fonctionnalités de stabilisateurs de brosse et d’assistants aux dessins sont décrites comme très appréciées par leurs utilisateurs car comme le précise Krita, elles permettent de perfectionner les tracés et de créer plus rapidement des effets tels que l’intégration d’une perspective curviligne [28].
Ainsi Krita se place dans une démarche plus proche de l’utilisateur en s’adaptant à leurs volontés et leurs habitudes. Krita est donc plus « user-friendly » contrairement à Photoshop qui est beaucoup plus rigide dans la présentation de son interface.
Par conséquent le coût de Photoshop est beaucoup plus élevé que Krita ou Gimp que ce soit financièrement mais aussi en termes de coût d’entrée car il faut s’adapter aux fonctionnalités et à l’interface.
De son côté, Gimp est assez équivalent à Krita du point de vue de la personnalisation de l’interface et la possibilité d’ajout de modules et plugins produits par des contributeurs. Cependant, Gimp est plus orienté vers la retouche photo.
Par ailleurs, le succès de Krita tire son origine dans la grande diversité d’utilisateurs pour lesquels Krita s’adresse.
Tout d’abord, Krita est disponible sur de plus en plus de systèmes d’exploitation. En 2020, c’est sur Chrome OS et sur Android que Krita fait son apparition [1]. Cela a pour effet d’élargir le champ des utilisateurs et donc le nombre de téléchargement mais aussi de complexifier son développement.
Le passage du logiciel à Android et ChromeOS permet d’étendre le logiciel pour les utilisateurs de tablettes puisque certaines tablettes sont optimisées pour le dessin numérique. En effet, utiliser une tablette peut présenter plusieurs avantages par rapport à une tablette graphique puisqu’on n’a pas à la brancher sur son ordinateur, la tablette sous Android s’occupe de faire tourner le logiciel. Ainsi, Krita vient répondre à un tout nouveau besoin des utilisateurs permettant de capter une clientèle ciblée et par conséquent, d’augmenter son nombre d’utilisateurs.
Ensuite, pour faciliter l’arrivée de nouveaux utilisateurs, Krita dispose d’un grand nombre de tutoriels disponibles sur son site internet [29] afin de rendre le logiciel plus accessible. Krita propose aux utilisateurs qui souhaitent apprendre le dessin des tutoriels sur les principes de bases du dessin [30], afin d’attirer de nouveaux utilisateurs néophytes.
Afin de réduire le coût d’apprentissage pour les utilisateurs venant de logiciels concurrents, Krita permet de configurer les raccourcis du logiciel avec les mêmes raccourcis que Photoshop, Gimp et PaintToolSai [figure 9 en annexes].
Comme pour beaucoup de logiciel, la productivité du logiciel dépend du degré de maîtrise de celui-ci. En effet plus l’utilisateur connaît le produit, plus il sera efficace sur celui-ci et pourra explorer les nombreuses fonctionnalités du logiciel.
Ainsi, un expert de Photoshop, Gimp ou Paint tool SAI pourra facilement passer à Krita avec un temps très court d’adaptation. Cependant, l’inverse est aussi vrai, un expert de Krita pourra facilement passer à un logiciel concurrent avec un peu de pratique.
On peut donc placer les trois logiciels sur le graphique suivant :
Figure 1 : Caractérisation des logiciels Krita, Photoshop et Gimp (plus on est haut, plus on est personnalisable, plus on est proche de variété, plus on propose de fonctionnalités efficaces, plus on est proche du coût, plus celui-ci est faible).
1.3) Krita dans le marché
a) Développement de la communauté
Krita a développé un aspect communautaire fort avec une activité importante sur les forums tels que Reddit avec plus de 52 000 abonnés [31] et des post tous les jours. Krita s’étant fait connaitre plus récemment que ses concurrents, sa communauté reste moins importante que celles de Gimp (174 000 abonnés sur Reddit [32]) ou Photoshop (455 000 abonnés sur Reddit [33]). Mais Krita a aussi lancé en 2019 son forum dédié : Krita-artistes [34] qui compte 13 000 utilisateurs dont plus de 1 000 actifs sur le mois dernier.
De plus, une chaîne YouTube [7] de plus en plus active avec 43 000 abonnés et une vidéo mensuelle permet à une clientèle plus jeune et étudiante de prendre en main le logiciel au travers de tuto et de progresser.
Ainsi Krita a encore besoin de se développer pour atteindre l’influence de ses concurrents, en témoigne le nombre de recherches sur google de Krita et de ses deux principaux concurrents. Mais sa présence de plus en plus active sur de nombreux réseaux sociaux présagent un gain de popularité et donc de stabilité pour le logiciel.
Figure 2: Analyse des recherches des termes « krita », « photoshop » et « gimp » [35]
Le bouche à oreille est primordial chez Krita, puisque c’est celui-ci qui, couplé à la réputation du projet, attire de nouveaux utilisateurs. En effet, le nombre d’utilisateurs est en constante augmentation comme le montre la figure ci-dessous. Entre 2019 et 2020, le nombre de nouveaux téléchargements uniques a doublé, passant de 2,35 millions à 4,85 millions en 2020 [61]. En 2021, c’est près de 80 000 nouveaux téléchargements par semaine [62] qui sont effectués uniquement sur le site de Krita et ce chiffre augmente encore.
Figure 3 : Évolution du nombre de téléchargements uniques entre 2018 et 2020(figure réalisée à l’aide de [61-62])
D’abord, l’utilisation de Krita par des artistes professionnels contribue à la popularité de Krita. On peut citer David Revoy [63] qui se définit comme un utilisateur confirmé de Krita et ayant réalisé une BD entièrement avec le logiciel. La mise en place d’un forum krita-artist [34] où chacun publie ses réalisations avec le logiciel permet également d’accroitre la popularité du logiciel en montrant ce que l’on peut produire avec le logiciel par des projets finis.
De plus, en donnant l’autorisation de montrer l’interface par le biais de la licence [64], de nombreuses vidéos tutoriels de Krita ou des streams de personnes utilisant le logiciel ou encore des times laps (vidéo accélérée) sont mises en ligne sur des plateformes vidéo comme Youtube ou Twitch. Cela contribue grandement au succès de Krita puisque ces vidéos sont susceptibles d’attirer de nouveaux utilisateurs au logiciel. Cela donne un attrait pour les débutants du domaine puisque le logiciel semble accessible, par la présence de nombreux tutoriels.
L’intégration du logiciel à KDE [41] joue un rôle clé puisqu’elle permet d’étendre le réseau dans la communauté KDE d’une part mais aussi d’étendre son réseau dans la communauté open-source en utilisant la réputation et l’image de marque de KDE.
Krita a également reçu plusieurs donations d’entreprises comme FossHub ou encore Gamechunk [56]. Le projet a également reçu un soutien financier d’Epic Games à travers le programme Mega Grants, ce qui témoigne du professionnalisme du logiciel [65].
Ainsi, on a d’autant plus d’intérêt à utiliser Krita que le nombre d’utilisateur augmente puisque d’une part, on trouvera de nombreuses ressources pour nous aider à prendre en main le logiciel. Plus la communauté est importante et active, plus on trouvera facilement un interlocuteur pour parler du logiciel. De plus, plus le logiciel est populaire, plus les donations et les contributions sont nombreuses et donc plus longtemps le logiciel sera maintenu.
b) Économie d’échelle
A priori, le logiciel ne proposant pas de services premium ou autres abonnements et ne faisant pas payer le logiciel, aucune économie ou déséconomie d’échelle ne semble pouvoir être mentionné. En effet, une fois l’exécutable téléchargé, le logiciel tourne en local sur l’ordinateur de l’utilisateur, ne dispose pas de sauvegarde en cloud et n’utilise les infrastructures de Krita uniquement pour vérifier et au besoin installer les mises à jour.
Cependant, une économie d’échelle peut être trouvé dans le sens où plus le nombre d’utilisateur sera élevé, plus les dons et les contributions seront conséquents puisque plus d’utilisateurs seront susceptibles de donner ou contribuer au logiciel. Cela aura ainsi pour conséquence direct une augmentation de fonctionnalités du logiciel ainsi qu’un maintien voire un gain de qualité avec l’apport de fix et de mises à jour. Ce gain de qualité va directement se répercuter sur le nombre d’utilisateur qui devrait grimper et qui à son tour va donner plus de moyen à Krita pour se développer. Ce cercle vertueux peut être vu comme une économie d’échelle même si celle-ci est indirecte et est en réalité plus complexe puisque que le nombre d’utilisateur peut augmenter tandis que le nombre de contributions ou de dons peut rester stable voire diminuer.
L’utilisation du logiciel par des entreprises réputées du monde du jeu vidéo, de l’animation ou de la VFX, contribuent également à la popularité du logiciel. Les donations des entreprises permettent un maintien du logiciel et permette à ces entreprises de se déresponsabiliser du fonctionnement du logiciel et fonctionne comme une sous-traitance moins coûteuse. En effet, contribuer au projet open-source permet de développer le logiciel, voir l’apparition de fonctionnalités répondant à nos besoins tout en laissant la gestion du projet à la communauté open-source. Ainsi, une hausse du nombre d’utilisateurs tend vers une augmentation des revenus du projet et donc à une captation de valeur plus grande.
À l’inverse, l’augmentation du nombre d’utilisateurs n’implique pas une évolution des coûts. En effet, le coût de maintien du logiciel reste le même quel que soit le nombre d’utilisateur. Cependant, une hausse des utilisateurs augmente la chance de trouver un bug même si cet aspect reste minime au vu du nombre d’utilisateur et de la taille du projet.
c) Krita et interopérabilité des logiciels
Comme explicité précédemment, Krita est disponible sur Windows, MacOS, Linux et bientôt Android et ChromeOS. Cette disponibilité sur presque tous les OS permet de s’adapter et de reprendre ou envoyer des projets sur des appareils avec des systèmes d’exploitation différents. Le travail en multi-plateforme est possible, et ce en grande partie grâce à l’utilisation de Qt [42].
De plus, Krita permet d’exporter le projet en plusieurs extensions listés dans la figure en annexe [figure 7]. On remarque qu’on peut exporter un projet de Krita en un projet Photoshop avec l’extension .psd (extension native de photoshop).
Cependant, on ne peut pas exporter un projet de Krita directement à Gimp avec l’extension *.xcf (extension native de Gimp). On peut cependant passer par l’extension *.ora qui permet de faire le lien entre la grande partie des logiciels de retouche d’image matricielle open-source [60].
Krita peut ouvrir de nombreux formats de fichiers comme listé en annexes [figure 8]. On notera la présence de fichiers *.ora et *.psd qui permettent d’ouvrir des projets Photoshop et Gimp dans Krita.
Le fait de pouvoir facilement passer d’un logiciel à l’autre permet de faciliter la collaboration des utilisateurs utilisant différents logiciels. Cependant, cela peut inciter les utilisateurs à utiliser plusieurs logiciels pour travailler. Certains utilisateurs peuvent utiliser Krita pour certaines fonctionnalités, et passer sur les logiciels concurrents pour d’autres fonctionnalités. Cette interdépendance entre les logiciels est également pratique pour pouvoir travailler en collaboration et pour avoir accès au besoin à des fonctionnalités propres aux logiciels et cela constitue un avantage non négligeable pour les utilisateurs en besoin de performances spécifiques. On peut imaginer un utilisateur travailler sur une retouche photo sur Photoshop puis passer à Krita pour finaliser son projet car il a besoin d’une personnalisation importante de brosses.
Cette interdépendance était néanmoins nécessaire pour le projet puisque pour pouvoir se faire une place dans le marché du logiciel de dessin numérique, le logiciel doit s’adapter aux autres logiciels dominants du secteur tel que Photoshop ou Gimp pour pouvoir s’insérer dans le marché et s’y développer.
Modèle d’affaire de Krita
Ressources clés et activités du projet
Krita doit répondre à une forte demande technologique de fonctionnalités variées et personnalisables comme nous l’avons vu dans la partie précédente.
Tout d’abord, afin de proposer de nouvelles fonctionnalités et les mettre à jour, Krita s’est orienté vers une programmation open-source [36]. En effet, cela permet aux utilisateurs qui souhaitent voir de nouvelles fonctionnalités, de les ajouter à l’application en contribuant au projet ou en demandant à d’autre membres de la communauté de les implémenter.
Ce modèle est bénéfique pour la fondation car les utilisateurs peuvent satisfaire par eux-mêmes leur demande. Mais cela nécessite une bonne organisation afin de conserver une intégrité et une stabilité globale.
Pour cela, le code source du projet est hébergé chez GitLab [37]. Celui-ci a pour but de concentrer les ajouts et modifications faites par les contributeurs.
Un outil de tracker de bugs, Bugzilla, a été mis en place [38], facilitant non seulement l’envoi de rapports de bugs pour les utilisateurs, mais également les contributions à apporter. Cela permet d’automatiser le suivi du logiciel et de pouvoir facilement repérer les tâches à effectuer.
L’organisation du travail était gérée sur Phabricator, qui est un outil de gestion de projet, de suivi de problèmes et de revue de code. Cependant, celui-ci n’est plus actif (la dernière tâche date de 2017) et l’organisation du travail est passée sur Bugzilla qui permet de faire le même travail que Phabricator.
Les contributions sont une ressource primordiale pour le projet, puisque sans celles-ci, le logiciel ne serait pas maintenu et resterait au point mort.
Une fois que des nouvelles fonctionnalités sont implémentées et que certains bugs sont corrigés, l’application Krita est mise à jour pour les utilisateurs afin que ceux-ci puissent en bénéficier dans un environnement testé et fonctionnel. Ces mises à jour, tout comme l’avancée du projet et les volontés pour le futur du projet sont annoncées au travers de notes de mises à jour [39].
Cette communication est une activité très importante pour Krita, en effet, celle-ci permet aux utilisateurs de s’adapter plus facilement aux nouvelles fonctionnalités et c’est aussi un reflet sur la dynamique du projet. Par conséquent un utilisateur se sentira plus écouté et soutenu s’il voit des mises à jour régulières s’effectuer et sera donc plus apte à s’impliquer dans le projet.
Pour proposer ce service, Krita se repose sur son site web [39], un outil qui concentre toutes les informations principales sur le logiciel et son développement.
Krita ne se définit pas seulement par son code source, un logiciel ou sa communauté, il s’agit aussi d’une marque déposée. La marque Krita, son logo ainsi que la mascotte sont propriétés de la fondation Krita [68].
L’utilisation d’une marque permet plusieurs avantages, notamment de se protéger contre des utilisations abusives de l’image de marque du logiciel. En effet, la fondation possède le monopole d’exploitation de la marque pour distribuer son logiciel mais aussi pour la communication. Bien que la licence du logiciel permette une redistribution par un tiers, si le logiciel diffère du projet initial, la marque et tout ce qui lui est associé (logo, nom etc.) ne peut pas être utilisé pour la redistribution. La marque est propriété de la fondation et est juridiquement protégée. La marque permet également d’avoir un contrôle sur l’usage et la collaboration du code.
L’utilisation d’une marque permet non seulement de se protéger mais aussi de se créer une identité forte et de se distinguer face aux concurrents et apporte donc une valeur ajoutée au projet. La fondation Krita, propriétaire de la marque, se définit comme partisan du développement de logiciels graphiques gratuits et open source et fonde son image de marque sur ce principe. Ceci attire de nombreux utilisateurs qui voit ce principe d’open source comme un label de qualité et vont alors accorder leur confiance au projet. Cette réputation est une ressource très importante puisqu’elle agit comme un gage de qualité du point de vue des utilisateurs, permettant ainsi d’accroitre leur nombre et par conséquent la réputation du projet. Les dons ainsi que le nombre de contributions augmentent au fur et à mesure que le logiciel est utilisé et que la communauté s’agrandit, ce qui renforce la qualité du logiciel. On a ici alors un cercle vertueux se basant sur la confiance mutuelle des utilisateurs et des responsables du projet.
De plus, le soutien du projet KDE renforce d’autant plus l’image de marque du logiciel car celle-ci récupère la réputation due au développement de logiciels gratuits et open sources du projet initial [2].
Le logiciel Krita est distribué sous une licence GNU GPL v3 (General Public Licence version 3) [3]. Cette licence garantit la liberté d’utilisation du logiciel sans condition, tout en assurant sa qualité de code open-source en protégeant les auteurs et le projet [34]. Elle assure une protection légale pour le projet et constitue une ressource juridique très importante pour le projet. La licence est disponible sur le site web dans un onglet dédié et est facilement accessible afin que toutes les parties puissent prendre connaissance. Elle est également disponible dans un fichier du code source, conformément aux consignes de la GNU GPL afin de valider la licence au niveau juridique [70].
Krita possède donc des domaines clés, dans lesquels la fondation et la communauté s’investissent, qui permettent de répondre aux besoins grandissant des utilisateurs.
Partenaires clés
Afin de soutenir ses activités, Krita peut s’appuyer sur l’aide de partenaires précieux.
Dans un premier temps, la fondation KDE est le premier partenaire de Krita. En effet, fondée en 1996 par Matthias Ettrich, le principal projet de cette communauté est le développement d’un environnement de bureau pour UNIX nommé Plasma, fourni avec un ensemble complet de différents logiciels dont Krita fait partie. [41]
La communauté KDE est donc à l’origine du projet et reste à ce jour à sa tête.[3] Tous les contributeurs du logiciel sont des membres de la communauté KDE. Les contributeurs du projet ont donc une expertise assez importante concernant le développement de logiciels open-source [41]. Cela permet donc à Krita de renvoyer une image plus rassurante et professionnelle mais ce partenariat profite aussi à KDE car il permet d’étendre la visibilité de KDE et de compléter son projet plasma.
Ensuite, concernant le développement du logiciel Krita, celui-ci utilise le Framework Qt dont il est très dépendant. Cette forte dépendance à Qt peut être problématique car si Qt n’était plus maintenu, alors Krita se retrouverait en grande difficulté et devrait revoir sa technologie. Cependant, Qt est aujourd’hui une très grande entreprise reconnue et présente mondialement dans des secteurs divers, donc le risque que Qt ne soit plus maintenu semble aujourd’hui assez faible [42].
L’un des principaux avantages de Qt est de proposer les fonctionnalités d’OpenGL au travers de PaintGL qui sont ensuite implémentées par les commandes KisOpenGL [43]. Cela permet à Krita de proposer une plus grande rapidité d’affichage du rendu 2D ou 3D dans le logiciel [44].
De son côté, Qt gagne en visibilité et donc en potentiel contributeurs sur le projet. De plus, Krita a tout intérêt à le promouvoir afin de maintenir son développement.
Pour continuer, Krita possède aussi des partenariats qui aident la Fondation d’un point de vue financier. En effet, en 2019, Epic Games à fait un don de $25 000 à la fondation Krita [45] afin de permettre à Krita un développement plus durable. Cela est en effet bénéfique pour la fondation car cela lui a permis de booster le projet et lui donner de la visibilité. Mais cet investissement n’est pas sans intérêt. En effet, Krita se trouve actuellement disponible sur l’Epic Store [46] au prix de 7.99€ or Epic Games prend une commission qui en 2018 était limitée à 12% [47]. Par conséquent, ce partenariat permet à Krita de continuer à se développer et gagner en popularité ce qui profite aussi à Epic car les ventes de Krita sur leur plateforme leur permettent de rentabiliser leur investissement.
Cet investissement fait partie d’un programme lancé par Epic Games, l’Epic MegaGrants. Ce programme consiste à financer des développeurs de Jeux vidéo, des entreprises ou des projets open-sources développant le milieu du graphisme. [65]
En effet, Epic a développé UnrealEngines, un projet proposant l’environnement de création 3D décrit comme le plus complet existant. [80] Ainsi, Epic soutien des logiciels libre comme Blender ou Krita pour rendre leurs développement plus stables et durables afin de pouvoir continuer à utiliser leurs technologies et leur service pour développer et exploiter au maximum de ses fonctionnalités UnrealEngines. De plus, contribuer au logiciel sous forme de don permet de booster la dynamique du projet sur un court instant, tout en étant moins chère que de payer un développeur à temps plein. Le prix offert par Epic permet de stimuler la communauté open-source et encourage le développement de logiciels tout en étant en retrait sur leur gestion.
Par conséquent, Krita possède de nombreuses aides pour réaliser ses activités principales grâce aux partenariats qui profitent à chaque membre.
Fondation
En 2012, la fondation Krita est créée par la communauté du projet. Une fondation se définit comme une personne morale de droit privé à but non lucratif pour accomplir une œuvre d’intérêt général [66]. Aujourd’hui, Halla Rempt dirige la fondation et est chargée de la gestion du projet [67]. La fondation est aujourd’hui responsable de l’organisation du projet et prends les principales décisions. La fondation se donne les objectifs suivants :
Soutenir le développement de logiciels graphiques libres, en particulier Krita.
Fournir de nombreux services aux développeurs et aux utilisateurs de Krita, comme la documentation du logiciel par exemple ou encore la mise en place d’un forum.
Fournir aux créateurs et artistes tous les besoins logiciels pour faire de la peinture numérique [40].
La fondation permet de soutenir de façon pérenne le développement du logiciel et lui donne une certaine indépendance vis-à-vis du projet KDE dans lequel ce logiciel s’insère. En effet, la création de la fondation permet au projet Krita de survivre malgré ce qu’il peut arriver au projet KDE. Si un jour le projet KDE s’effondre, alors Krita sera toujours potentiellement maintenu grâce au soutien de la fondation et à tous les avantages que cela apporte.
La création de la fondation permet également de formaliser l’organisation du projet et regroupe toutes les tâches administratives sous une même entité. Par exemple, les dons sont récoltés et redistribués par la fondation Krita [40], ce qui permet de redistribuer les dons de manière optimale en fonction des besoins du logiciel. Ceux-ci sont également défiscalisés grâce au statut de la fondation. La fondation embauche ainsi 5 développeurs à temps plein dans le but d’assurer la maintenance nécessaire aux fonctionnalités de Krita. Cela a pour avantages de sécuriser le projet et de le rendre plus professionnel et donc plus crédible face à une clientèle plus technique [53].
Cela permet également de centraliser les services fournis tel que la documentation, le site web, le forum… La fondation fournit également le matériel nécessaire pour pouvoir tester pleinement les fonctionnalités du logiciel (les tablettes graphiques par exemple). Elle finance aussi les frais associés aux différents sprints organisés pour le développement du logiciel [40]. La fondation met alors en place des moyens pour stimuler la communauté, la rendre active et apporte un cadre de collaboration adapté, ce qui permet de faire vivre le logiciel et de le développer.
Ainsi, la gouvernance du projet se fait par la communauté, c’est-à-dire par les personnes développant le logiciel ainsi que les utilisateurs, avec une équipe cœur pour prendre les décisions les plus importantes du projet et avec une écoute et un dialogue avec la communauté. Ils sont appuyés par la communauté d’un autre projet d’envergure qui est KDE. Cette forme de gouvernance par la communauté facilite le travail en collaboration et l’interaction avec les utilisateurs, notamment grâce aux forums, chats de discussions, mailing list mis en place [67].
La communauté de Krita étant assez ancienne, elle a formalisé son organisation au moyen de la création d’une fondation qui permet de centraliser les tâches administratives tel que les déclarations fiscales par exemple, de s’occuper de la communication, de gérer les dons et de s’assurer une certaine indépendance au projet KDE. En effet, bien qu’à l’origine le logiciel faisait partie de KDE, aujourd’hui la fondation Krita en gère légalement le développement. Cela permet de s’assurer un développement en accord avec toutes les parties, augmentant ainsi les opportunités du projet et en réduisant les risques.
Flux de coûts et revenus financiers
a) Coûts de la fondation
Pour répondre aux besoins des utilisateurs, la fondation Krita se voit confrontée à certains coûts.
Tout d’abord, afin de permettre les contributions de la communauté, il faut pouvoir mettre à disposition le code source du logiciel et gérer les dépôts. Cela, Krita se fait grâce à un hébergement chez GitLab. En effet, depuis que KDE a migré vers GitLab [48], Krita doit payer l’hébergement de son code chez celui-ci. Or bien que pour un particulier, cela soit gratuit, les tarifs varient entre $19 et $99 par mois et par utilisateurs [49]. Nous n’avons pas trouvé la formule utilisée par Krita sachant en plus que KDE possède un partenariat avec GitLab [48] donc il se peut que les prix d’hébergement soient réduits pour Krita.
Afin de permettre aux utilisateurs de télécharger Krita et de chercher facilement des informations, Krita doit héberger un site Web. Ceci a un prix mais étant donné que celui-ci est hébergé par KDE [50], nous n’avons pas pu trouver le coût de son hébergement.
Enfin, comme nous l’avons vu précédemment, la fondation Krita parraine 5 développeurs. Ainsi, cela revient à un flux plus de 15 000€ par mois consacrés aux développeurs cœur car la fondation leur fournit également l’environnement de travail nécessaire et paye les éventuels déplacements [40].
De plus, elle a parrainé au cours de l’année quelques développeurs en plus pour travailler sur des tâches spécifiques afin d’utiliser leurs connaissances techniques [51]. En effet, les technologies utilisées par Krita sont difficiles à prendre en main pour un développeur amateur, le coût d’entrée à la contribution est donc élevé, ce qui peut constituer une faiblesse du projet. C’est aussi pour cela que la création de documentation et d’information constitue une activité clé pour la fondation.
b) Revenus de la fondation
Mais tous ces coûts étants financés par la fondation, celle-ci possède nécessairement des revenus.
Cela commence par les utilisateurs qui peuvent, s’ils le souhaitent, faire des dons. Le système de donation se décompose en deux systèmes. Le premier consiste en des donations unitaires du montant choisis par le donateur [52]. Le second est une source plus fiable et donc quantifiée par Krita, il s’agit d’abonnements mensuels avec des montants prédéfinis [53]. Ces abonnements permettent actuellement de récolter pour la fondation un total de 4 235€ sur ce mois.
Afin de rendre ces dons mensuels plus attractifs, Krita les classe selon des paliers offrant plus ou moins de visibilité aux donateurs en fonction du montant donné [53].
Ensuite, la seconde méthode pour générer des revenus à la fondation est la vente de Krita sur les plateformes partenaires qui sont l’Epic Store [46], Windows Store [54] et Steam [55]. La plus grande partie de ces ventes revient à Krita mais en accord avec le partenariat, une commission est reversée aux plateformes allant de 12% pour l’Epic Store à 30% pour Steam [47]
Enfin, les derniers flux de revenus proviennent de marques sponsors qui donnent des fonds à Krita tel que l’a fait Epic Games, GameChuck, FossHub, ASIFA-Hollywood, Agile Coach et XOIO [56].
Ainsi, les revenus de la fondation Krita reposent essentiellement sur des dons de sa communauté. Il est donc nécessaire pour Krita de la développer et surtout de l’impliquer car ces revenus servent à financer directement les services qui permettent de développer les fonctionnalités recherchées par les utilisateurs, c’est-à-dire la communauté de Krita.
Pérennité du projet
La fondation constitue un pilier central dans le développement du projet Krita. Elle incite à la contribution en renvoyant une image stable et pérenne du logiciel notamment par une communication importante et la mise en place de moyens de communications directs avec les développeurs et la communauté par le biais de forum ou de messagerie instantanée. Un utilisateur va ainsi être motivé à contribuer, tout d’abord afin de garantir le maintien et les mises à jour du logiciel mais aussi afin de développer des outils répondant à ses besoins spécifiques. Ce procédé est d’autant plus important, que l’outil peut être utilisé par des professionnels. Ce rapprochement de la communauté permet aux nouveaux contributeurs de s’intégrer facilement et donner l’envie de s’investir. De plus, le développement de Krita permet de donner de meilleurs outils pour exploiter au mieux d’autres logiciels a priori sans relation tel que UnrealEngine par exemple. C’est pourquoi des entreprises tel que Epic investissent dans Krita, afin de booster la dynamique du projet et de profiter des fonctionnalités du logiciel. Ils ont un intérêt à ce que le logiciel perdure car c’est une alternative fonctionnelle et peu coûteuse.
Cependant, si la fondation Krita venait à disparaître ou n’était plus financée, le projet continuerait à vivre grâce au soutien de KDE qui porte encore aujourd’hui le projet. Cette double sécurité avec le soutien de KDE et la mise en place d’une fondation garantit la pérennisation du projet.
Conclusion :
Pour conclure, on peut dire que le projet Krita est un projet en plein développement et en pleine expansion avec la sortie du logiciel sur Android et le déploiement de la version 5.0, ainsi que par le nombre d’utilisateurs croissant. Krita apporte une nouvelle solution de logiciel de dessin numérique open-source et gratuite dans un marché dominé par les logiciels propriétaires tel que Photoshop. Dans le monde du logiciel libre, Krita vient concurrencer Gimp en visant une clientèle large de personne ayant un besoin d’outils de dessin numérique ou d’animation, qu’elle soit amateure ou professionnelle et en particulier, une clientèle jeune voire étudiante.
Pour animer et développer le projet, Krita dispose de nombreuses ressources clefs tel que la fondation qui permet de centraliser et organiser les tâches du projet. Les contributeurs ainsi que les sponsors apportent un soutien nécessaire au développement de l’application qu’il soit financier ou technique avec l’ajout ou la correction de bug, la traduction etc… Le soutien de KDE dans le développement de Krita est un atout considérable puisqu’il apporte des compétences dans le domaine du développement du logiciel libre, une communauté, ainsi qu’une image de marque open-source très apprécié par la communauté du logiciel libre.
Le projet dispose en plus de ces ressources clefs d’autres ressources communes à d’autres projets mais nécessaire tel que le développement d’un serveur Git ou encore l’utilisation de logiciel tel que Bugzilla pour répertorier les bugs.
Ces ressources permettent d’organiser les tâches nécessaires à la bonne réalisation du projet et à son développement. On pense notamment à l’organisation des contributions apportés au code source qui est possible grâce au git. La communication sur l’état d’avancement du projet est un point crucial puisqu’il permet d’organiser le travail et de définir les priorités. La mise en place de canaux de discussions tel qu’une mailing liste ou des forums permet cette activité. La fondation se doit également de stimuler la communauté afin que le logiciel soit utilisé d’une part et que la dynamique du projet ne s’essouffle pas.
La réalisation de toutes ces tâches permet d’une part de créer de la valeur puisqu’on produit des résultats, que ce soit du code, des corrections de bugs, le maintien du logiciel, le développement de l’image de marque… Cela permet de proposer une valeur au projet en fournissant une solution logicielle de dessin numérique mais ainsi que de nombreux autres services tels que de la documentation fournie sur l’utilisation du logiciel. La mise en place d’un forum permettant de regrouper et de rejoindre facilement la communauté autour du logiciel constitue une valeur ajoutée puisqu’elle permet de se distinguer de ses concurrents.
Cette valeur du projet permet de populariser le logiciel et va par conséquent attirer des utilisateurs métiers et des contributeurs qui à leur tour vont contribuer au projet créant ainsi de la valeur au projet. On peut citer notamment l’ajout d’add-ons par la communauté afin d’enrichir le logiciel mais aussi les dons des particuliers ou des entreprises ou encore les contributions. Krita compte sur ce cercle vertueux afin de se bâtir une réputation de logiciel professionnel, destiné à tous ceux ayant un besoin de logiciel de dessin numérique.
Afin de protéger l’organisation et le développement du projet, Krita compte sur de nombreuses ressources législatives tel que l’utilisation d’une marque déposée par la fondation permettant de donner un propriétaire au projet et empêche l’accaparation du projet par une personne ou une entreprise tierce. L’application de licences dites « libres » avec un copyleft fort permettent d’une part de s’assurer de la bonne utilisation du logiciel sans risque pour la fondation, d’autre part de protéger l’utilisateur en lui octroyant des droits, notamment sur ce qu’il peut créer avec le logiciel. Cela encourage également la contribution puisque toutes modifications se doit d’être sous la même licence ou une plus permissive, ce qui permet de développer le logiciel tout en maintenant la philosophie dans lequel le logiciel a été créée. La marque et les licences jouent le rôle de garantie légale et de protection pour la fondation qui a la charge du projet.
Tout ce procédé peut être résumé à la figure 4.
Figure 4: Schéma bilan du fonctionnement du projet Krita
Le projet ne propose que très peu de services annexes payants et a pour seul revenu financier les dons. Ceci est une faiblesse du projet puisque les dons ne sont pas une ressource fiable dans le temps et le coût d’embauche de développeurs à temps plein par la fondation est élevé. De plus, aucune entreprise ne semble se démarquer par sa contribution technique au logiciel, ce qui peut être expliqué par l’histoire du marché qui a longtemps été dominé par les logiciels propriétaires. C’est pourquoi Krita compte comme ressource la plus importante son image de marque et sa réputation afin d’attirer les utilisateurs et par extension, les contributeurs et donateurs afin de continuer à maintenir et développer le projet.
Figure 6 : Business model canvas de KritaFigure 7: Interface du logiciel (image tirée de Krita)Figure 8: Liste des formats de fichiers pouvant être exportés par Krita (image du logiciel après avoir cliqué sur exporter)Figure 9: Liste des formats de fichiers ouverts par Krita (image du logiciel après avoir cliqué sur ouvrir)Figure 10: Personnalisation des raccourcis et sets disponibles de Krita (capture d’écran du logiciel)
L’économie collaborative est un modèle socio-économique de particuliers à particuliers basé sur l’échange ou le partage de biens et services. Elle peut être définie comme « une organisation de la collaboration et des échanges, marchands ou non, entre individus, avec le souci de partager des ressources, dans un contexte institutionnel assez peu contraignant ». (N’Guyen, 2016)
Le développement de cette économie du partage, popularisée aux États-Unis depuis la seconde guerre mondiale, a été fortement facilité par l’avènement des nouvelles technologies et d’internet. En effet, diverses plateformes en ligne se sont développées pour assurer le lien entre les personnes offreurs et ceux demandeurs de biens et services. La soudaine explosion de ces plateformes de pair à pair, et principalement des licornes qui en ont résulté, a bouleversé les écosystèmes et la dynamique des marchés sur lesquelles elles se sont implantées. Le marché de l’hébergement touristique ne fait pas figure d’exception : “the sharing economy is significantly changing consumptions patterns” (Zervias & David, 2016).
La location de logements entre particuliers via des plateformes intéressent de plus en plus les voyageurs, au détriment des hébergements traditionnels proposés par des professionnels : augmentation de 15% de la fréquentation des hébergements touristiques proposés par des particuliers via des plateformes internet en 2018 en France (Bahu, 2019). Ces plateformes ont aidé à dynamiser le secteur du tourisme, aujourd’hui le troisième secteur économique mondial, qui a de nombreux bénéfices économiques pour les territoires ; mais ce n’est pas sans être accompagné d’effets néfastes de plus en plus vilipendés (Rédaction, 2019).
C’est dans ce double contexte que s’est développée Fairbnb.coop, une plateforme collaborative de location d’hébergement pair à pair de courte durée, qui a pour ambition d’être un alter ego durable et éthique d’Airbnb. Le but de cette étude est d’expliquer la création et la proposition de valeur de la plateforme Fairbnb.coop au regard des problématiques actuelles du marché de l’hébergement touristique et d’analyser le positionnement de celle-ci au sein de son environnement concurrentiel.
Nous étudions dans le document les tenants et aboutissants actuels du secteur de l’hébergement touristique, puis la segmentation des clients potentiels et la proposition de valeur de Fairbnb, enfin nous présentons son positionnement dans son écosystème.
I) Les enjeux du secteur de l’hébergement touristique, une industrie critiquée qui doit se renouveler ?
Les plateformes de locations d’hébergement entre particuliers, qui sont l’incarnation de l’économie collaborative dans le secteur de l’hébergement touristique ont été vecteurs d’améliorations pour ces utilisateurs.
D’une part du côté de l’offre, car elles permettent aux particuliers d’entrer sur le marché et de valoriser leurs biens immobiliers en une source de revenu complémentaire. Et d’autre part du côté de la demande, en offrant la possibilité aux individus de trouver un logement à des prix souvent plus économiques qui ceux proposés par les professionnels du secteur, de voyager d’une autre manière et de vivre une expérience « authentique » avec des liens entre locaux et voyageurs mis en exergue.
De plus, l’enrichissement de l’offre d’hébergements de courte durée accroît l’attractivité des territoires, et a des retombées économiques positives sur ceux-ci, ainsi que sur les propriétaires louant leur logement. C’est, entre autres, pour ces raisons que ces plateformes connaissent un tel succès ces dernières années (Zervias & David, 2016).
Cependant, force est de constater que les flux touristiques croissants ont également leur lot de désavantages. Nombreux sont les exemples des conséquences désastreuses du tourisme de masse sur l’environnement (Rédaction, 2019) : surconsommation des ressources naturelles pour pallier les besoins des touristes ; augmentation de la masse de déchets produits, destruction des écosystèmes et nuisance à la biodiversité ou encore pollution de l’air. Le tourisme est responsable de 5% de émissions mondiales de CO2 en 2010 (1,3 milliards de tonnes) selon un rapport du ministère de la transition écologique (énergétique, 2010).
Figure 1: Offre de logements de location à courte durée à Venise en 2021. (AirDNA, 2021)
À ces pressions exercées sur l’environnement s’ajoutent des répercussions négatives sur les territoires et les populations locales. Certains sites particulièrement touristiques souffrent d’un véritable phénomène de saturation car les lieux ne sont pas en mesure d’accueillir autant de monde, tant au niveau des infrastructures qu’au niveau des ressources. Le tourisme de masse nuit également à l’équilibre de la vie locale : commerces touristiques et bars remplacent les commerces de quartier, prolifération d’hôtels et hébergements touristiques au détriment de logements pour les habitants ce qui induit une flambée des prix de l’immobilier et un déséquilibre du marché locatif, nuisances sonores …
Un exemple frappant est celui de la ville de Venise, avec 33 millions de visiteurs annuels pour 55 000 habitants, la ville présente une proportion de 545 touristes par Vénitien, ce qui a notamment des retombées désastreuses sur la lagune de Venise, les fondations de la cité et les Vénitiens eux-mêmes (Rédaction, 2019). La Figure 1 montre les offres de locations Airbnb à Venise et illustre parfaitement la forte implantation de l’entreprise dans la ville.
Les plateformes de location d’hébergements pair à pair, et particulièrement leur leader Airbnb, sont aujourd’hui vivement critiquées, études à l’appui, pour avoir une part de responsabilité notable dans ces effets. Plus particulièrement, d’accélérer le phénomène de gentrification des villes, qui correspond au dépeuplement des centres ville dû au départ des classes populaires contraintes de déménager face à l’augmentation du coût de la vie (Stergiou & Farmaki, 2019) (Nieuwland & Van Melik, 2020).
Par ailleurs, l’absence de cadre juridique spécifique pour les plateformes de pair à pair (Pouly, 2016) complique le contrôle des locations pour les municipalités, malgré les initiatives pour une meilleure régulation qui se multiplient. L’article 51 de la loi n°2016-1321 pour une République numérique stipulant que les annonces doivent comporter un numéro d’enregistrement pour vérifier que les hébergements ne sont pas loués plus de 120 nuitées par an en est un exemple (République Française, 2016).
C’est dans ce contexte qu’est née en 2018 la coopérative Fairbnb. Celle-ci se veut être l’alter ego durable et éthique de Airbnb. Selon les mots du co-fondateur de Airbnb, Emanuele Dal Carlo : « The initial ground-breaking and innovative idea of home-sharing promoted by platforms like Airbnb have changed […] We combined our backgrounds of social entrepreneurship, activism and a cooperative approach to propose a model of sharing economy that is better for the users, for the communities and the touristic market itself » (Girardi, Fairbnb: The Ethical Home-Sharing Alternative That Wants To Undermine Mass Tourism, 2019) (O'Sullivan, 2019).
Fairbnb se définit comme une « plateforme de réservation sociale et de crowdfunding qui vise à limiter les effets négatifs du tourisme, en amplifiant son impact positif sur la communauté d’accueil » (Fairbnb).
La suite de cette étude a pour objectif de comprendre les raisons qui pousseraient les loueurs, dont les utilisateurs d’Airbnb, à utiliser préférentiellement cette plateforme.
II) Segmentation des clients et proposition de valeur de Fairbnb.
À l’image d’Airbnb, Fairbnb est une plateforme collaborative de mise en relation de particuliers pour la location d’hébergements de courte durée. C’est donc une plateforme jouant l’intermédiaire entre deux groupes de clients. D’une part, les hôtes pour lesquels la fonction principale est de proposer à la location un hébergement à durée limitée. D’autre part, les voyageurs, dont la fonction principale est de louer un logement de courte durée lors d’un déplacement.
Figure 2 : Schéma résumant les interactions des acteurs en lien avec Fairbnb, logo (Fairbnb)
La plateforme se positionne donc en tant qu’acteur du secteur de l’hébergement touristique, un domaine riche par la grande diversité de clients qu’il contient. Du côté de la demande, les voyageurs peuvent être divisés en plusieurs segments selon les attentes et besoins qu’ils expriment quant à leur voyage. Ceux-ci peuvent être par exemple, la durée et le prix du séjour, la possibilité de se faire à manger, le type de voyage (en autonomie ou au sein d’un groupe)…
L’organisation mondiale du tourisme (OMT) a proposé une classification des voyageurs en neuf segments selon les motifs de visites comme l’indique la Figure 3.
Figure 3 : Classification des voyageurs selon l’OMT, (Guibilato, 1983)
Une autre segmentation possible est établie en fonction du type de tourisme recherché : tourisme vert, tourisme urbain, tourisme bleu, tourisme religieux, tourisme d’affaires… (études&analyses, 2018).
Du côté de l’offre, il existe plusieurs types d’acteurs associés à différentes offres de logements pour répondre aux divers besoins exprimés par les consommateurs. On peut ainsi distinguer les agences de voyage et tours opérateurs, les franchises et chaines hôtelières (Hilton, Ibis, …) et les hébergements de tous types détenus par des particuliers (hôtels, chambre d’hôtes, B&B, gites, maisons/appartements individuels…) Partant de cette segmentation, on déduit que la plateforme Fairbnb s’adresse, pour les offreurs, aux particuliers possédant une maison, un appartement, un hôtel ou encore une auberge B&B et souhaitant le louer à d’autres particuliers pour une durée limitée.
La plateforme met en avant des offres proposant différents types de logements (cf. Figure 4), dans plusieurs destinations européennes (cf. Figure 5), avec une large fourchette de prix : 30€ à 400€ la nuit (Fairbnb). Le voyageur peut affiner sa recherche selon plusieurs critères : nombre de lits (double/simple), présence d’une cuisine/salle de bain (partagée ou non), d’un espace de travail, activités aux alentours … À cela s’ajoutent des services optionnels proposés par les propriétaires tels qu’un service de ménage ou des visites guidées.
Figure 4 : Types de logements proposés à la location sur Fairbnb (Fairbnb).Figure 5 : Destinations couvertes par la plateforme (Fairbnb).
La stratégie de Fairbnb est donc de cibler plusieurs segments de voyageurs simultanément grâce à un large spectre d’offres, certes non personnalisé, mais susceptible d’attirer du monde par son volume.
La stratégie ayant été décidée et les segments de clients à attirer choisis, l’étude de la proposition de valeur de Fairbnb indique comment la plateforme répond aux attentes, besoins et problèmes selon le profil de ses clients. En tant que plateforme biface, Fairbnb a donc deux propositions de valeur distinctes : l’une à l’attention des hôtes, et l’autre concernant les voyageurs. Celles-ci sont résumées ci-dessous (Figure 6, Figure 7) selon le modèle du canevas de proposition de valeur (Wikicréa, 2019). Il présente sur la partie droite le profil client, correspondant aux attentes, besoins et problèmes du client, et sur la partie gauche, la proposition de valeur établie par Fairbnb, exposant les produits et services de la plateforme, les gains à l’utilisation pour le client et des solutions aux difficultés exprimées par ces derniers. À noter que les propositions de valeur ci-dessous ontété construites en s’inspirant de celles d’Airbnb, les deux étant très similaires car Fairbnb s’est construite en partant du modèle d’Airbnb (Onopia, 2018).
Figure 6 : Proposition de valeur pour les hôtes.Figure 7 : Proposition de valeur pour les voyageurs.
Les éléments distincts dans les propositions de valeurs de Fairbnb et Airbnb (surlignés en jaune sur les figures ci-dessus), et donc qui seraient susceptibles de motiver les consommateurs à utiliser cette plateforme plutôt qu’une autre, concernent majoritairement des résolutions la durabilité et de l’écoresponsabilité. Il est intéressant de noter que ces dissemblances restent parcimonieuses. L’offre est globalement une offre de substitution, or pour s’intégrer sur un marché très concurrentiel avec un leader, il est impératif de se différencier, d’avoir une valeur ajoutée. Si cette différenciation ne s’opère pas sur l’offre, sur quoi repose-t-elle ? Ainsi, l’on peut se demander comment et dans quelle mesure Fairbnb se différencie réellement des autres plateformes. C’est ce que nous allons analyser par la suite.
III) Le positionnement de Fairbnb au sein de l’écosystème de l’hébergement touristique
Comme l’indique la Figure 8, le tourisme est une industrie regroupant un riche réseau d’acteurs. Compte tenu de la grande diversité d’offres de location de courte durée présente sur le marché, Fairbnb se situe dans un environnement concurrentiel très fort, parfois déjà saturé (Rédaction, 2019). Deux catégories de concurrents sont distinguables. Les grands acteurs professionnels : agences de voyage, tours opérateurs, franchises et chaînes hôtelières (cf. la segmentation des offreurs) qui sont en concurrence indirecte ; et les autres plateformes en ligne pair à pair de location de logements de courte durée, formant la concurrence directe.
Figure 8 : Les acteurs du tourisme, (Steck, Strasdas, & Evelyn, 2000)
Pour les entreprises en concurrence indirecte, Fairbnb présente une forte valeur ajoutée : voyager autrement, moins cher, développement d’un lien social plus fort avec les locaux. Les clients ciblés, certes se recoupent, mais ne sont globalement pas les mêmes. Il est donc facile pour Fairbnb de se différencier.
Parmi les concurrents directs, sont à citer les géants Booking.com, Airbnb, Vrbo (anciennement HomeAway) et Abritel pour la France. La proposition de valeur présentée par Fairbnb est très similaire à celle de ces enseignes, notamment de celle de Airbnb dont elle s’est inspirée du principe. L’enjeu pour Fairbnb est ici de réussir à se différencier de ces enseignes afin de capter des clients et de ne pas être juste une plateforme de location d’hébergement supplémentaire.
Pour « sortir de l’ombre » des grands plateformes internationales, Fairbnb présente une offre de substitution destinée à conquérir plus spécifiquement une niche de marché restreinte, celle du tourisme durable et de l’écotourisme, à plus forte valeur ajoutée (Nelson, Partelow, Stäbler, Graci, & Fujitani, 2021). En effet, Fairbnb souhaite proposer une solution alternative qui minimiser les effets néfastes, abordés ci-dessus, dont ces concurrents sont accusés. La plateforme promeut donc un tourisme éthique et durable, à même de capter plus précisément les clients du segment du tourisme vert ou écotourisme, dont de plus en plus de voyageurs se disent attentifs (Nelson, Partelow, Stäbler, Graci, & Fujitani, 2021). L’enquête PIPAME de 2015 (Pipame, 2015) sur les enjeux et perspectives de l’économie collaborative a établi une typologie des Français selon cinq profils particuliers de demandeurs et offreurs collaboratifs (cf. Figure 9).
Figure 9 : Typologie des français en 2015 par rapport à la consommation collaborative, (Pipame, 2015)
Selon cette typologie, les cibles de Fairbnb sont les engagés et les futurs adeptes idéalistes. Les premiers placent les préoccupations sociales et environnementales au cœur de leur démarche et pratiquent la consommation collaborative au quotidien, tandis que les seconds sont fortement attachés à ces mêmes valeurs de solidarité, de respect de l’environnement, de convivialité et de partage mais ne sont des pratiquants que très occasionnels. Au total, cela représente 46% des personnes, mais avec plus des trois-quarts pour qui l’adhésion n’est pas totalement acquise, le modèle étant juste prometteur pour l’avenir. Ainsi, la niche visée est marginale sur le marché actuel, mais vouée à augmenter dans les années à venir.
La différence majeure réside dans l’organisation même de la plateforme. En effet, Fairbnb est une coopérative, la gouvernance est donc partagée entre tous ces utilisateurs, et est organisée en nœuds locaux qui forment un réseau de communautés interconnectées. L’idée est que chaque ville ou zone spécifique développe sa propre communauté sur la base du volontariat des personnes y habitant. Un tableau comparatif de Airbnb et Fairbnb est disponible en annexe.
Figure 10 : Modèle économique de Fairbnb, (Fairbnb, 2021).
Concernant son financement, la plateforme prélève des commissions sur le prix à payer par le voyageur lors de sa réservation (cf. Figure 10). La moitié de la valeur captée est gardée par Fairbnb, et l’autre moitié est réinvestie pour financer des projets communautaires propres à chaque nœud : un centre de distribution de nourriture en partenariat avec l’association Re-food pour lutter contre le gaspillage alimentaire à Porto, ou encore le financement du projet « Co.Co Farm 2021 » de la coopérative Terre Del Magra dans la région de la Ligurie en Italie pour une gestion des sols plus durable (Fairbnb, 2021).
L’objectif de cette politique est, selon Fairbnb, d’avoir une meilleure répartition de la valeur créée, qui bénéficie, non seulement à la plateforme, mais aussi aux résidents des zones touristiques. La redistribution des profits serait ainsi plus équitable au sein de la communauté qui les produit, selon un modèle d’économie circulaire. La plateforme veut se placer, dans l’esprit des consommateurs, comme une un acteur véritable de l’économie sociale et solidaire avec une structure pair à pair collaboratif, qui renoue avec les valeurs de partage, de durabilité et de solidarité.
Fairbnb crédibilise sa position en s’appuyant sur plusieurs piliers. En premier, la collaboration avec un troisième acteur : le secteur public (cf. Figure 8). Chaque hôte doit fournir la preuve qu’ils sont en règle avec les réglementations et autorités locales, et que la location de leur logement est déclarée et légale. Ensuite, le financement de projets choisis et gérés par les locaux présenté ci-dessus. Puis la règle « 1 host, 1 house » qui stipule que les propriétaires ne doivent posséder qu’un seul bien immobilier sur le marché de la location touristique pour être acceptés sur la plateforme, sachant que pour les zones sujettes à un fort phénomène de gentrification comme Venise ou Florence, le propriétaire doit également être résident. Les gros investisseurs immobiliers, possédant plusieurs propriétés dans les centres villes et destinées aux touristes ne peuvent donc pas être des hôtes sur la plateforme (Borg, 2021). Le dernier pilier est la transparence : dans le respect du RGPD, les données récoltées par Fairbnb sont partagées avec les municipalités, pour aider au développement futur des territoires. Un accord a notamment été signé entre Fairbnb et la ville de Gênes pour s’assurer que les annonces soient aux normes, la plateforme doit communiquer à la ville la liste des structures enregistrées et le nombre de réservations reçues. Elle a aussi la charge de récolter la taxe touristique imposée par la réglementation municipale puis de la reverser à la municipalité (Commune de Gênes, 2020).
Un élément décisif pour le développement et le succès de la plateforme est le dépassement de sa masse critique. Comme Fairbnb est une plateforme biface, cela est d’autant plus compliqué ; sans parler de la difficulté à initier une offre dans un environnement aussi concurrentiel. Pour ce faire, plusieurs stratégies ont été adoptées par celle-ci.
Le versant mobilisé en premier (pour ensuite attirer l’autre par effet de réseaux indirects) a été celui des hôtes. En effet, si l’on réfère aux façons de procéder pour ce faire mises en évidence par Parker, Van Alstyne et Choudary (2016), Fairbnb a choisi de « suivre l’appât », d’établir une « marquee strategy » et de privilégier le versant ayant la plus forte d’attraction, ici les hôtes (sans offre de location, il n’y a pas de potentiels locataires, alors que les propriétaires n’ont « rien à perdre » à être présent sur la plateforme car l’inscription est gratuite). La première méthode consiste à suivre le modèle d’une plateforme déjà existante, Airbnb, pour créer Fairbnb, cela joue un rôle « d’appât » susceptible d’attirer les clients qui feront face à une offre à laquelle ils sont familier. La différenciation s’effectue alors, non pas sur l’offre de service, mais sur le développement d’atouts secondaires, comme les partenariats avec des collectivités locales. La « marquee strategy » réside dans le ciblage de participants privilégiés, ici les ambassadeurs, qui assureront la promotion de la plateforme auprès de la multitude et inciteront les autres à venir sur cette dernière. Enfin, Fairbnb a avantagé le versant des hôtes avec l’absence de commissions prélevées à ceux-ci, et donc l’utilisation « gratuite » de la plateforme.
De plus, la mise en place d’une tarification différenciée selon le versant est un outil déterminant qui a également été souligné par Jean Tirole (Tirole, 2016) concernant la capacité d’une plateforme à atteindre la masse critique.
IV) Ressources, partenaires clés et modèle d’affaires
L’analyse du modèle d’affaires de Fairbnb permet de montrer comment la proposition de valeur de ce dernier est convertie en source de revenu et comment les ressources et partenaires stratégiques sont utilisés pour créer cette valeur. Avoir un bon modèle d’affaires est capital pour assurer la pérennité de la plateforme « a company has at least as much value to gain from developing an innovative new business model as from developing an innovative new technology » (Chesbrough, 2010).
Comme le souligne H. Chesbrough (2010), un modèles d’affaires a pour fonction d’articuler la proposition de valeur, d’identifier les segments de marchés et de préciser le mécanisme de création de revenu, d’estimer la structure des coûts et les potentiels profits, de décrire la position de la firme dans le réseau liant les consommateurs et les offreurs et de formuler la stratégie compétitive qui permet à l’entreprise de gagner et garder un avantage sur ses rivaux activités et ressources clés).
Les ressources sont les déterminants fondamentaux de l’avantage concurrentiel durable d’une entreprise. Ainsi, identifier ses ressources clés potentielles, les développer et les protéger est primordial pour toute entreprise souhaitant s’intégrer et dépasser la concurrence dans son environnement économique. Pour ce faire, les entreprises peuvent s’appuyer sur le modèle VRIN (aujourd’hui VRIO) développé en 1991 J. Barney selon lequel les ressources sont dites stratégiques si elles répondent aux quatre critères suivants : valorisable, rare, inimitable et non substituable (Barney, 1991).
Figure 11 : Les ressources et compétences stratégiques selon le modèle VRIN (L’analyse des ressources et des compétences, 2021).
Plusieurs ressources de Fairbnb peuvent être relevées, analysons dans quelle mesure elles sont stratégiques au regard de ce modèle. D’abord, les ressources tangibles qui correspondent aux ressources humaines, financières et techniques (Wikipedia). Avoir un portefeuille fourni de logements à louer est ressource pour telle plateforme, l’objectif étant d’avoir une offre riche et variée, et particulièrement dans des zones prisées où la demande est plus forte et donc l’appariement entre les deux versants (hôtes et voyageurs) de la plateforme est meilleur. Certes cette ressource est valorisable et substituable, mais pour Fairbnb elle n’est malheureusement ni rare ni inimitable car Fairbnb autorise le multihoming. À titre d’exemple, Airbnb comptait 5,6 millions d’offres de logements à travers le monde au 30/06/2021 (Airbnb, About us, 2021) contre seulement 21 nœuds actifs pour Fairbnb. Une autre ressource importante pour une plateforme de location de logements tel Fairbnb est son réseau d’hôtes. En effet, plus il y a d’hôtes, plus grand est l’inventaire dans lequel les voyageurs peuvent choisir un logement et vivre différentes expériences et séjours. Cette ressource est également valorisable et non substituable, mais pour le même argument que précédemment, elle est loin d’être rare et inimitable (4 millions d’hôtes sur Airbnb au 30/06/2021 (Airbnb, About us, 2021)). Il est toutefois intéressant de noter que si l’on considère seulement les hôtes « engagés » ou « futurs adeptes idéalistes » (cf. III), alors cette ressource se différencie de celle d’autres plateformes similaires et reprend un aspect rare et inimitable. Cela nous amène à une troisième ressource : les ambassadeurs. Ce sont des hôtes ou voyageurs qui sont très investis dans le développement, ils promeuvent la plateforme dans chaque nœud et sont responsables de son rayonnement. Cette ressource présente bien les quatre critères VRIN et est donc clé pour Fairbnb.
D’un point de vue technologique, tout ce qui a trait au système d’information puis à leur analyse sont également des ressources car être en mesure de recueillir des informations sur les utilisateurs et de les traiter est essentiel pour le développement de la plateforme. Il s’agit des bases de données stockant les profils utilisateurs et leur comportement (« Internet-browsing technical data, Registration Data, Host Profile data, Payment data and Listing data » (Fairbnb, Privacy statement)), et des algorithmes d’évaluation et de management de la performance notamment. Les algorithmes de recherche et d’appariement utilisés par les voyageurs lorsqu’ils recherchent une location sur la plateforme en fonction de leurs critères sont propres à Fairbnb et sont aussi essentiels. Les bases de données sont bien une ressource clé car la liste des utilisateurs de Fairbnb est unique et leurs habitudes sur cette plateforme aussi, bien que cela soit discutable étant donné que les utilisateurs peuvent être présents sur plusieurs plateformes similaires.
Ensuite, il existe des ressources intangibles qui regroupent les procédures et routines mises en place par l’entreprise. Pour Fairbnb, l’implication et le sentiment d’appartenance organisationnelle due à la structure de communauté et de coopérative valide les quatre critères VRIN. De même, la politique RSE, très développée chez Fairbnb, peut être considérée comme une ressource clé.
Afin de se procurer les ressources, les entreprises sont amenées à faire appel aux services de tiers appelés partenaires. Les partenaires clés les plus importants pour Fairbnb sont également une de ces ressources clés : les hôtes. Comme expliqué ci-dessus, aident à délivrer la proposition de valeur du côté de la demande (voyageurs) car atteindre une masse critique pour l’offre et garantir sa grande diversité est important pour leur proposition de valeur. Une autre catégorie de partenaires regroupe les fournisseurs de solutions de paiement en ligne : comme le rappelle G. Dang Nguyen (Nguyen, Chapitre 2 : braderies high tech et plateformes, 2020), une des missions phare d’une plateforme de pair à pair collaboratif est de gérer les relations entre versants. Dans ce cas, il s’agit notamment d’organiser concrètement les transactions. Pour Fairbnb, ces partenaires sont MangoPay, Crédit Mutuel Arkea et Payline by monext (Fairbnb, terms of use).
Figure 12 : Les partenaires de Fairbnb pour la gestion du paiement en ligne
Enfin, Fairbnb appuie sa proposition de valeur et son engagement durable sur des partenariats avec des collectivités locales et le reversement d’une partie de la valeur captée à des ONG pour financer des projets communautaires. Ces instances représentent un atout fort pour Fairbnb car il s’agit d’un point de différenciation de la plateforme par rapport aux autres. Ces partenariats sont donc également clés. Travailler avec des ONG est un choix stratégique : celles-ci aident Fairbnb à mettre en œuvre ses engagements pour le développement durable et à promouvoir sa politique RSE, qui rappelons-le, constitue une ressource clé. Cette collaboration est un bon argument marketing pour la niche de marché visée (écoresponsable, durable, …) et permet à Fairbnb de s’attirer les faveurs et la reconnaissance des utilisateurs, ces derniers étant plus sensibles aux problématiques précédentes (cf. partie III). L’entreprise minimise ainsi le risque de boycott de sa plateforme, comme ce qui arrive à Airbnb ; on peut même supposer qu’elle draine les ex-utilisateurs désabusés de Airbnb grâce à ces partenariats.
Le modèle d’affaires peut être formalisé selon le canevas proposé par Osterwalder & Pigneur (2010). C’est un outil permettant de cartographier synthétiquement les pierres angulaires d’un projet.
Le business model canevas de Fairbnb (Figure 13) résume les divers éléments structurant la coopérative Fairbnb présentés dans les paragraphes et parties précédentes.
Figure 13 : Business model canevas de Fairbnb selon le modèle d’Osterwalder et Pigneur.
Comme le souligne G. Nguyen (Chapitre 2 : braderies high tech et plateformes, 2020), l’avantage concurrentiel d’une plateforme se construit sur la gestion de la dynamique des effets de réseaux directs et indirects. Fairbnb peine à construire un important réseau d’utilisateur car le marché est déjà structuré et trusté par d’autres plateformes (cf. concurrents). Construire une nouvelle base de clients fidélisés est ici d’autant plus difficile car que le coût de transfert des utilisateurs lié au changement de plateforme est élevé : les utilisateurs potentiels peuvent déjà avoir acquis une notoriété sur un autre site (hôtes cinq étoiles sur Airbnb) et que le système de commentaires et de notation est peu développé chez Fairbnb : on ne peut y avoir accès si l’on n’est pas membre du réseau social fairbnb.coop. C’est une faiblesse pour Fairbnb car les systèmes d’évaluations sont des éléments clés du modèle des plateformes : ils contribuent à réduire les coûts de transactions dû aux asymétries d’informations entre les versants et à garantir la qualité du produit.
Le fait que le portefeuille de logements et le réseau d’hôtes ne soient pas rare et inimitable est aussi un fort handicap pour le développement de Fairbnb car être en situation de neutralité compétitive sur ces points met grandement en péril l’entretien des effets de réseaux.
Selon la théorie de la contingence, l’environnement est un facteur externe à ne pas négliger. Si l’on se réfère aux critères émis par Thomas R. Burns & Georges M. Stalker (1961), Fairbnb se situe dans un environnement dynamique et axé sur la technologie (marché et technologie en incertitude forte). Ainsi, le site web (design, ergonomie, algorithmes…) et les compétences en systèmes d’informations, traitements de données, et algorithmes d’appariements doivent être parfaites. De ce point de vue, c’est aussi une faiblesse de Fairbnb car le site n’est pas très facile d’utilisation (les pages sont mal répertoriées, difficiles à trouver et manquantes selon la langue choisie), lent et les bases de données peu fournies.
Concernant la coopération avec les ONG et projets locaux, un bémol est à retenir: la communication et le manque de transparence sur les activités sont des éléments susceptibles d’altérer la confiance des utilisateurs. La transparence financière, la cohérence des actions mises en place et les processus de décisions des ONG sont par ailleurs des aspects souvent critiqués : le constat émis par la fondation Prometheus à l’issue de la sixième édition (2016) de son baromètre de transparence des ONG est qu’elles demeurent opaques (Carayon, 2016).
Néanmoins, des forces sont à relever : Fairbnb a su développer un réseau de partenaires institutionnels étoffé, ce qui assoit sa crédibilité et accroit sa capacité à gagner de l’argent via des levées de fonds. Ce sont un million d’euros qui ont récemment été récolté par la plateforme (Bologna, 2021), ce montant est toutefois à mettre en perspective car même s’il apparait conséquent, il ne sera pas suffisant pour très longtemps.
Une stratégie d’engagement (Nguyen, Chapitre 2 : braderies high tech et plateformes, 2020) est également développée : Fairbnb est partenaires et sponsorise un nombre croissant d’évènements comme le marathon de Venise (Fairbnb, 2021).
Selon Alfred D. Chandler, la stratégie est un facteur interne de contingence, et l’adoption de toute stratégie implique des changements de structures dans l’organisation en question. Pour accroitre son rayonnement, Fairbnb fait le choix judicieux d’une stratégie d’expansion géographique grâce au développement d’un organe « administratif ». Pour cela, la plateforme s’est appuyée sur un des éléments qui lui est propre : son réseau d’ambassadeurs.
V) Conclusion et limites.
Le plateforme Fairbnb, bien que toujours en phase de développement, nourrit l’espoir d’un tourisme durable, éthique et économiquement viable, en mesure de contrer les effets négatifs du tourisme de masse.
Le projet gagne en visibilité et en reconnaissance grâce à des articles à son sujet dans des journaux ou blogs renommés (Girardi, 2019, Manthei, 2021, Williams, 2021, Zee, 2019). Un rapport dirigé par la Commission européenne a mentionné Fairbnb comme étant un « exemple à succès » montrant le « potentiel des plateformes sociales et nouvelles technologies peut aider l’économie sociale à poursuivre sa mission et devenir plus durable » (International, UNU-MERIT, & Research, 2020). La plateforme a également été lauréate du prix international du tourisme durable 2020 de Skål International, une organisation professionnelle du tourisme dans la catégorie « Urban accommodation » (Skål International, 2020).
Une étude réalisée en 2021 a examiné dans quelle mesure Airbnb et Fairbnb représentent l’économie collaborative, la conclusion a été que cette dernière est un plus fort exemple de l’économie sociale et solidaire, et du pair à pair collaboratif que son homologue Airbnb (Petruzzia, Marquesa, & Sheppard, 2021).
Ainsi, la coopérative Fairbnb montre les qualités d’une plateforme collaborative dans laquelle les valeurs de partage, d’éthique et de durabilité sont présentes. Malgré les reconnaissances extérieures de plus en plus nombreuses, force est de constater que la plateforme soutient le respect de ses valeurs et engagements uniquement par une politique d’autorégulation basée sur différents axes présentés en amont. Cette stratégie unilatérale de s’imposer publiquement des obligations pour neutraliser l’opportunisme est évoquée par Lucien Karpik (2007) dans L’économie des singularités. Par exemple, la vérification des exigences données par la plateforme aux hôtes n’est pas claire : comment s’assurent-ils qu’un hôte ne loue pas un bien, non référencé sur Fairbnb, sur une autre plateforme, ce qui serait contraire à la règle « one host one home ». J’ai contacté l’ambassadrice parisienne de Fairbnb pour illuminer ces zones d’ombres, mais n’ai pas eu de retour… Des certifications, un contrôle avec des organismes impartiaux et reconnus, ainsi que des partenariats clairs avec des instances gouvernementales seraient préférables afin d’assurer la bonne mise en application de leurs affirmations et les réelles retombées sur les communautés et le tourisme. La coopérative étant jeune, il est donc difficile de certifier les améliorations apportées par celles-ci par rapport aux problèmes qu’elle prétend minimiser, d’autant plus que les lieux de présence de la plateforme sont majoritairement des villes très touristique présentant une offre déjà saturée, ce qui semble paradoxal et risquerait à l’inverse d’empirer la situation. En outre, les hôtes sont autorisés à être présent sur plusieurs plateformes, ce qui leur assurerait alors juste un référencement supplémentaire. La décision de tolérer le multi-homing est à double tranchant. Certes, il est bénéfique (et nécessaire !) pour Fairbnb car il aide la coexistence entre plusieurs plateformes en tempérant les effets de réseau à mener à une situation de monopole « winner takes all » (c’est presque le cas avec Airbnb).
B. Jullien et W. Sand-Zantman (2019) expliquent que le multi référencement permet aux acteurs de tirer parti d’effets de réseaux plus importants, ce qui augmentent l’attractivité de Fairbnb face à un Airbnb prédominant. Mais cela impacte la crédibilité et la réalité de l’innovation mise en avant par Fairbnb : si une même maison peut être indifféremment sur une autre plateforme, où est l’intérêt de cette plateforme et en quoi la location est-elle plus responsable sur Fairbnb ?
L’avenir de Fairbnb reste pour le moment très incertain : celle-ci n’a clairement pas atteint la masse critique au regard du nombre restreint de destinations couvertes, du nombre de locations effectuées via celle-ci (beaucoup de résultats sur la plateforme présentent des offres pour lesquelles les hôtes n’ont reçu aucunes réservations), et du nombre d’utilisateurs (Fairbnb, 2021). Sa pérennité et son expansion seront de plus en plus compliqués sachant que Airbnb a récemment annoncé une nouvelle politique pour un tourisme responsable, ce qui atténue la différenciation de ces deux acteurs (Airbnb, Airbnb annonce une série d’engagements pour un tourisme responsable, 2021).
Une matrice SWOT résumant tous les points abordés dans cette étude est disponible en annexe (Tableau 2).
Véritable initiative durable et solidaire ou argument marketing de type greenwashing pour attirer un nouveau segment de marché ? Il est difficile de trancher à l’heure actuelle, même s’il apparaît que ce soit davantage une plateforme commerciale agrégeant des communautés par des objectifs sociaux et de durabilité qu’une réelle plateforme de pair à pair collaboratif. Une prise de recul avec le temps sera peut-être en mesure de guider la réponse.
Borg, P. J. (2021). EcoBnB & FairBnB.coop Come base di ripartenza post-covid19 Per un turismo piu sostenibile. Venise: Université Ca’Foscari de Venise.
Burns, T. R., & Stalker, G. M. (1961). The Management of innovation .
Guibilato, G. (1983). Économie touristique. Delta & spés.
International, Q.-P., UNU-MERIT, & Research, M. I. (2020). New technologies and digitisation Opportunities and challenges for the social economy and social economy enterprises. European Commission.
Jullien, B., & Sand-Zantman, W. (2019). The Economics of Platforms: A Theory Guide for Competition Policy. TSE Digital Center Policy Papers series.
Karpik, L. (2007). L’économie des singularités. Gallimard.
NGuyen, G. D. (2016). Semaine 1, Partie 1 : Caractériser le pair à pair. Dans MOOC Comprendre l’économie collaborative.
NGuyen, G. D. (2016). Semaine 3, Partie 1 : Splendeur et misère du néo-entrepreneur. Dans MOOC Comprendre l’économie collaborative.
NGuyen, G. D. (2022). Chapitre 2 : braderies high tech et plateformes. Dans G. D. Nguyen. À paraître
Nieuwland, S., & Van Melik, R. (2020). Regulating Airbnb: how cities deal with perceived negative externalities of short-term rentals. Dans Current Issues in Tourisme, Volume 23 (pp. 811-825).
Onopia. (2018, février 2). Étude du modèle d’affaires Airbnb. Récupéré sur Slideshare:
Petruzzia, M. A., Marquesa, C., & Sheppard, V. (2021). TO SHARE OR TO EXCHANGE: An analysis of the sharing economy characteristics of Airbnb and Fairbnb.coop. International Journal of Hospitality Management.
Pipame. (2015). Typologie de cinq profils de particuliers demandeurs et offreurs collaboratifs. Dans Pipame : enjeux et perspectives de la consommation collaborative (p. 219). Martine Automme, Nicole Merle-Lamoot.
Pouly, J. (2016). Semaine 4, partie 3 : Construire un cadre sût, équitable et stimulant. Dans MOOC Comprendre l’économie collbaorative.
Steck, B., Strasdas, W., & Evelyn, G. (2000). Titre Le tourisme dans la coopération technique: un guide pour la conception, la planification et la réalisation de mesures d'accompagnement destinées aux projets de développement rural et de conservation. GTZ.
Stergiou, D. P., & Farmaki, A. (2019). Resident perceptions of the impacts of P2P accommodation: Implications for neighbourhoods. Internal Journal of Hospitality Management.
Tirole, J. (2016). Économie des biens communs. Paris: Odile Jacob.
Van Alstyne, M., Choudary, S., & Parker, G. (2016). Platform Revolution: How Networked Markets Are Transforming the Economy and How to Make Them Work for You. New York: W. W. Norton & Cie.
Ces dernières années, un exode rural massif a rassemblé les populations de nombreuses régions indiennes dans les grandes villes du sud de l’Inde. Cette évolution démographique a eu pour impact de faire de ces villes, qui étaient jusque-là des bastions de leur langue régionale (Kannada, Tamoul), un melting pot de toutes les langues indiennes. On retrouve ainsi dans ces villes des populations entières qui ne parlent pas la même langue et qui ont des problèmes pour s’exprimer dans la langue historique de la ville.
Dans ce contexte, les centres téléphoniques de relations clients d’une grande entreprise du sud de l’Inde sont dans l’incapacité de rediriger les appels de ses clients vers des opérateurs parlant la même langue qu’eux. Alors qu’ils utilisaient jusque-là des données géographiques pour savoir vers quel opérateur rediriger un appel. Un système inefficace aujourd’hui. C’est dans cette optique que cette entreprise cherche à développer un assistant vocal permettant de détecter la langue parlée par le client et de le rediriger vers le bon opérateur.
Un assistant vocal: pour qui ? comment ?
Dans ce cadre, nous intervenons pour Airtel, le premier opérateur de téléphonie mobile en Inde. Grâce à cet assistant vocal, le client sera directement redirigé vers un conseiller pouvant répondre à sa question dans sa langue natale.
Pour sa création, l’entreprise nous demande à partir d’un clip vocal de moins de 5 secondes sous format .wav de détecter la langue parlée par le client pour pouvoir rediriger l’appel vers le bon conseiller. L’entreprise se chargera par la suite de rediriger la personne directement vers quelqu’un qui sera familier avec son problème à l’aide d’une reconnaissance vocale du problème exposé.
Schéma illustrant le cas d’usage
La grande majorité des habitants et néo-habitants des grandes villes du Sud de l’Inde maîtrisent les rudiments de l’anglais et de l’hindi, qui sont les langues officielles de l’union indienne. L’idée est donc de demander à l’utilisateur en Anglais et en Hindi d’exposer son problème dans la langue de son choix. Airtel se charge d’envoyer les 5 premières secondes de parole du client à notre système qui devrait pouvoir analyser et détecter la langue à partir des 5 premières secondes d’audio. Après avoir détecté la langue, notre système renvoie la réponse chez Airtel qui pourra rediriger l’appel vers le bon conseiller.
Il a été convenu avec l’entreprise d’obtenir un taux de réussite supérieur à 80% pour que le système soit considéré comme satisfaisant.
Quelles données utiliser ?
Pour réaliser notre part de cet assistant vocal, nous avions besoin d’enregistrements vocaux d’Indiens. Le nombre de langues parlées en Inde étant élevé, nous avons décidé de nous concentrer sur les langues principales du sud de l’Inde. Ces dernières correspondent à celles traditionnelles du sud de l’Inde, le Kannada, le Tamoul et le Telugu, ainsi que l’Hindi (parlé par plus de 50% de la population Indienne) et l’anglais. De plus, ces cinq langues couvrent environ 99% des habitants des grandes villes du Sud de l’Inde et représentent l’intégralité des langues gérées dans les call centers.
Dans un premier temps, nous avons utilisé des données de différents datasets: Common Voice, Google Research, LibriVox, LibriSpeech et Microsoft Research.
Lors de notre projet, nous avons dû effectuer un changement de dataset car les audios provenaient de datasets différents pour chaque langue. Ils représentaient chacun des conditions d’enregistrement différentes (matériels professionnels ou amateurs, lieux d’enregistrement…). C’est ce facteur qui influe la classification et c’est ce facteur qui peut être détecté par notre modèle plutôt que la langue parlée.
Ainsi, nous avons donc testé notre modèle avec de nouveaux datasets pour les trois langues régionales provenant de la même source (Google Research). Nous considérerons donc, par la suite, les nouveaux jeux de données.
Descriptions des datasets
Après une étude des statistiques descriptives de nos données, nous remarquons que la majorité des fichiers audios dont nous disposons ont une durée entre 5 à 10s.
Graphique représentant le nombre d’enregistrements correspondant à une certaine durée pour chaque langue
Langues
Durée d’enregistrement
Anglais
323 min
Tamoul
424 min
Telugu
341 min
Hindi
173 min
Kannada
458 min
Tableau synthétisant la durée d’enregistrement pour chaque langue
Graphique représentant le nombre d’enregistrements pour chaque genre (femme ou homme)
Enfin, les locuteurs sont différents et ces enregistrements concernent globalement autant d’hommes que de femmes, d’âges variés, parlant de différents sujets. Ces données sont donc très utiles dans notre cas.
Des enregistrements aux images
Afin d’homogénéiser nos différentes données audios, celles-ci doivent être mises sous le même format, les fichiers MP3 seront donc convertis en fichier WAV car c’est ce format qui est le plus utilisé pour les traitements audio. Tous les fichiers audios seront aussi échantillonnés en 8 kHz car c’est la fréquence utilisée en téléphonie.
Nous avons ensuite découpé nos fichiers audios pour ne garder que des enregistrements de cinq secondes pour correspondre à notre cas d’usage.
Enfin, en s’inspirant de certains travaux de Deep learning pour le speech-to-text, nous avons décidé d’utiliser un modèle de réseaux de neurones convolutifs qui prend en entrée une image d’un mel-spectrogramme. Un spectrogramme est une représentation visuelle du son en temps et en fréquence avec des intensités de pixels représentant l’amplitude ou l’énergie du son à ce moment et à cette fréquence. L’avantage d’utiliser des spectrogrammes par rapport aux données wav brutes est que notre analyse sera abordée comme étant un problème de classification d’image.
Image d’un mel-spectrogramme générée à partir d’un audio de 5 secondes
Ci-dessous, le nombre d’images obtenues pour chaque langue :
Langues
Kannada
Telugu
Tamil
Anglais
Hindi
Nombre d’images
3039
1478
2861
1585
2081
Nombre d’images obtenues pour chaque langue
Des résultats satisfaisants?
Comme évoqué précédemment, nous avons utilisé un réseau de neurones convolutifs créé à l’aide de Keras sous Python.
Premier modèle (différentes sources de datasets)
Deuxième modèle (changement de datasets)
Notre algorithme arrive à prédire la bonne langue, en moyenne, pour 94% (accuracy) des données.
Notre algorithme est moins performant puisqu’il se trompe dans 18% des cas (accuracy = 0.82).
Tableau des résultats obtenus pour les deux modèles
Les matrices de confusion permettent d’exprimer les prédictions de notre algorithme par rapport à la véritable langue à laquelle appartient une image. On remarque clairement une baisse de l’efficacité du modèle avec le changement des datasets. Notre modèle semble avoir des difficultés pour différencier les trois langues traditionnelles du sud de l’Inde (le Kannada, le Tamoul et le Telugu). Cette différence d’efficacité s’explique par la grande ressemblance entre ces trois langues.
Nous avons donc joué sur les variables de notre modèle, pour améliorer sa performance. Voici les résultats du modèle final:
Notre modèle final estime la bonne langue dans 91% des cas. De plus, les résultats pour chaque langue sont supérieurs à 80%. Ces derniers respectent donc le taux fixé par l’entreprise (taux d’erreur inférieur à 20%).
Et pour la suite ?
Des améliorations sont possibles pour notre algorithme, l’entreprise Airtel pourra continuer l’entraînement de l’algorithme avec ses propres datasets. La taille du dataset peut aussi être augmentée en ajoutant un bruit de fond qui correspondrait à l’environnement d’un client qui appellerait le call center, cela permettrait d’augmenter l’efficacité de l’algorithme pour notre cas d’usage. Notre algorithme de détection de langues peut être testé sur d’autres langues indiennes (comme le Bengali, le Gujarati, le Punjabi) afin de vérifier l’efficacité de celui-ci.
Déploiement
Pour la mise en production de notre algorithme, celui-ci utilisera la voix du client afin de faire une prédiction sur la langue de celui-ci. Les lois en Inde concernant l’enregistrement de la voix des clients ne sont pas clairement définies, les entreprises peuvent enregistrer des appels de clients sans leurs consentements. Notre algorithme est donc en adéquation avec la loi indienne.
L’économie collaborative est un modèle socio-économique qui repose sur le partage ou l’échange de biens, de services ou de connaissances entre particuliers. La direction générale de la concurrence, de la consommation et de la répression des fraudes la définit de la manière suivante : « L’économie collaborative, également appelée économie de partage, ou de pair à pair, s’avère être aujourd’hui un mode novateur de consommation en matière d’échanges sur les plateformes d’offres commerciales de biens et de services entre particuliers » [1]. Pour assurer ce concept de partage entre particuliers, des structures diverses, telles que des plateformes, associations ou projets par exemple, se mettent en place pour jouer le rôle d’intermédiaires.
Le secteur agricole adopte de plus en plus de démarches collaboratives pour assurer l’alimentation de la population. Même si nous accordons de moins en moins de budget à notre alimentation [2], bien se nourrir est un besoin de première nécessité. Alors qu’une personne sur 9 souffre de sous-alimentation dans le monde en 2017 [3], la crise sanitaire mondiale que nous vivons actuellement a mis en lumière le contraste complexe entre une planète de plus en plus peuplée, des ressources naturelles qui s’appauvrissent et malgré tout, le besoin indéniable d’assurer l’alimentation saine de toute la population, notamment par l’entraide entre consommateurs et avec les producteurs. En France, comme dans plusieurs autres pays d’ailleurs, le confinement du début de l’année a permis à de nombreuses personnes de remettre en question leur mode de consommation, notamment dans le domaine de l’alimentation. Une volonté de manger sain, bio et local s’est répandue sur le territoire et cela a favorisé le développement des approvisionnements en circuits courts [4]. Les AMAP (Associations pour le Maintien d’une Agriculture Paysanne), qui visent à rapprocher localement un groupe de consommateurs engagés avec des petits producteurs, s’inscrivent dans cette démarche. En effet, elles répondent au besoin de se nourrir sainement tout en bénéficiant de lien social et de transparence, via un système de distribution de paniers alimentaires en circuit court.
Cette étude vise à éclaircir le contexte complexe que subit le secteur agricole actuellement et à analyser le positionnement et le business model des AMAP, en particulier de l’AMAP de Plougonvelin, Penn Ar Bed [5], dans ce vaste écosystème de l’alimentation durable et saine.
Démarche d’étude de la structure d’économie collaborative choisie : l’AMAP Penn Ar Bed
Dans le cadre de cette étude, ma démarche s’est déroulée comme l’indique le schéma ci-dessus. Après une étude bibliographique de l’environnement, du contexte et de la concurrence et proposition de valeur des AMAP, je me suis renseignée pour choisir un cas d’étude, une AMAP en particulier, intéressante à étudier et à comparer à d’autres AMAP et d’autres structures concurrentes. Ce choix s’est fait après des discussions informelles avec des amapiens (parisiens et bretons). J’ai pu ensuite structurer l’étude du Business Model de l’AMAP Penn Ar Bed. J’ai décidé de contacter la Présidente de cette AMAP, afin d’avoir des données plus précises, qualitatives et quantitatives, pour mon analyse. J’ai eu l’occasion d’effectuer un entretien téléphonique puisqu’une visite en présentiel n’était pas possible à cause du contexte sanitaire.
Dans ce rapport, nous verrons donc les résultats de ces recherches et de cet entretien, que j’ai expliqués puis analysés, ce qui permet d’avoir une idée précise du Business Model de l’AMAP Penn Ar Bed.
I – Contexte et environnement du secteur agricole
Cette année, entre les débats sur les lois gouvernementales sur l’agriculture, la prise de conscience écologique grandissante et le confinement dû à la crise sanitaire mondiale, le secteur agricole se situe au cœur d’un marché complexe, reflet de ce contexte tendu.
1) Les débats politiques autour de l’agriculture
Depuis plusieurs mois, les réformes concernant la loi PAC (Politique Agricole Commune) sont débattues en Europe.
La promulgation de la loi PAC remonte à 1962, à la sortie de la Seconde Guerre Mondiale [6], période pendant laquelle il était nécessaire de produire intensément pour nourrir toute la population, malgré les destructions massives de la guerre. Cette loi visait donc à favoriser et aider les agriculteurs avec une production importante et intensive.
De nos jours, ce besoin n’est plus une priorité, puisque le contexte du changement climatique nous amène à devoir repenser notre agriculture pour qu’elle soit plus durable. Cependant, cette loi privilégie encore les grands producteurs avec un haut rendement, ce qui favorise la monoculture qui appauvrit nos sols.
Depuis les années 2000, la loi PAC a été réformée pour s’adapter au contexte européen qui a évolué et pour promouvoir des pratiques plus écologiques. Néanmoins, seulement 30% des aides versées aux agriculteurs concernent, dans la réforme de 2013, des pratiques plus vertes, en faveur de la biodiversité. Ces aides ne peuvent pas être perçues par des petits producteurs locaux, tels que ceux des AMAP par exemple, dont les rendements sont jugés trop faibles. Or, de plus en plus d’agriculteurs souffrent de dépression, voire se suicident, notamment du fait de difficultés financières et de manque de soutien [7].
La loi PAC ne fait plus l’unanimité aujourd’hui, c’est pourquoi elle est actuellement au cœur de débats pour réorienter l’agriculture vers des pratiques plus durables et soutenir les petits agriculteurs de plus en plus démunis.
Les AMAP ont ainsi pour mission de soutenir les paysans avec de la trésorerie garantie grâce à un paiement intégral en début de saison et réduire les inégalités apparues à cause de la loi PAC sur la production massive.
2) Alimentation et changement climatique
Le contexte climatique des dernières années s’aggrave vite et le secteur agricole est un des premiers touchés. [8] De plus en plus de sécheresses, tempêtes, inondations et autres catastrophes naturelles sont dénombrées, y compris dans des pays moins touchés habituellement, comme la France. Cela a souvent pour conséquence de ravager les productions agricoles et de mettre en péril la survie des petits producteurs, peu soutenus par l’Etat.
Pour remédier à cela, plusieurs initiatives et nouvelles méthodes de production sont mises en place, telles que la permaculture ou les circuits courts. Ces projets gagnent petit à petit de l’importance au sein du territoire français et également sur la scène internationale pour mener le secteur de l’alimentation vers des pratiques durables et respectueuses de l’environnement. Tant pour la production que la consommation, la conscience écologique s’éveille peu à peu.
3) L’impact du confinement sur les circuits courts
La crise sanitaire que nous connaissons actuellement, liée à la pandémie de la Covid-19 accélère cette prise de conscience environnementale. Manger local et bio est devenu important pour nombre de foyers, notamment depuis les confinements successifs, qui ont contribué aux modifications des comportements des consommateurs. [4] Les circuits courts, et notamment les AMAP, comptent de plus en plus d’adhérents, désireux d’adopter une consommation alimentaire locale et raisonnée.
Les populations ont fait preuve de beaucoup de solidarité pendant cette période troublante et difficile. C’est le cas par exemple à Plougonvelin, où le soutien aux producteurs locaux était une priorité [9].
L’AMAP Penn Ar Bed a d’ailleurs pu bénéficier de visibilité dans ce contexte, tout comme de nombreuses autres AMAP en Bretagne par exemple à Bannalec, où le nombre d’adhérents et de contrats a augmenté malgré les craintes des producteurs sur le déroulement du confinement [10]. Les gestes barrières et de distanciation sociale peuvent en effet rendre réticents les consommateurs à sortir de chez eux. En France, les ventes en drive ont d’ailleurs augmenté de 61% entre le 9 et le 15 mars et l’e-commerce de 90% [9]. De nombreuses structures du secteur agricole, dont les AMAP, se sont donc organisées pour s’adapter aux contraintes des confinements et de plus en plus de citoyens ont opté pour cette alternative plutôt que les hypermarchés, préférant la vente en plein air, d’autant plus que le local est souvent associé à la qualité et la confiance.
Le principe des AMAP prend tout son sens dans ce contexte d’engagement environnemental et social. En effet, le lien social entre producteurs et consommateurs est un des piliers du système des AMAP, couplé à une volonté de favoriser l’agroécologie et la nourriture locale et bio.
Reste à savoir si cet engagement se poursuivra post-confinement…
II – Positionnement des AMAP dans l’écosystème agricole
Dans ce contexte complexe du secteur agricole, les AMAP constituent une alternative prometteuse pour se nourrir en circuit court et faire fleurir l’économie collaborative.
1) Principe de fonctionnement et Historique des AMAP
Une AMAP (Association pour le Maintien d’une Agriculture Paysanne) est une association loi 1901 qui rassemble plusieurs producteurs avec un groupe de consommateurs – en moyenne 50 personnes – qui sont adhérents à l’association. En tant qu’adhérents, ils s’engagent à payer les producteurs pour toute la saison – en général un semestre ou une année – en échange de paniers hebdomadaires de produits alimentaires frais, locaux et de saison. On trouve dans ces paniers principalement des fruits et légumes, mais dans certaines AMAP, il peut également y avoir des œufs, du miel, de la viande et même des galettes ou des crêpes en Bretagne, ou encore de la bière, comme c’est le cas dans l’AMAP de Penn Ar Bed. Par leur engagement en tant qu’adhérents de l’association, les consommateurs doivent également aider de temps en temps pour les distributions des paniers ou pour accompagner les producteurs. Ils bénéficient en retour d’événements sociaux comme des pique-niques partagés avec les autres adhérents, appelés amapiens, mais aussi d’idées de recettes de la part des producteurs et des opportunités pour visiter leurs fermes et en apprendre plus sur leur métier, au plus grand plaisir des familles venues avec leurs enfants.
Fonctionnement et proposition de valeur de l’AMAP Penn Ar Bed
La première AMAP a été créée en France en 2001 dans le Var en Provence à l’occasion d’un “café-écolo” autour de l’alimentation et en particulier la “malbouffe”. Le concept est inspiré des Tei-Kei, apparues au Japon en 1965 pour remettre en confiance les consommateurs après plusieurs crises alimentaires. Tei-kei signifie d’ailleurs littéralement “mettre un visage sur le producteur”. [11] D’autres structures similaires existent à l’international, comme les CSA (Community Supported Agriculture) aux Etats-Unis, au Canada ou en Grande-Bretagne par exemple, pour rapprocher producteurs et consommateurs et répondre au besoin des populations de se nourrir sainement, si possible biologiquement, et de manière transparente, dans un monde de plus en plus peuplé.
On dénombre désormais plus de 2000 AMAP en France en 2015 [12]. Cela représente plus de 250 000 amapien.ne.s, et donc encore plus de consommateurs de paniers issus d’AMAP !
2) En quoi les AMAP font-elles partie de l’économie collaborative ?
Les AMAP sont des structures d’économie collaborative puisqu’elles fonctionnent sur un système d’organisation collaboratif qui prône la valorisation sociale, via la création de processus de socialisation autour d’activités qui rassemblent adhérents et producteurs, et le partage des risques, via les contrats annuels ou semestriels entre le groupe de consommateurs et les producteurs. Enfin, les AMAP visent également à redynamiser l’économie locale par un mix marchand-bénévolat des adhérents à l’AMAP.
Ces structures associatives sont non lucratives, donc elles ne sont pas en constante recherche de profit. Ainsi, elles fonctionnent grâce à l’engagement bénévole des adhérents et elles valorisent la proximité entre ces consommateurs-bénévoles et les producteurs. Les AMAP sont donc des structures de pair à pair collaboratives.
3) Proposition de valeur des AMAP par rapport à la concurrence
Il existe deux catégories de concurrence au système des AMAP : la grande distribution et les épiceries bios, qui sont une concurrence indirecte, et les autres formes de circuits courts, qui regroupent les concurrents directs.
Dans le premier cas, la grande distribution et les épiceries bios (La Vie Claire, Biocoop, etc) ne rendent pas le service de proximité avec le producteur, et, en ce sens, les AMAP ont une grande valeur ajoutée et peuvent aisément se différencier. De plus, les supermarchés font beaucoup plus de marge sur leurs produits bios que sur les autres, car les consommateurs désireux d’acheter bio sont prêts à payer plus cher. Ainsi, les prix des paniers des AMAP peuvent être avantageux.
Parmi les concurrents directs, on trouve les ventes directement à la ferme, les marchés de plein air, et les plateformes telles que La Ruche Qui Dit Oui. Comme les AMAP, ces structures ne fournissent pas seulement un bien privé (nourriture) mais également un service (lien social, visites des fermes, échanges entre consommateurs et avec producteurs, événements, partage et échange de recettes). Dans ce service, l’AMAP tente d’ailleurs d’aller plus loin que les autres initiatives, en créant une véritable communauté engagée et solidaire.
L’entreprise La Ruche Qui Dit Oui diffère en effet sur plusieurs points fondamentaux des AMAP, notamment le choix de la structure administrative. La Ruche Qui Dit Oui, au contraire des AMAP, est une structure d’économie collaborative qui fonctionne via du pair à pair marchand. En effet, les responsables de ruches, qui jouent le rôle d’intermédiaire entre les consommateurs des paniers alimentaires, et les producteurs, sont rémunérés par une commission sur le prix des paniers. Cette commission vise également à réaliser du profit pour faire croître l’entreprise.
C’est une des différences majeures d’ambition entre les Ruches et les AMAP. Cette absence d’intermédiaire dans les AMAP apporte une grande valeur ajoutée à cette structure de circuits courts. Afin de garantir la fiabilité et la sécurité de cette vision, les AMAP sont régies par une charte des AMAP, exigeante et pertinente pour former une communauté de consommateurs engagés et désireux d’adopter une alimentation saine, locale et durable. Cette charte assure la fluidité entre ses adhérents et les producteurs, et garantit le respect des deux parties de leurs engagements mutuels.
La stratégie de La Ruche Qui Dit Oui a été de rendre plus flexible et à la demande le système des AMAP, en permettant aux consommateurs d’éviter un engagement trop fort et à long terme, ainsi que des achats ponctuels s’il le souhaite. On peut ainsi considérer que LRQDO “uberise” les AMAP. Néanmoins, les prix sont relativement similaires entre les Ruches et les AMAP donc c’est une « uberisation » qui n’agit pas sur la baisse des prix mais principalement sur la rapidité, le choix et la flexibilité de l’offre pour les consommateurs. Ce sont donc les producteurs qui en périssent puisque leurs revenus sont plus faibles afin de rémunérer les intermédiaires dans la structure des Ruches tout en garantissant un prix des paniers compétitif par rapport aux AMAP. C’est pourquoi plusieurs AMAP ont protesté contre le système des Ruches qui place les petits producteurs dans une situation encore plus précaire. Cela coïncide avec leur ambition de protection des producteurs, de proximité consommateurs-producteurs et de valorisation d’une alimentation saine, locale et durable.
Ce sont les principaux ‘key assets’ des AMAP, protégés par la charte des AMAP [13], qui rendent la proposition de valeur de la structure difficile à imiter et à concurrencer : les Ruches s’adressent en effet à un public différent, que les AMAP ne souhaitent pas conquérir si pour cela, un assouplissement de la charte est nécessaire. L’engagement des consommateurs nécessaire au bon fonctionnement des AMAP constitue en effet une valeur ajoutée forte qui permet de garantir un lien social et une proximité entre les producteurs et les consommateurs, qu’il n’est pas question d’abandonner, puisqu’au contraire, elle forge une communauté de personnes qui partagent les mêmes idéaux et ambitions.
Dans le cadre de mon étude, et pour aboutir à cette analyse comparative, j’ai décidé de réaliser un tableau de comparaison entre ces deux structures, sur plusieurs aspects de leurs Business Models respectifs : ce tableau est donc disponible en Annexe.
4) Le cas de l’AMAP Penn Ar Bed à Plougonvelin
Dans le cadre de mon étude, j’ai choisi d’étudier une AMAP en particulier : il s’agit de l’AMAP Penn Ar Bed, à Plougonvelin [5].
J’ai choisi cette AMAP, d’abord pour une question de proximité, afin de pouvoir me rendre sur place, ce qui n’a malheureusement pas pu avoir lieu à cause des conditions sanitaires ces derniers mois. Sa position géographique, en Bretagne, dans une zone peu urbanisée est également intéressante à étudier pour comparer les effets de cette localisation sur l’organisation et le Business Model de cette association par rapport à d’autres AMAP, situées dans des régions très urbanisées, en région parisienne par exemple. Autre que le contraste géographique, les similarités et différences entre certaines AMAP peuvent être liées à la catégorie socio-professionnelle de la population autour de la localisation de l’AMAP. Plougonvelin, banlieue riche de Brest, regroupe ainsi une population de catégorie socio-professionnelle élevée, comme peuvent l’être les cibles des AMAP parisiennes. Comparer ces structures peut donc nous permettre de trouver des liens entre l’urbanisation et/ou la catégorie socio-professionnelle, et les motivations des consommateurs amapiens.
Une des particularités de cette AMAP qui m’a intriguée aussi, est sa méthode de création puisqu’elle est née en 2013 de l’initiative d’un collectif local, le collectif Tamm-ha-Tamm [14]. Cela lui permet de bénéficier de l’expertise de personnes engagées sur des questions sociales et environnementales locales et également de se lancer au sein d’un réseau déjà existant, un véritable atout pour toute nouvelle structure qui s’implante. Le collectif avait déjà réfléchi à la mise en place d’une structure pour fournir des paniers alimentaires sains et locaux à ses habitants mais n’avait pas décidé sur le type de structure à mettre en place. C’est la rencontre avec le maraîcher, en reconversion professionnelle, qui a repris les terres familiales, que le choix de l’AMAP est venu. L’objectif principal était pour le maraîcher de tester un système de panier, pour déterminer les quantités à produire, et perfectionner ses connaissances techniques sur les cultures, tout en misant sur une structure respectueuse de l’environnement, locale et valorisant les produits bio.
C’est une structure qui peut faire peur aux producteurs au début, comme ça a été le cas pour la laitière dans l’AMAP Penn Ar Bed, puisque le modèle est peu connu dans le milieu agricole. La laitière, qui vendait initialement uniquement au marché de Kerinou à Brest a hésité à rejoindre par appréhension de bousculer sa routine et par crainte qu’elle soit déstabilisée, mais finalement le concept d’avoir une trésorerie à l’avance pour les producteurs et le lien social lui ont particulièrement plu et elle voudrait même rejoindre d’autres AMAP du Finistère, comme me l’a indiqué la Présidente de l’AMAP Penn Ar Bed, Karine Boennec, avec qui j’ai eu l’occasion d’échanger par téléphone, le 8 décembre dernier, dans le cadre de ma démarche d’étude, présentée précédemment.
L’AMAP Penn Ar Bed à Plougonvelin regroupe 8 producteurs (maraîcher, laitière, boucher, apiculteur, producteur d’herbe aromatiques et médicinales, brasseur, boulanger, productrice de légumes lactofermentés) et un groupe de 65 adhérents, appelés les amapiens : chaque adhérent rassemble plusieurs consommateurs, comme sa famille ou ses amis par exemple, puisque les paniers sont de quantité suffisante pour plusieurs personnes.
Comme nous l’avons détaillé précédemment, les principales propositions de valeur des AMAP, et notamment l’AMAP Penn Ar Bed, résident dans la proximité et le lien social fort entre les consommateurs et les petits producteurs locaux qui souhaitent, ensemble, promouvoir et s’engager pour une alimentation saine, durable et locale. Nous allons dans les parties suivantes détailler l’étude du Business Model de l’AMAP Penn Ar Bed dont le résumé schématique est disponible en annexe.
III – Structure des coûts de l’AMAP Penn Ar Bed
1) Activités Clés
L’activité principale des AMAP concerne la distribution hebdomadaire des paniers de nourriture bio, locale et saine. Ces distributions peuvent s’effectuer dans des lieux publics mis à disposition au profit de l’AMAP ou dans les lieux choisis par l’AMAP pour assurer une distribution fluide, chaleureuse et conviviale. Dans le cas de l’AMAP Penn Ar Bed, la distribution s’effectue par exemple proche de la Pointe Saint Mathieu, puisque c’est là où se situe la production du maraîcher, à l’initiative de la création de l’AMAP. C’est un lieu emblématique du Finistère, par ses paysages, ses chemins de randonnées et sa vue sur toute la baie de Brest.
Des visites de la ferme du maraîcher peuvent également être organisées au moment des distributions, ce qui enchante les familles venues avec leurs enfants. L’AMAP Penn Ar Bed veille en effet à garantir le lien social fort entre les amapiens et les producteurs grâce à des événements pour faire découvrir le milieu agricole aux consommateurs. L’échange et le partage, tant via des discussions autour de connaissances ou bonnes pratiques, que via de l’aide manuelle ou organisationnelle pour les producteurs, sont au cœur des activités clés de l’AMAP Penn Ar Bed.
Cette AMAP, comme de nombreuses autres, cherchent de plus en plus à promouvoir une agriculture respectueuse de l’environnement, en tendant au maximum vers des productions biologiques. En milieu peu urbanisé, on peut néanmoins leur reprocher de ne pas considérer l’impact environnemental dans sa globalité, à savoir les déplacements en voiture pour se rendre sur le lieu des distributions, excentré du centre-ville. C’est un des avantages des AMAP en milieu urbain, par rapport à Penn Ar Bed, ainsi que d’autres AMAP qui ont privilégié une localisation publique, comme une école par exemple, ce qui permet aux habitants de venir récupérer leur panier alimentaire en même temps que leurs enfants par exemple. Les AMAP, grâce à leur charte et leur engagement, visent à inviter les habitants locaux à changer leur mode de consommation, via l’alimentation, et cela fait partie de leur proposition de valeur. Avec un peu d’optimisme, on peut imaginer que, via une sensibilisation aux enjeux liés à l’activité humaine, cela pourra avoir une influence à plus long terme sur les comportements des consommateurs, dans d’autres secteurs, que ce soit le logement, le textile, ou les mobilités.
2) Ressources Clés
La principale force de la structure d’AMAP par rapport à ses principaux concurrents est de bénéficier d’une ressource puissante : l’engagement bénévole de ses consommateurs. Ce sont en effet les groupes de consommateurs qui s’organisent entre eux au sein de l’association pour assurer les distributions et l’organisation interne et externe, avec les producteurs et autres partenaires clés.
Ce temps donné par les amapiens pour l’association est une ressource primordiale pour le bon fonctionnement de la structure ainsi que pour assurer un soutien aux producteurs, qui sont donc plus enclins à privilégier l’AMAP que d’autres structures de distribution. C’est notamment ce qui s’est produit à l’AMAP Penn Ar Bed pendant les confinements successifs. En effet, la demande auprès des producteurs locaux a fortement augmenté par crainte des consommateurs d’aller dans de trop grandes surfaces, et les adhérents à l’AMAP se sont vus prioritaires dans les distributions par rapport aux autres consommateurs, grâce à leur engagement temporel et financier, puisque les paniers sont payés à l’avance sur une durée prédéfinie de 6 mois dans la plupart des cas.
3) Partenaires Clés
Comme nous l’avons vu à plusieurs reprises, les petits producteurs locaux, qui cherchent à s’orienter vers l’agroécologie, la permaculture, les productions biologiques et d’autres initiatives similaires, sont les principaux partenaires de la structure d’AMAP. Dans le cas de Penn Ar Bed, on en dénombre 8 : un maraîcher, une laitière, un boucher, un producteur d’herbes aromatiques et médicinales bio, un apiculteur, un boulanger, un brasseur, ainsi qu’une productrice de légumes lactofermentés. Cela peut concerner des personnes en reconversion professionnelle, comme d’autres qui ont toujours fait ce métier. Financièrement, passer par une AMAP offre la possibilité de ne pas subir les difficultés à obtenir un prêt bancaire en étant aidé pour le lancement de l’activité, par exemple.
Ces partenariats ne sont pas exclusifs : les producteurs vendent leurs produits dans d’autres structures également : cantines scolaires, marchés de plein air et épiceries bio notamment pour les producteurs de l’AMAP Penn Ar Bed.
Dans le cadre de ces partenariats, un système mutualiste est instauré. Lors des Assemblées Générales annuelles, les producteurs et les consommateurs fixent, ensemble, les prix des paniers, justes et équitables pour les deux parties.
Enfin, un rapport de proximité est garanti par ces partenariats, avec un engagement mutuel des deux parties : bénévolat et soutien de la part des consommateurs et compensation des paniers en cas de problème climatique par exemple, de la part des producteurs.
Au cours de notre étude, nous avons pu présenter la place centrale des producteurs dans la structure d’AMAP. Pour éclaircir ce point, il faut retenir que les producteurs ne sont pas des adhérents à l’AMAP : ils ne cotisent pas à l’année et ne sont pas considérés comme des amapiens, qui regroupent uniquement les consommateurs adhérents. Néanmoins, ils sont les partenaires de l’AMAP les plus importants : sans eux, la structure ne pourrait pas exister et il est nécessaire de les mettre au cœur du fonctionnement de l’AMAP pour garantir un lien social fort entre consommateurs et producteurs, via une co-construction du système.
En lien avec cette proximité consommateur-producteur, on distingue également plusieurs réseaux d’AMAP qui visent à mettre en relation les AMAP membres afin d’échanger des bonnes pratiques ou des connaissances par exemple. Le réseau le plus connu est le réseau MIRAMAP (Mouvement Inter-Régional des AMAP) [12] puisqu’il est national. Il vise à mutualiser toutes les démarches des AMAP, à les aider dans leur lancement, leur activité et leur bon fonctionnement. Pour centraliser toutes les données, et principalement les ressources utiles aux AMAP, la plateforme AMAPartage a vu le jour. L’annuaire national des AMAP, http://reseau-amap.org/, recense, quant à lui, toutes les initiatives d’AMAP sur l’ensemble du territoire.
L’AMAP Penn Ar Bed n’est pour l’instant pas très active au sein du réseau MIRAMAP, mais elle a en revanche rejoint récemment le réseau Breizh’AMAP, réseau régional des AMAP de Bretagne, qui regroupe une centaine d’AMAP bretonnes, et planifie de participer et de s’investir dans des événements régionaux via cette structure pour se rapprocher d’autres AMAP voisines, dès que la situation sanitaire le permettra.
Enfin, les AMAP sont, dans certains cas, partenaires d’acteurs publics, notamment le Ministère de l’Agriculture et de l’Alimentation, qui peuvent subventionner de telles initiatives, sous la loi des associations 1901. Toutefois, de nombreuses structures refusent de dépendre de ces subventions pour prôner une évolution vers un modèle autosuffisant : c’est par exemple le choix qu’a fait l’AMAP de Penn Ar Bed.
4) Structure des coûts
En ce qui concerne les coûts liés au fonctionnement de l’AMAP, la principale composante regroupe tous les frais monétaires liés aux diverses productions agricoles : achat des matières premières, des ustensiles et des contenants, maintenance et renouvellement des machines utilisées, salaire des producteurs, etc. Ces coûts sont pris en charge dans le prix des paniers, fixé à l’avance par les producteurs et les consommateurs, afin d’être le plus équitable possible. Les revenus de l’AMAP servent uniquement au bon fonctionnement de l’association et au financement de la communication, du marketing et des événements par exemple.
Un coût non monétaire est également non négligeable puisque les bénévoles, et notamment la présidente de l’association, donnent beaucoup de leur temps pour assurer la gestion interne de l’AMAP : trésorerie, relation avec les partenaires, logistique, communication interne et externe, etc. Il n’y a pas d’intermédiaire entre les producteurs et les consommateurs, donc les coûts monétaires sont minimisés, mais cela implique une nécessité de s’investir en temps pour l’association.
Enfin, en ce qui concerne la communication, les supports utilisés et les événements organisés (stand annuel au forum des associations de Plougonvelin par exemple) nécessitent un investissement financier, mais également temporel.
IV – Structure des revenus de l’AMAP Penn Ar Bed
1) Relation Client
La structure d’AMAP vise, par essence, à rapprocher les producteurs des consommateurs. La relation client est donc au cœur du fonctionnement des AMAP. Contrairement à ses principaux concurrents, comme La Ruche Qui Dit Oui, qui font appel à un intermédiaire, les AMAP se sont débarrassées des intermédiaires entre les producteurs et les consommateurs via la structure associative qui permet de les rassembler. Elle n’agit pas comme une entreprise tierce qui viendrait chercher des consommateurs pour leur vendre les paniers de ses producteurs partenaires mais plutôt comme un groupement qui met les consommateurs au milieu de l’organisation, au plus près des producteurs.
Les contacts entre amapiens et producteurs sont donc très fréquents et rapprochés : lors des distributions hebdomadaires, lors des événements sociaux (visites de fermes, pique-niques collectifs, etc) et également lors des Assemblées Générales annuelles qui rassemblent tout le monde, producteurs comme amapiens, pour faire les bilans annuels, prendre les décisions pour les années suivantes, qu’elles soient financières ou organisationnelles.
En revanche, les consommateurs n’ont pas la possibilité de choisir le contenu des productions. Par exemple, s’il y a des intempéries sur une production, le panier prévu initialement sera modifié avec d’autres aliments du même producteur. La quantité doit rester équivalente mais le panier comportera dans ce cas plus de produits dont les cultures n’auraient pas été endommagées. Le consommateur est informé des différents aliments fournis par les producteurs de l’AMAP, selon la saison (2 contrats par an en général) et il choisit seulement avec quels producteurs il souhaite établir un contrat, mais ne décide pas du contenu des productions. La relation de proximité permet néanmoins de suggérer et d’échanger des idées de nouvelles productions, selon les envies des amapiens et les contraintes (météorologiques, géographiques, etc) des producteurs. Dans le cas de l’AMAP Penn Ar Bed, le contrat avec la boulangère dure seulement 3 mois pour qu’il y ait plus de variété dans les pains distribués aux amapiens, pour éviter qu’ils se lassent et souhaitent acheter leur pain en dehors de l’AMAP.
2) Canaux de Distribution et de Communication
L’AMAP Penn Ar Bed jouit principalement d’un effet de réseau très local et fonctionne notamment grâce au bouche à oreille pour convaincre de nouveaux adhérents de rejoindre le mouvement et la communauté. Cela est lié au principe même et à la volonté des AMAP, qui ne cherche pas à se fondre dans les lois du marché via un marketing poussé. Néanmoins, au contraire de l’AMAP Penn Ar Bed qui ne cherche pas à s’étendre, comme en témoigne sa communication extérieure peu développée, dans des milieux plus urbanisés, on trouve un marketing un peu développé et une communication plus importante, via les réseaux sociaux et les sites internet notamment, afin de conquérir potentiellement de nouveaux segments de clientèle. C’est le cas par exemple, en Île-de-France, où des supports de communication et des logiciels de gestion sont développés puis partagés entre AMAP du réseau régional, contrairement au réseau Breizh’amap qui ne dispose même pas, quant à lui, d’un site internet dédié. Cela peut peut-être s’expliquer par le fait que les AMAP parisiennes cherchent à élargir leur public, notamment grâce à un marketing solide et une application mobile ergonomique et ludique. Cela peut en effet être un point d’entrée efficace pour convaincre les personnes qui ne prennent pas le temps de se renseigner et de transformer leur mode de consommation alimentaire, car à Paris, tout va plus vite, parfois trop vite. Néanmoins, par essence, les AMAP ne souhaitent pas devoir assouplir leur charte pour recruter des consommateurs. Elles misent plutôt sur l’effet de réseau local pour assurer de la visibilité à la structure et ainsi garantir la viabilité du contrat.
Dans l’AMAP Penn Ar Bed, la communication externe s’effectue exclusivement via le site internet vitrine, en version gratuite uniquement, ce qui limite le nombre de publications, de photos en ligne, au regret de la Présidente de l’AMAP qui aimerait pouvoir développer plus cette interface. Il fait office aujourd’hui de flyer et permet également le dépôt des contrats entre les consommateurs et les producteurs.
En interne, la communication s’effectue par mail pour organiser les distributions, les roulements parmi les bénévoles pour les différentes actions internes à assurer. Depuis le confinement, de nouveaux usages de ces mails se sont révélés pertinents afin de compenser la perte de lien social en présentiel. Une lettre hebdomadaire a ainsi été mise en place pour informer les adhérents des nouveautés hebdomadaires de l’association, des questions organisationnelles, et également pour échanger et partager des conseils, bonnes pratiques, recettes ou autres messages pour rester en contact entre amapiens.
3) Segments de clientèle
Selon la typologie effectuée par une enquête PIPAME sur les différentes catégories de consommateurs, les AMAP, et en particulier celle de Plougonvelin, ciblent principalement les ‘engagés’. Ce sont en effet des personnes désireuses d’avoir un impact positif sur l’environnement en adoptant une consommation alimentaire locale et de saison, et dans la mesure du possible, bio mais également en valorisant les petits producteurs locaux : on les appelle des consom’acteurs. La place des amapiens comme consommateurs-bénévoles nécessite un engagement fort dans l’association pour maintenir le fonctionnement de son système mutualiste et sans intermédiaire, où équité, transparence et convivialité sont les maîtres mots.
Dans l’AMAP Penn Ar Bed, on retrouve ainsi beaucoup de familles et de couples de personnes âgées, mais également quelques groupes d’étudiants, d’autant plus depuis le confinement de mars qui les a incités à bousculer leurs habitudes et à remettre en question leur mode de consommation, notamment pour l’alimentation.
Les ‘opportunistes’ peuvent également être attirés par les prix très attractifs des paniers des AMAP, en comparaison aux rayons bio des supermarchés, qui n’hésitent pas à gonfler leurs marges sur ces types de produits. Néanmoins, les prix des paniers des AMAP sont similaires aux prix en vente directe à la ferme ou dans les marchés, donc les ‘opportunistes’ qui souhaitent manger local et bio privilégieront les circuits courts aux rayons bio des supermarchés, sans avoir particulièrement de préférence entre AMAP ou autre circuit court, en terme de prix.
Les ‘idéalistes’, quant à eux, cherchent à avoir un impact positif mais sans nécessité d’engagement, donc ils ne constituent pas un public cible de l’AMAP Penn Ar Bed qui est très attachée à cet engagement de sa communauté pour mettre au premier plan la convivialité, le partage et la vision commune à tous les adhérents en matière d’alimentation durable, locale et saine. Les ‘idéalistes’ sont ainsi ciblés plus particulièrement par La Ruche Qui Dit Oui, principal concurrent des AMAP, qui a opté pour un système avec intermédiaire et plus flexible, tout en conservant une volonté d’avoir un impact environnemental et social.
4) Flux de revenus
Les AMAP sont des associations loi 1901 à but non lucratif, donc ces structures ne cherchent pas à faire du profit pour se pérenniser.
La principale source de revenu regroupe les paiements par les consommateurs des contrats longue durée (semestriel ou annuel). Comme nous l’avons vu précédemment, ces prix sont fixés équitablement en accord entre producteurs et consommateurs donc ils permettent de financer tout ce qui est lié aux productions agricoles et aux salaires des producteurs.
Pour mener des projets d’ampleur, tel que l’achat de nouvelles terres agricoles par exemple, les AMAP peuvent faire appel à des subventions publiques du ministère de l’agriculture. Néanmoins, ce n’est pas le cas de toutes les AMAP. En effet, l’AMAP Penn Ar Bed ne souhaite pas dépendre de telles subventions donc elle a choisi de ne pas en demander. Cela est en accord avec la volonté de s’approcher de l’autosuffisance de l’AMAP.
L’AMAP Penn Ar Bed a donc décidé de mettre en place une cotisation annuelle de 10€ pour chaque amapien afin de subvenir aux besoins organisationnels de l’association et également pour faire face à d’éventuels imprévus, comme une perte d’une partie des cultures agricoles à cause de maladies, plantes invasives, catastrophe climatique, etc.
Enfin, l’investissement en tant que bénévoles de tous les adhérents constitue une source de revenu non monétaire non négligeable puisqu’elle permet d’assurer le bon fonctionnement de l’association et également d’être en mesure d’apporter de l’aide et du soutien aux producteurs.
Conclusion
Ainsi, la réalisation de cette étude a permis de mettre en lumière la valeur ajoutée des AMAP, et en particulier l’AMAP Penn Ar Bed de Plougonvelin, parmi les alternatives de circuits courts pour avoir une alimentation saine, locale et durable. Les avantages de ces structures peuvent se regrouper selon les 3 axes : écologiquement sain, socialement équitable et économiquement viable. Voici ci-dessous, pour synthétiser, la matrice SWOT de l’AMAP Penn Ar Bed.
Opportunités
Menaces
– volonté de consommer local et bio -questions environnementales de plus en plus prises en compte – développement du réseau régional Breizh’amap
– dérèglement climatique – difficultés pour passer à l’échelle – perte de lien social liée au confinement
Forces
Faiblesses
– mise en valeur des circuits courts – solidarité producteurs-consommateurs et fort lien social (système mutualiste) – prix équitable et abordable – valorisation d’une communauté engagée et animée d’une vision commune (bénéfice d’un réseau déjà existant puisque l’AMAP a été créée par un collectif de Plougonvelin, responsable de nombreuses actions sociales)
– contraintes d’engagement long terme (semestre ou année) du consommateur ne visent qu’une petite partie de la population sans chercher à s’étendre – peu d’échanges avec d’autres AMAP pour le moment
En définitive, cette étude a permis de révéler le positionnement des AMAP vis-à-vis de sa concurrence au sein de l’écosystème du secteur agricole et des circuits courts. L’étude détaillée du Business Model a mis en lumière la forte valeur ajoutée de la structure d’AMAP, qui, d’ailleurs, prend de l’ampleur en terme de nombre de structures et d’adhérents, sur le territoire français, à l’instar de nombreuses plateformes d’économie collaborative, sans doute en lien avec la récente prise de conscience collective de mettre au premier plan la solidarité et le respect de l’environnement.
Annexes
Tableau comparatif entre l’AMAP et La Ruche qui dit oui (LRQDO)
Critère
AMAP
LRQDO
Type de structure
Association
Entreprise
Type de système
Pas de système marchand (les consommateurs sont bénévoles, participent à la fixation des prix etc.)
Système marchand
Implication des parties prenantes
Engagement fort du consommateur et des producteurs
Accès ponctuel possible, pas d’engagement particulier du consommateur
Revenu
L’intégralité du prix revient au producteur
Commission gardée sur le prix de 16,7% (équitablement partagée entre l’entreprise et le responsable de ruche), prix fixé par le producteur
Type de vente
Paiement annuel / semestriel encaissé au fur et à mesure donc pas de vente à proprement parler : les paniers sont remis en présence des producteurs en direct et avec des moments d’échanges
Vente directe (via la plateforme) : pas d’intermédiaire qui implique une baisse du coût de revient d’un côté
Perspective d’évolution
Pas de passage à l’échelle si cela nécessite un assouplissement de la charte Pas une mode mais bien une lame de fond
Passage à l’échelle envisagé et déjà entamé avec création de nouveaux emplois, recherche de nouveaux inscrits
Communication
Faible communication et peu adaptée aux réseaux actuels et aux modes de consommation actuels (1 site vitrine au design peu attractif, faible utilisation de l’effet de réseau via les réseaux sociaux)
Communication forte et pertinente : site internet, réseaux sociaux → adaptée aux jeunes générations
[2] Voir le graphique en Annexe 1 – Étude de l’INSEE sur les dépenses de consommation alimentaire des ménages de 1960 à 2014, parue le 9/10/2015, https://www.insee.fr/fr/statistiques/1379769



/images/image7.png)